
Companies across industries face a common challenge: how to efficiently extract valuable information from vast amounts of unstructured data. Traditional approaches often involve resource-intensive processes and inflexible models. This post introduces an innovative solution. Claude Tool, used by Amazon Bedrock, harnesses the power of large-scale language models (LLMs) to perform dynamic, adaptive entity recognition without extensive setup or training.
In this post, we will discuss:
- What is the use of Claude Tool (function call) and how does it work?
- The Claude Tool usage is used to extract structured data using natural language prompts.
- Set up a serverless pipeline using Amazon Bedrock, AWS Lambda, and Amazon Simple Storage Service (S3)
- Implement dynamic entity extraction for different types of documents
- Deploy production-ready solutions following AWS best practices
What is the usage of the load tool (function call)?
Using Claude tools (also known as function calls) is a powerful feature that allows you to enhance Claude’s capabilities by establishing and calling external functions or tools. This feature enhances its functionality by providing Claude with a collection of pre-established tools that can be accessed and used as needed.
How using Claude Tool works with Amazon Bedrock
Amazon Bedrock is a fully managed generative artificial intelligence (AI) service that offers a variety of high-performance foundational models (FM) from industry leaders such as Anthropic. Amazon Bedrock makes implementing Claude’s tools extremely easy.
- Users define a set of tools such as name, input schema, and description.
- Provides user prompts that require the use of one or more tools.
- Claude evaluates the prompt and determines whether there are any tools that can help address the user’s question or task.
- If applicable, Claude chooses which tool to use with which input.
Solution overview
This post shows you how to extract custom fields from a driver’s license using the Claude Tool with Amazon Bedrock. This serverless solution processes documents in real-time and extracts information such as names, dates, and addresses without traditional model training.
architecture
Our custom entity recognition solution uses serverless architecture to efficiently process documents and uses Amazon Bedrock’s Claude model to extract relevant information. This approach minimizes the need for complex infrastructure management and provides scalable, on-demand processing capabilities.
