NLP relies on a variety of artificial intelligence models to understand human language. Among these, BERT9 is widely used. It is based on transformer architectures, which effectively capture linguistic and semantic nuances28. In addition to transformer-based models, general neural networks are also commonly employed in deep learning. They consist of multiple layers and weighted connections, which are gradually updated during training to learn patterns from large datasets29. This section outlines the key components involved in constructing the proposed framework.
The proposed framework introduces a hybrid approach for Arabic text classification. It leverages CAMeLBERT embeddings as a feature extractor, combined with a feed-forward DNN classifier. A Transformer-specific preprocessing step ensures robust handling of diacritics, elongations, and orthographic variations30. Additionally, class imbalance is addressed using the Class Weighting algorithm.
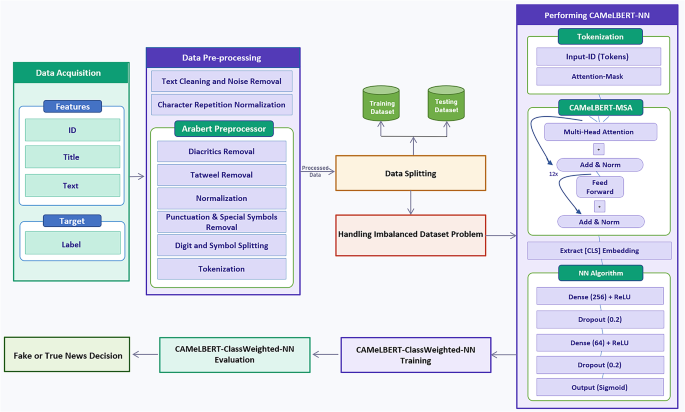
The design choice of this hybrid framework is motivated by several factors. First, using CAMeLBERT as a fixed feature extractor provides rich semantic embeddings without the high computational cost of fully fine-tuning Transformer-based approaches. This makes it suitable for large-scale or real-world applications with limited computational resources. Second, combining these embeddings with a DNN classifier allows the model to capture complex non-linear relationships that traditional linear classifiers may miss8. Third, Class Weighting is used to address class imbalance and avoid potential noise or overfitting introduced by data-level resampling techniques such as SMOTE or oversampling. Compared to conventional ML pipelines or full fine-tuning of Transformers, this design provides a balanced approach. It ensures robust contextual representation, computational efficiency, and effective handling of underrepresented classes. As a result, the framework is reproducible and performs well for Arabic fake news detection. Moreover, this hybrid design enhances scalability and reusability. By decoupling feature extraction from classifier training, CAMeLBERT embeddings can be reused across different datasets or related tasks. This avoids full model retraining and enables efficient experimentation while reducing computational overhead. All preprocessing steps, model architecture, and hyperparameters are comprehensively documented, ensuring full reproducibility of the framework and facilitating its adaptation for future research. The subsequent subsections describe dataset acquisition, data preprocessing, data splitting, model implementation, training, performance evaluation, and the generation of classification reports indicating whether the news is fake or real. Figure 1 presents a block diagram summarizing these components, each of which is discussed in detail in the following subsections.

Block diagram of the proposed fake news detection system.
Data acquisition
The dataset was carefully compiled through a multi-source collection strategy to include news articles spanning multiple categories, such as political, economic, and social news, ensuring diversity and supporting generalizability of the proposed model. Articles were gathered from three primary categories of sources to ensure reliability:
-
(i)
Trusted news sources (~45%): Reliable news articles were collected from established and reputable Arabic news agencies, including well-known regional media platforms. These sources provided verified, high-quality content used to represent legitimate news.
-
(ii)
Unverified online content (~30%): Additional articles were collected from public online spaces such as blogs, open Facebook pages, and user-generated posts. These samples typically exhibit higher rates of misinformation and were manually labeled by the research team following a rigorous verification protocol. To capture the characteristics of social media dissemination, this subset reflects informal linguistic styles and rapid propagation patterns typical of user-generated online content. Each article was cross-referenced against official news agencies and reputable Arabic fact-checking platforms, such as Fatabyyano31 and the Arab Fact-Checkers Network (AFCN)32. The criteria for labeling an article as ’fake’ included the presence of fabricated claims, lack of credible attribution, or direct contradictions with verified reports from official national and international statements.
To validate the labeling quality and objectivity, a challenging subset of 500 samples was independently double-coded by the three members of the research team. The inter-rater agreement was subsequently calculated using Fleiss’ Kappa12, yielding a high score of \(\kappa\) = 0.80, which confirms the substantial agreement and consistency of our applied criteria
-
(iii)
External benchmark datasets (~25%): To enhance coverage and reduce domain dependency, part of the dataset was enriched using samples adapted from well-known fake-news benchmark datasets, such as WELFake33 and LIAR34. Relevant articles were translated into Arabic.
