


Although modern multimodal infrastructure models are widely used, they tend to separate the different modalities, typically using specific encoders or decoders for each. This approach limits the ability to effectively fuse information across modalities and create multimodal documents containing diverse sequences of images and text. As a result, the ability to seamlessly integrate different types of content within a single document is limited.
Meta-researchers present Chameleon, a mixed-modal foundational model. It facilitates generation and inference with interleaved text and image sequences, enabling comprehensive multimodal document modeling. Unlike traditional models, Chameleon employs a unified architecture that treats both modalities equally by tokenizing images that resemble text. This approach, called early fusion, allows for seamless inference between modalities but poses optimization challenges. To address these, researchers have proposed architectural enhancements and training techniques. By adapting the transformer architecture and fine-tuning strategy.

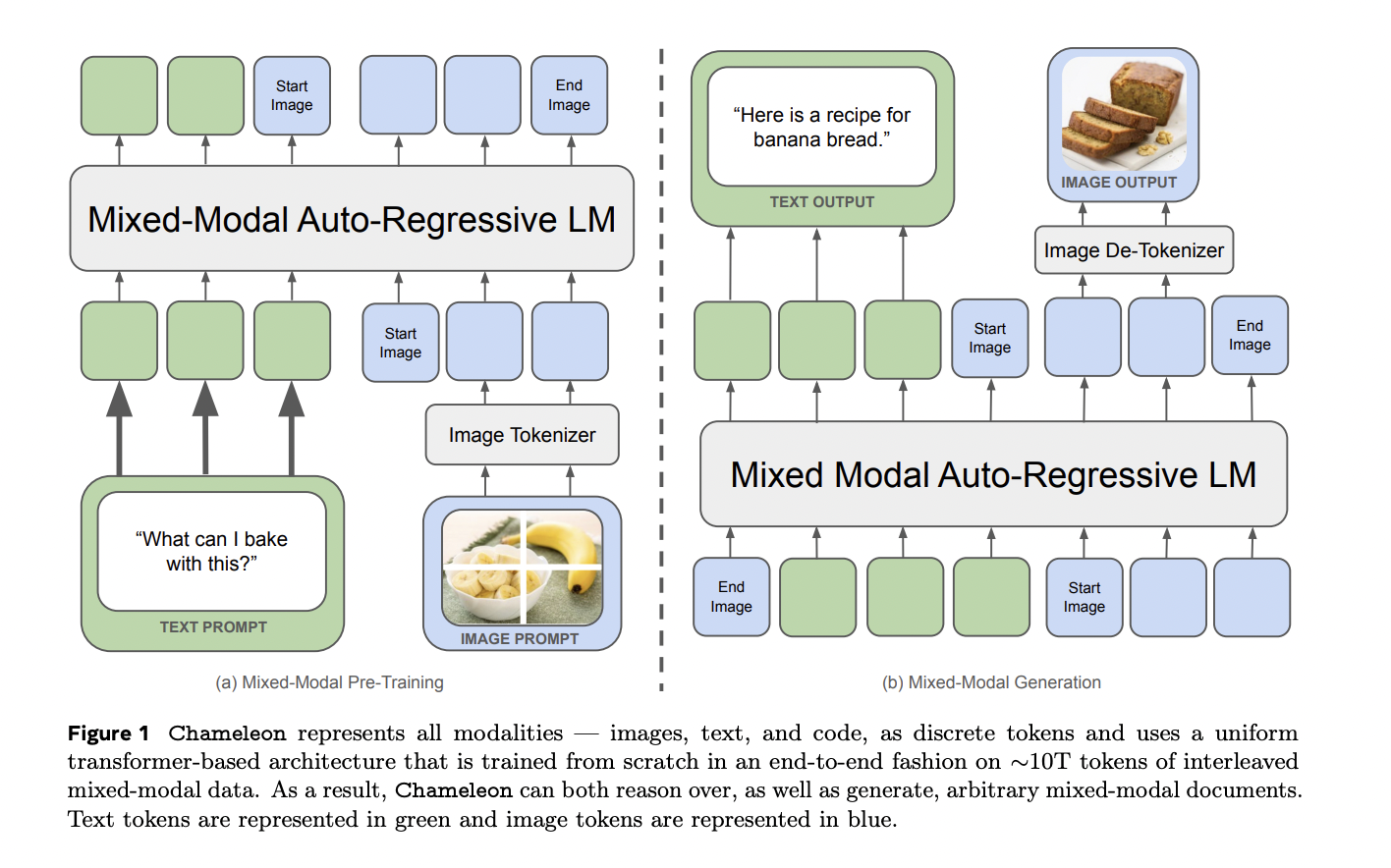
Researchers have developed a new image tokenizer that encodes a 512 × 512 image into 1024 tokens from an 8192 codebook. We focus on licensed images and double the images containing faces during pre-training. However, their tokenizer struggles to reconstruct text-heavy images. We also trained a BPE tokenizer with a vocabulary of 65,536 including image tokens using the Sentence Pieces library on a subset of the training data. Chameleon addressed stability issues with his QK-Norm, dropout, and Z-loss regularization during training, facilitating Meta's successful training with his RSC. Streamline the inference process for mixed modal generation using PyTorch and xformers, supporting both streaming and non-streaming modes using token masking for conditional logic.