The solution architecture uses multiple AWS services to create a seamless pipeline. Here’s how the process works:
- User uploads document to Amazon S3 for processing
- S3 PUT event notification triggers AWS Lambda function
- Lambda processes the document and sends it to Amazon Bedrock.
- Amazon Bedrock calls Anthropic Claude for entity extraction
- Results are logged to Amazon CloudWatch for monitoring
The following diagram shows how these services work together.
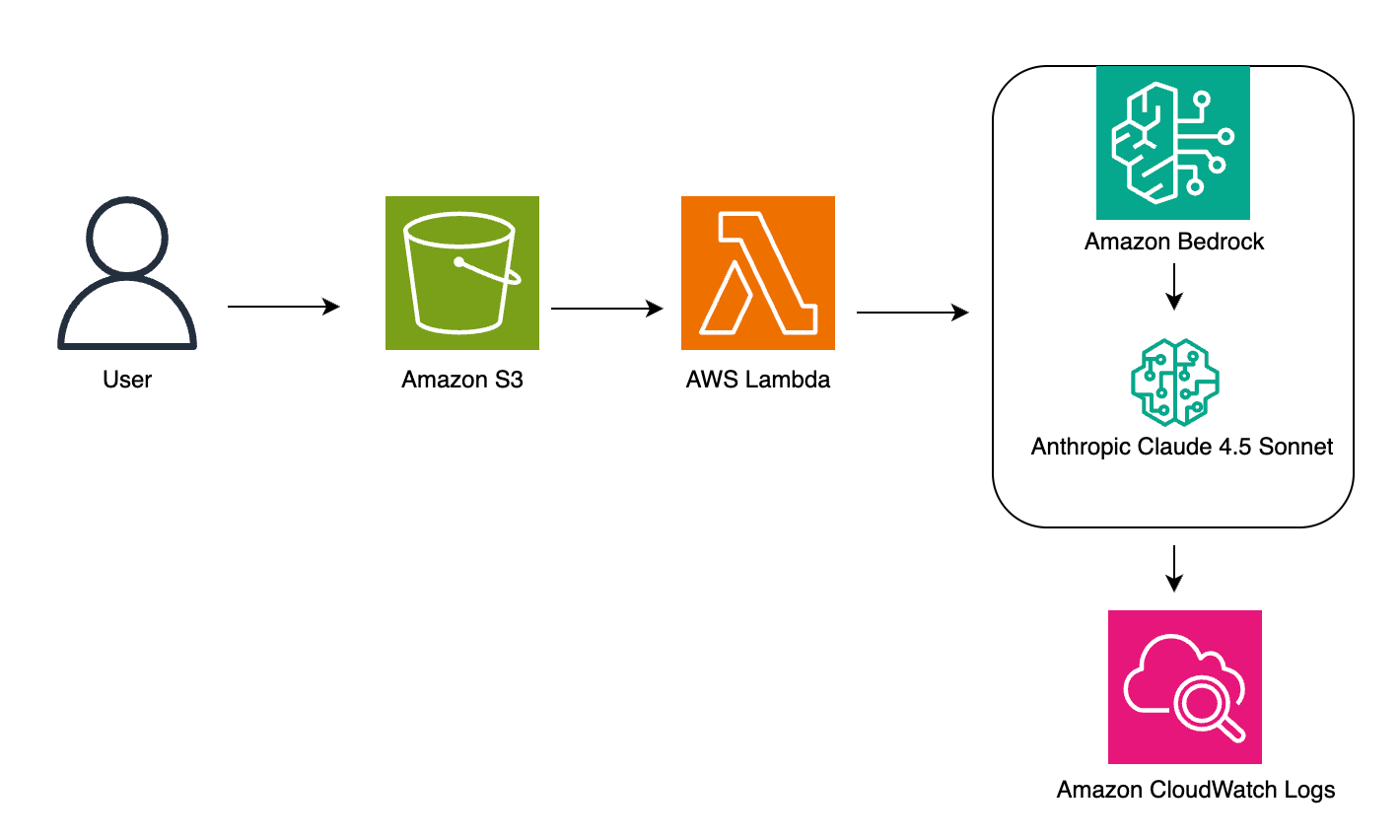
architecture components
- Amazon S3: Save the input document
- AWS Lambda: triggers a file upload, sends the prompt and data to Claude, and saves the results
- Amazon Bedrock (Claude): Process input and extract entities
- Amazon CloudWatch: Monitor and record workflow performance.
Prerequisites
Step-by-step implementation guide:
This implementation guide explains how to build a serverless document processing solution using Amazon Bedrock and related AWS services. By following these steps, you can create a system that automatically extracts information from documents such as driver’s licenses, avoiding manual data entry and reducing processing time. Whether you’re processing a few documents or thousands, this solution automatically scales to meet your needs while maintaining consistent data extraction accuracy.
- Setting up the environment (10 minutes)
- Create a source S3 bucket for input (for example, driver-license-input).
- Configure IAM roles and permissions.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:*::foundation-model/*", "arn:aws:bedrock:*:111122223333:inference-profile/*”
},
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::amzn-s3-demo-bucket/*"
}
]
}- Create a Lambda function (30 minutes)
This Lambda function is automatically triggered when a new image is uploaded to your S3 bucket. Read the image, base64 encode it, and send it to Claude 4.5 Sonnet via Amazon Bedrock using the tool usage API. This function defines a single tool called . Extract license field For demonstration purposes. However, you can define the tool name and schema based on your use case, such as extracting insurance card data, ID badges, or business forms. Claude dynamically chooses whether to invoke the tool based on prompt relevance and input structure.