The translation process was carried out using the Google Translate API (via the deep-translator package in Python35) to ensure high efficiency. Crucially, the translated content was subsequently subjected to a rigorous human post-editing and quality assurance phase by a native Arabic speaker to guarantee linguistic accuracy and, most importantly, preserve the context and deceptive linguistic nuances essential for the fake news detection task.
The dataset consists of 7,474 Arabic news articles spanning the period from 2015 to 2025, covering political, economic, and social topics. Political news dominates the dataset, with international political news (~40%) and national political news (~15%). Economic and social news collectively account for (~25%), while the remaining (~20%) is distributed across other related categories, with a higher proportion of political news, while maintaining coverage of other relevant topics. The dataset primarily focuses on Modern Standard Arabic (MSA), ensuring geographical inclusivity and linguistic consistency across the Arab world. It also includes elements of ’White Arabic’, a simplified semi-formal style prevalent in digital journalism, to better reflect contemporary online content. This strategic focus avoids regional dialectal bias, ensuring that the model remains robust and generalizable across diverse Arabic-speaking populations while maintaining the authenticity required to detect misinformation in social media contexts.
The dataset is structured in tabular form, where each record includes an identifier of the news sample (Id), the news title (the headline of the news article), the full text (the main body of the article), and the corresponding label, which serves as the target variable in the classification task (real or fake). The dataset is moderately imbalanced, with 4,359 samples (58.32%) labeled as real and 3,115 samples (41.68%) labeled as fake, reflecting the natural skew typically observed in real-world news content.
Data pre-processing
After constructing the dataset, the collected raw Arabic texts contained various inconsistencies, including diacritics, elongations (tatweel), emojis, special characters, and noise from user-generated content, which can increase data sparsity and hinder model effectiveness. To ensure robust representation, we adopted a comprehensive preprocessing pipeline specifically tailored for modern Arabic Transformer models.
We utilized the AraBERT Preprocessor, a specialized tool designed to handle the linguistic complexities of Arabic text36. This approach was preferred over traditional methods (stemming or stop-word removal) as it preserves the morphological and contextual integrity vital for transformer-based embeddings.
The preprocessing pipeline consisted of the following sequential steps:
-
Cleaning and Noise Removal: Non-informative elements such as hashtags, user mentions, and hyperlinks were removed using regular expressions (regex). This technique enabled automated identification and elimination of such elements to ensure that only semantically meaningful content is fed into the model.
-
Character-Level Normalization: Informal Arabic writing often contains character-level noise, including exaggerated character repetition for emphasis (e.g., elongated forms such as jameeeel or halooo), excessive whitespace, and spelling irregularities or incorrect characters. These patterns were normalized to their standard forms to reduce noise and improve model robustness.
Following these initial cleaning steps, the AraBERT preprocessor was applied to perform advanced linguistic standardization, ensuring the text is fully compatible with the WordPiece tokenization scheme. The preprocessor performs the following integrated tasks:
-
Removing diacritics: Arabic texts often include diacritics, which can increase data sparsity. Removing them ensures consistency in word representation.
-
Removing elongations: Some words in the Arabic language include unnecessary elongation characters for stylistic purposes. These were normalized to their base forms.
-
Normalization of characters: Different forms of certain Arabic letters (such as ”A” with different diacritical marks) were unified into a single representation to reduce vocabulary size.
-
Sub-word decomposition (WordPiece): Rare or unseen words are decomposed into sub-words using the WordPiece algorithm, ensuring better vocabulary coverage and representation.
-
Removing unwanted symbols: Special characters, emojis, URLs, and punctuation not relevant to the classification task were removed.
By integrating the AraBERT preprocessor with the CAMeLBERT tokenizer, the dataset was transformed into a clean, standardized format. This synergy ensures that the hybrid model receives high-quality linguistic inputs, directly contributing to the overall accuracy and robustness of the fake news detection system.
Data splitting
The dataset was divided into distinct subsets using the stratified random sampling technique to ensure proportional representation of both ”real” and ”fake” news classes in all partitions, mitigating the risk associated with the observed class imbalance. The hold-out cross-validation method was applied, splitting the dataset into training and testing partitions. An 80%/20% train-test split was adopted for training and optimizing the downstream classifier and for testing its predictive performance on unseen data, respectively37. A fixed random state of 44 was adopted for all experiments. All data splitting parameters are detailed in Table 2.