The alignment phase involves fine-tuning various datasets, including text, code, visual chat, and safety, with the goal of enhancing the functionality and safety of the model. They use aesthetic classifiers to curate high-quality images for image generation. Supervised fine-tuning (SFT) involves data balancing between modalities using a cosine learning rate schedule and weight decay of 0.1. Each instance of the SFT pair prompts the corresponding answer and optimizes based only on the latter. A dropout of 0.05 is applied along with Z-loss regularization. Images in prompts are resized using border padding, while images in answers are center-cropped to produce high-quality images.
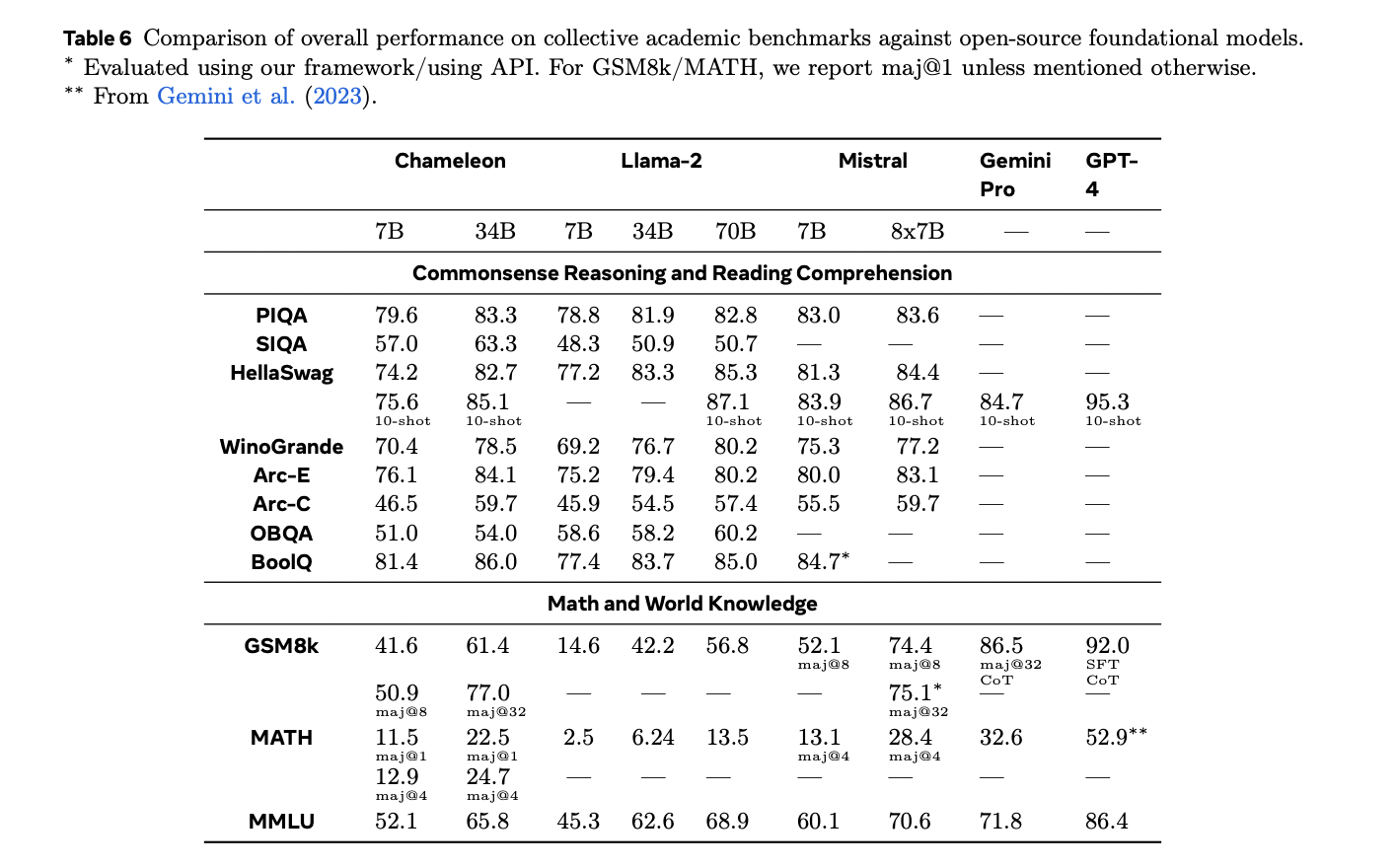
Chameleon evaluates text-only features against state-of-the-art models and achieves competitive performance across a variety of tasks, including common-sense reasoning and mathematics. It performs better than LLaMa-2 on many tasks, likely due to improved pre-training and code data incorporation. For image-to-text tasks, Chameleon excels at image captioning, and with fewer shots he matches or outperforms larger models such as Flamingo-80B and IDEFICS-80B. In visual question answering (VQA), Llava-1.5 slightly outperforms his VQA-v2, but approaches the performance of top models. Chameleon's versatility and efficiency make it competitive across a variety of tasks and require fewer training samples and model sizes.

In summary, this study introduces Chameleon, a token-based model that achieves superior performance in visual language tasks by seamlessly integrating image and text tokens. Its architecture enables collaborative inference across modalities and outperforms late fusion models such as Flamingo and IDEFICS on tasks such as image captioning and visual question answering. Chameleon's early fusion approach introduces new techniques for stable training and addresses previous scalability challenges. This unlocks new multimodal interaction possibilities, as evidenced by its superior performance in mixed-mode open-ended QA benchmarks.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 42,000+ ML subreddits


Asjad is an intern consultant at Marktechpost. He is pursuing a degree in mechanical engineering from the Indian Institute of Technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast and is constantly researching the applications of machine learning in healthcare.