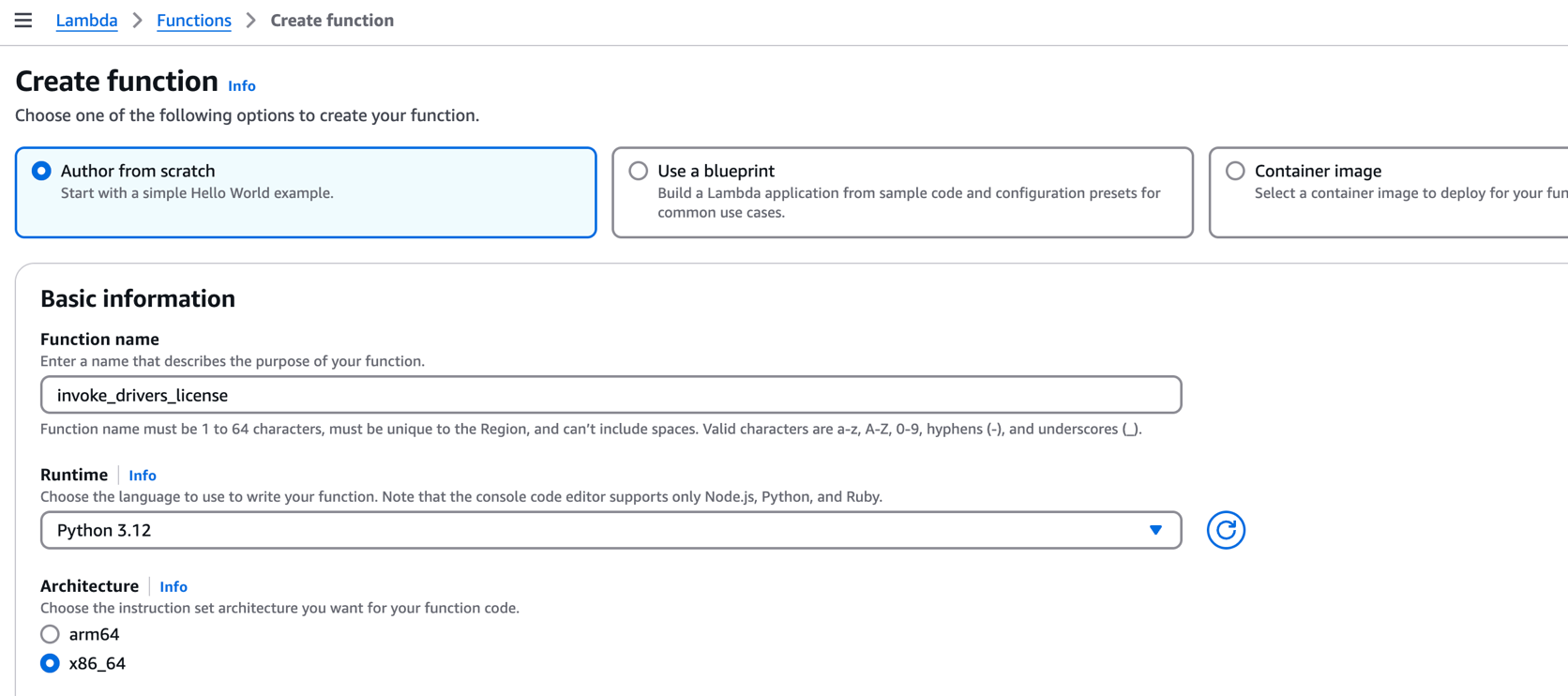
what we use is “tool_choice”: “Auto” Let Claude decide when to call the function. For production use cases, it can also be hard-coded. “tool_choice”: { “type”: “tool”, “name”: “your_tool_name” } For decisive action.- Go to the AWS Lambda console
- choose Create a function.
- choice Author from scratch.
- Set the runtime as follows Python3.12.
- choose Create a function.
