image:
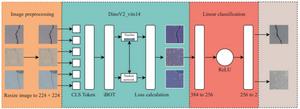
Overview of the proposed framework.
view more
Credit: Machine Intelligence Research
New research shows that self-monitoring artificial intelligence may provide a more practical way to detect concrete cracks in real-world structures. Instead of relying heavily on large, carefully labeled image datasets, the researchers used DinoV2 to learn rich visual features from images and combined them with a lightweight linear classifier for crack recognition. The system performed well across multiple public datasets and showed particular benefits in noisy scenes, various material textures, and unbalanced data conditions. The findings suggest that self-supervised vision models could help make structural inspection faster, more reliable, and reduce reliance on costly manual data annotation.
Crack detection is central to structural health monitoring because missed damage can threaten the safety and longevity of bridges, buildings, and other infrastructure. Traditional manual inspection is time-consuming, labor-intensive, and susceptible to human error, while many deep learning approaches require large amounts of labeled data and often struggle to generalize when cracks occur under unfamiliar conditions, such as different surface textures, lighting, and background noise. Class imbalance is also a major problem, as the number of non-crack regions usually far exceeds the actual cracks. Based on these challenges, there is a strong need for deeper research into crack detection methods that can maintain accuracy, robustness, and adaptability across diverse real-world datasets.
Researchers from the University of Technology Sydney, American University of Beirut, Chinese Academy of Sciences and Western Sydney University in February 2026. Machine intelligence research A self-supervised DinoV2-based framework can detect concrete cracks with high accuracy and generalization across datasets, outperforming several widely used supervised deep learning models in difficult inspection scenarios.
The team evaluated four public crack image datasets (CCiC, Xu, HBC2019, SDNET2018) covering different materials, backgrounds, and degrees of class imbalance. Their framework resized the image to 224 × 224, used a pretrained DinoV2_vits14 model to extract the visual representation, and passed the features to a two-layer linear classification head. DinoV2 was trained for only 5 epochs, while five supervised baselines (ResNet50, ResNet101, VGG16, MobileNetV2, DenseNet121, and one self-supervised baseline MoCo v2) were trained from scratch under standardized settings for comparison. In testing on the same dataset, DinoV2 gave the best results on the Xu, HBC2019, and SDNET2018 datasets. This includes perfect recall on Xu, F1 score of 0.9346 and precision of 0.9731 on HBC2019, and best precision of 0.9416 on SDNET2018. DinoV2 was also consistently strong in cross-dataset testing, often leading in accuracy and F1 score when the model was trained on one dataset and tested on other datasets. These results suggest that DinoV2 is able to capture more transferable crack features than traditional supervised models, especially when faced with noisy backgrounds and previously unseen data.
This study positions self-supervised learning as more than a technological trend. Self-supervised learning has the potential to solve one of the most stubborn problems in structural monitoring: the lack of broadly representative labeled data. The authors argue that the strength of DinoV2 lies in its ability to learn general image features before task-specific classification, and maintain sensitivity to crack patterns even when the data is complex, noisy, and unbalanced. This is important because in safety-critical inspections, a missed crack can have far greater consequences than a false alarm.
Its impact extends beyond benchmark performance. Crack detection systems that reduce the need for manual labeling and are better generalizable across materials and environments could support more scalable inspections of bridges, pavements, walls, and aging buildings. Such tools could help move structural monitoring from labor-intensive visual checks to faster, more autonomous workflows. The results also point to broader opportunities. Self-supervised vision models can become valuable feature engines for engineering diagnostics in environments where labeled data is scarce but reliability is essential. This not only makes future infrastructure assessments more efficient, but also has the potential to further increase field resiliency and deployability.
###
References
Toi
10.1007/s11633-025-1553-5
Original source URL
https://doi.org/10.1007/s11633-025-1553-5
Funding information
Open access funding enabled and organized by CAUL and its member institutions.
About Machine intelligence research
Machine intelligence research The International Journal of Automation and Computing is published by Springer and sponsored by the Institute of Automation, Chinese Academy of Sciences. The journal publishes high-quality articles on original theoretical and experimental research, targets special issues on emerging topics, and strives to bridge the gap between theoretical research and practical applications.
journal
Machine intelligence research
Research theme
not applicable
Article title
Autonomous detection of concrete cracks using self-monitoring DinoV2
Article publication date
February 2, 2026
Conflict of interest statement
The authors declare that they have no competing interests.
Disclaimer: AAAS and EurekAlert! We are not responsible for the accuracy of news releases posted on EurekAlert! Use of Information by Contributing Institutions or via the EurekAlert System.


