
Research Group
The current study utilized data from 139,595 participants enrolled in the MCS, the largest and longest-term cohort study of current and former U.S. service members who began (but not completed) the survey in the most recent survey cycle (2019–2021). Individuals enrolled in this study were randomly selected from active duty, reserves, and Department of Defense Department to complete the baseline survey on any of five panels (2001–2003, 2004-2003, 2007-2008, 2013–2013-2013-2013, 2020-2021). During the most recent data collection period, 80,986 panels 1-4 participants completed a paper or web-based survey between August 2019 and August 2021, with 58,609 panel five participants enrolled and invited to complete a web-based baseline survey between September 2020 and August 2021. This study did not exclude participants based on missing survey data. The research protocol and investigation was approved by the Naval Health Research Center Institutional Review Board (Protocol NHRC.2000.0007). All participants in this study provided written informed consent at study registration.
countermeasure
Demographic characteristics
Demographics (i.e., birth, age, race and ethnic gender) and military characteristics (i.e. wages, service components, service division, separation from military, deployment history, and service length) were obtained from the Defense Manpower Data Centre (DMDC) as management data. Marriage status status was self-reported in the survey and compensated for DMDC data if missing. All variables were at the survey completion date for active and reserve/National Guard participants or at the last known status of veteran participants.
Millennium Cohort Survey
This study measures a wide range of variables including sociodemographic factors, military service, stressful life events, psychosocial factors, health-related behaviors, physical health, illness and injuries, medical conditions, medical conditions, and medical use use (see Castañeda et al., 2023 for reviews of research measures, methodology, and data links). Given the lack of interest and not the content of these questions per se, all possible survey variables expected by all participants to see were included in the analysis, and each participant's response was converted to a missing value flag in the dummy code. Missing variables not diagnosed due to non-exposure in the study were excluded from the analysis. For new enrollee participants, these excluded variables include only skip patterns, research attributes, and follow-up, resulting in 250 items (see table in Additional File 1). For follow-up participants, these excluded variables included skip patterns, research attributes, new enrollees only, paper or web survey only, and combat exposure variables as many participants were isolated from the military. This led to 176 items.
Survey attributes
Each survey question (participants in new enrollment) included in the analysis was qualitatively coded for sensitivity (or personal, invasive, threatening, or anxiety). Questions could be perceived by two reviewers anchoring from 0 (low sensitivity) to 2 (high sensitivity) and answering the question independently by two reviewers. For example, questions regarding adverse childhood experiences, homelessness, sexual orientation, and life stressors were scored as high sensitivity. Questions in these surveys were indexed by the order in which they were displayed to participants (range =[0, 249]) and the questions that are grouped by the survey subsection and displayed together in the survey. This process caused 39 survey subsections, allowing calculation of average question locations (m= 143.13, SD= 80.09), question sensitivity (m= 0.44, SD= 0.60), and the count of questions (m= 6.44, SD= 5.62) Within each section.
Development of missing algorithms
We developed a machine learning algorithm for decomposition of MAR and MNAR at individual level analysis (see Figure 1 for a visual diagram of this procedure). Ordered data was obtained using the missing value flag, transposed them as before, and iterated each person (now represented by columns) to fit the logistic regression classifier. Each of these associated the missing value flags for that person at the index (or location) of the missing value flags for that person. This classifier identifies the index threshold that distinguishes zeros (not missing) from zeros (missing). The initial threshold indicates participants who agree and then quit immediately thereafter. The final threshold indicates participants who completed the entire study, while the thresholds between them indicate participants who completed the study at some point but have completed the study. We output classification accuracy from these different classifiers and revealed that it was very accurate to find this threshold for both new subscribers on average (we found them to be very accurate)m= 0.99, SD= 0.019) and follow-up (m= 0.98, SD= 0.021). This suggests that machine learning algorithms were effective in identifying and characterizing non-complete research.
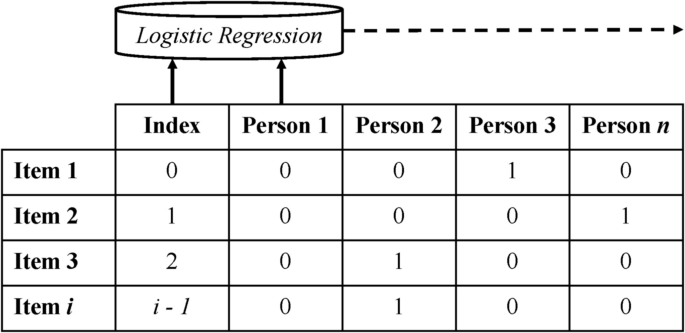
Diagram of the algorithm for decomposition of MAR and MNAR. The index is the place of the item, and the person's response is missing the value flag (not missing = 0, missing = 1). The logistic regression classifier uses an index to iterate each person who predicts a response. For each person, logistic regression outputs an index threshold that differentiates the lack of missing data. In this example, Person 2 completed the survey after Item 2 (i.e. mnar) and completed the survey as everyone else answered all items or only exhibited skips of MAR items.