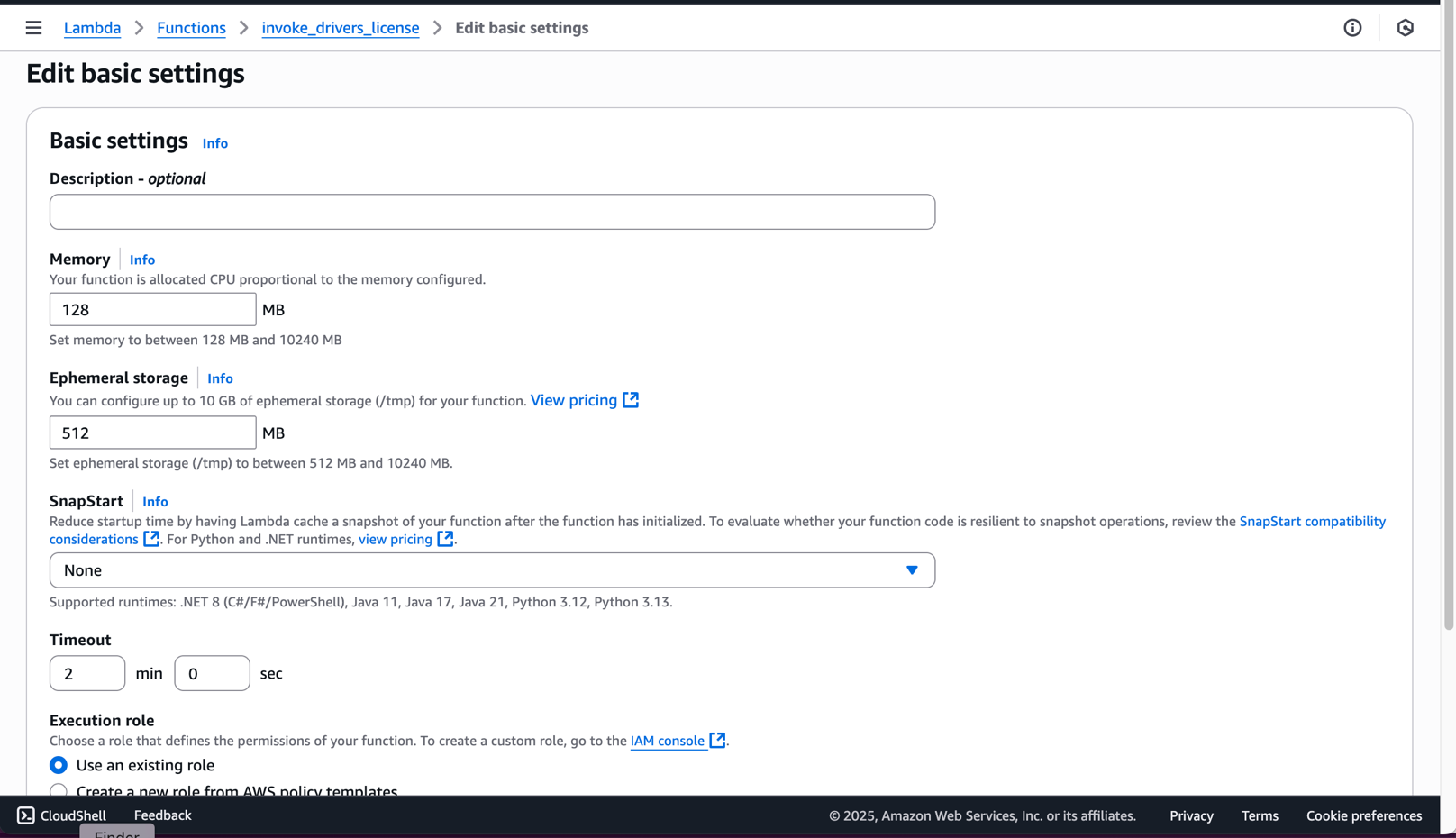
- Configuring Lambda timeouts
- In the Lambda function settings, Common configuration tab.
- under Common configurationclick edit
- for timeoutincrease from the default 3 seconds to at least 30 seconds. For large images, we recommend setting it to 1-2 minutes.
- choose keep.
Note:
This adjustment is very important because Claude’s processing of images can take longer than Lambda’s default timeouts, especially when processing high-resolution images or multiple fields. Monitor function execution time in CloudWatch Logs to fine-tune this configuration for your specific use case.
- this code lambda function.py Code file:
- Deploy the Lambda function: After pasting the code, expand Click the button on the left side of the code editor and wait until you see the deployment confirmation message.
important: Always remember to deploy your code after making changes. This ensures that your latest code is saved and executed when your Lambda function is triggered.
- Go to the AWS Lambda console
- Using Claude toolsWorking with schemas
- Amazon Bedrock and Claude 4.5 Sonnet support calling functions using tooling. Tool Usage defines callable tools with a clear JSON schema. A valid tool entry must include:
- name: Tool identifier (e.g.
extract_license_fields) - Input schema: JSON Schema that defines required fields, types, and structures
- name: Tool identifier (e.g.
- Example of tool usage definition:
- Multiple tools can be defined. tool array. Claude chooses one (or none) depending on the situation. Select tools The value and how closely the prompt matches a particular schema.
- Amazon Bedrock and Claude 4.5 Sonnet support calling functions using tooling. Tool Usage defines callable tools with a clear JSON schema. A valid tool entry must include:
- Configuring S3 event notifications (5 minutes)
- Open the Amazon S3 console.
- Select your S3 bucket.
- Click. properties tab.
- Scroll down and Event announcement.
- click Create an event notification.
- Enter a name for your notification (for example, “LambdaTrigger”).
- under Event typeselect put.
- under destinationselect Lambda function.
- Select your Lambda function from the dropdown.
- click Save your changes.
- Open the Amazon S3 console.
- Testing and validation (15 minutes)
- Supported formats: Claude 4.5 supports image input in JPEG, PNG, WebP, and single-frame GIF formats. Note: This implementation currently only supports .jpeg You can extend support for other formats by editing images. media type Use fields in your Lambda function to match the MIME type of the uploaded file.
- Size and resolution limitations:
- Maximum image size: 20 MB
- Recommended resolution: 300 DPI or higher
- Maximum dimensions: 4096 x 4096 pixels
- Images larger than this may fail to process or produce inaccurate results.
- Preprocessing tips to increase accuracy:
- Tightly crop your images to remove noise and extraneous parts.
- Adjust contrast and brightness to make sure your text is clearly readable.
- Straightens the scan so that the text is horizontally aligned.
- Avoid low-resolution screenshots or images with large compression artifacts.
- For maximum OCR clarity, we recommend a white background and dark text.
- Upload test image:

- Open your S3 bucket
- Upload an image of your driver’s license (supported formats: .jpeg, .jpg).
- Note: For best results, make sure the image is clear and easy to read.
- Monitor CloudWatch logs
- Go to the Amazon CloudWatch console.
- Please click log group In the left navigation.
- Find your Lambda function name
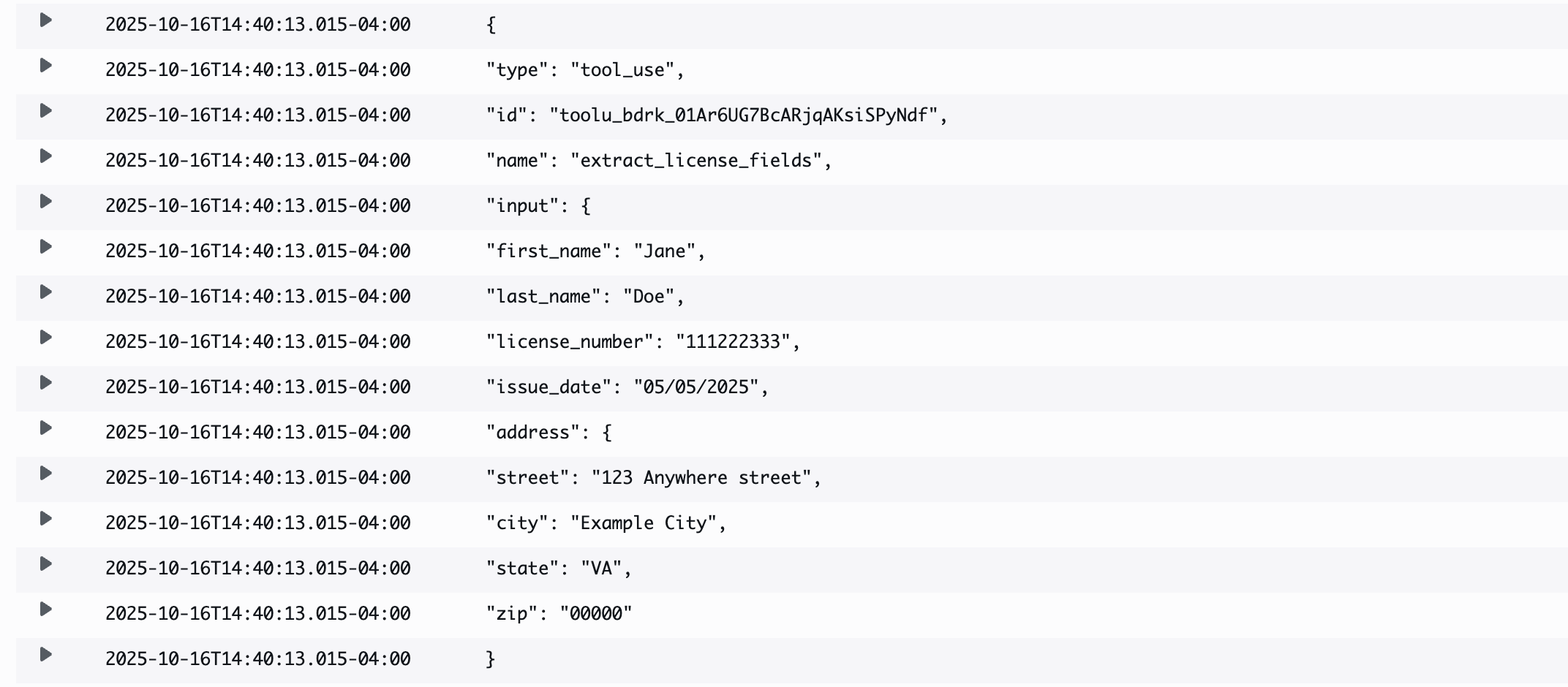