This machine learning algorithm was used to identify non-complete (vs.complete) surveys and estimated survey locations for surveys that were broken or quit (complete). Output predictive values from each machine learning classifier to reconstruct where each participant completed (or completed) the survey, identifying non-complete (vs.complete). Of the 80,986 follow-ups, only 234 respondents (0.29%) were classified as noncomplete. However, out of the 58,609 new enrollees, 9,046 (15.43%) were classified as noncomplete, representing a significant difference in the rate of noncomplete between these two groups. χ2(1) = 12,568.17, p<0.001. As can be seen in Figure 1, the modal end locations for new subscribers were the start of the investigation, but there were also significant variations in these end locations (m= 104.14, SD= 78.94). As can be seen in Figure 2, examining the frequency of missing items due to item location between people classified as completers and noncompleters reveals that these groups successfully decompose missing MAR and MNAR respectively. Noncompletes show a trend of increasing as missing points from those who have completed the survey is aggregated, but not for perfect people who instead show that they increase missing points to some well-dispersed items (Figure 3).
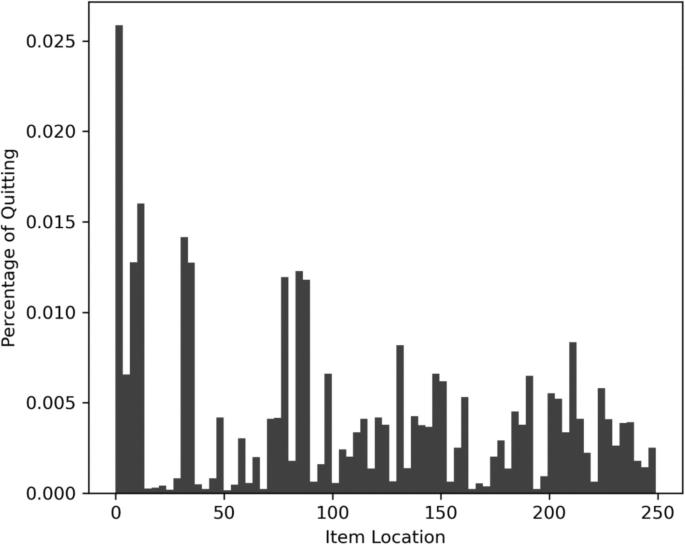
Frequency histogram of end locations between new subscribers. The location of the item represents the location of the item in the survey, the first item in the survey has a location of 0, and the last item in the survey has a location of 249
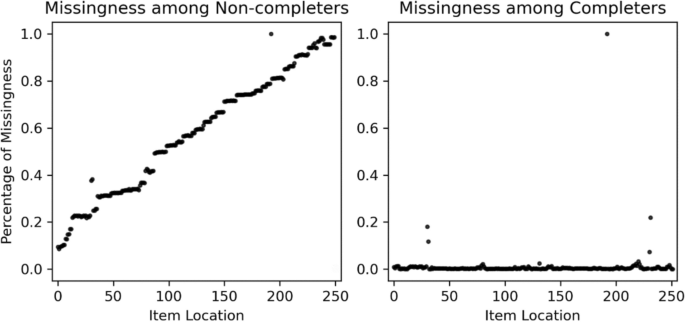
Decomposition of noncomplete and missing parts between new subscribers. The item location represents the location of the item in the survey, the first item in the survey has a location of 0, and the last item in the survey has a location of 249.
Analysis plan
Descriptive statistics for demographic and military characteristics between new enrollees and follow-up participants were calculated. Data analysis went in four steps using open source packages from Python (Python Software Foundation, Beaverton, Oregon, USA). First, we evaluated the amount and type of missing research, focusing on MAR vs. MNAR. Second, we tested the effect of different attributes of survey attributes on incompleteness of the survey. Third, the effects of various individual sociodemographic and military characteristics on the non-completion of the survey were tested.