invoke_drivers_license. - Click on the latest log stream (sorted by timestamp).
- Display the execution results. The following sample output is displayed.
Performance optimization
- Configure Lambda memory and timeout settings
- Implement batch processing of multiple documents
- Use S3 event notifications for automated processing
- Add CloudWatch metrics for monitoring
Security best practices
- Implement encryption at rest for S3 buckets
- Use AWS Key Management Service (KMS) keys for sensitive data
- Apply least privilege IAM policy
- Enable a Virtual Private Cloud (VPC) endpoint for private network access
Error handling and monitoring
- Claude’s output is structured as a list of content blocks and may include text responses. tool callor other data types. To debug:
- Always record live responses from Claude.
- Please check if
tool_callsis present in the response. - Use try-excel blocks around function calls to detect errors such as malformed payloads or model timeouts.
- The minimal error handling pattern is:
cleaning
- Delete the S3 bucket and content.
- Delete the Lambda function.
- Delete the IAM role and policy.
- Disable Bedrock access if you no longer need it.
conclusion
Using Claude Tool with Amazon Bedrock provides a powerful solution for custom entity extraction and minimizes the need for complex machine learning (ML) models. This serverless architecture enables scalable and cost-effective document processing with minimal setup and maintenance. By harnessing the power of language models at scale through Amazon Bedrock, organizations can achieve new levels of efficiency, insight, and innovation in processing unstructured data.
next step
We encourage you to explore this solution further by implementing the sample code in your environment and customizing it for your specific use case. Join the discussion about entity extraction solutions in the AWS re:Post community to share your experiences and learn from other developers.
For deeper technical insights, see our comprehensive documentation on Amazon Bedrock, AWS Lambda, and Amazon S3. Consider enhancing your implementation by integrating with Amazon Textract for additional document processing features and Amazon Comprehend for advanced text analysis. To stay up to date on similar solutions, subscribe to the AWS Machine Learning blog and explore other examples in the AWS Samples GitHub repository. If you’re new to AWS machine learning services, check out AWS Machine Learning University or explore the AWS Solutions Library. For enterprise solutions and support, please contact us through your AWS account team.
About the author