Applying CAMeLBERT-classweighting-NN system
The core contribution of this study is the proposed hybrid framework, which combines the strong contextual representation capabilities of the CAMeLBERT-base model specifically pre-trained for Modern Standard Arabic (MSA version6) (used as a fixed feature extractor) with a sophisticated Deep neural network classifier. This architecture is specifically enhanced by the integration of the Class Weighting technique during training. This combination is designed to effectively leverage rich contextual embeddings while simultaneously addressing the challenges posed by class imbalance and the inherent complexity of Arabic fake news detection.
Handling the imbalanced dataset problem using class weighting
After splitting the data, we encountered a significant imbalance in our dataset, with a disproportionate distribution of class labels for fake and true news, where the number of real news instances greatly exceeds that of fake news instances. The presence of this imbalance reduces the effectiveness of the system, as it leads to unstable classification and a tendency to bias toward the incorrect class during prediction. Therefore, it is essential to address this issue to avoid misleading results38,39. To address this, both data-level strategies (e.g., SMOTE, oversampling, undersampling) and algorithm-level approaches (e.g., Class Weighting) can be employed.
Data-level resampling techniques are commonly used to mitigate class imbalance, but each method has inherent limitations. Random oversampling duplicates minority class instances, which can lead to overfitting and reduce the model’s generalizability. Random undersampling removes instances from the majority class, potentially discarding valuable information and negatively impacting overall performance40,41. SMOTE (Synthetic Minority Oversampling Technique) generates synthetic samples for the minority class, but it may introduce noise or create unrealistic instances that do not reflect the true data distribution42. In contrast, algorithm-level approaches such as Class Weighting adjust the loss function to account for imbalance without altering the original data43. Unlike oversampling or undersampling techniques, Class Weighting doesn’t require modifying the data or generating synthetic samples. This helps prevent issues such as overfitting and information loss, thereby offering a more robust solution for training models on imbalanced datasets.
In this study, we focus on Class Weighting as an algorithm-level solution because it proved to be the most effective strategy in our experiments. To implement this, we applied Class Weighting in the loss function of transformer-based neural networks. We systematically compared this approach with several data-level balancing techniques, including SMOTE, random oversampling, and random undersampling, across the same baselines (NN, Transformer-NN variants, and conventional models). Experimental results demonstrate that Class Weighting consistently outperforms all other methods across multiple evaluation metrics. This confirms that Class Weighting provides a robust and reliable framework for handling imbalanced datasets in Arabic fake news detection.
The CAMeLBERT feature extractor
The feature extraction layer of our proposed system utilizes the CAMeLBERT model. CAMeLBERT is a state-of-the-art Arabic Transformer model built upon the architecture of BERT6. BERT pre-training relies primarily on the Masked Language Modeling (MLM) objective, which enables the model to learn rich, bidirectional contextual representations by predicting randomly masked tokens within a sentence44. This bidirectionality allows the resulting embeddings to capture deeper semantic and syntactic dependencies, making them well suited for downstream classification tasks45.
Selecting the appropriate Arabic BERT variant is essential for ensuring optimal alignment with the linguistic characteristics of our dataset. CAMeLBERT provides several pretrained versions trained on different Arabic corpora, including Mix, MSA, DA (Dialectal Arabic), and CA (Classical Arabic)46. This study employs the CAMeLBERT-base MSA model, which is trained exclusively on Modern Standard Arabic. This selection maximizes compatibility with our dataset composed entirely of MSA news articles, ensuring that the extracted embeddings remain linguistically consistent and minimizing representation noise. Among the available MSA variants (full, half, quarter, etc.), the base model offers the best balance between representational quality and computational efficiency, making it suitable for both experimentation and potential real-world deployment. All CAMeLBERT variants are pretrained on Arabic corpora only, unlike multilingual BERT models, ensuring more stable and semantically coherent embeddings for Arabic texts.
Texts are tokenized using CAMeLBERT’s WordPiece tokenizer. The special tokens [CLS] and [SEP] are added at the beginning and end of each sequence, respectively, following the BERT standard architecture45,46. Positional embeddings encode the order of tokens within the sequence, and segment embeddings are included for all tokens to indicate sentence membership, even when the sequence contains a single sentence. The sum of token, positional, and segment embeddings is passed through CAMeLBERT’s stacked transformer layers, producing contextualized token representations. The final hidden state corresponding to the [CLS] token (768-dimensional) is extracted as a fixed-length feature vector representing the entire sequence. These embeddings are then fed into a downstream feed-forward classifier, which applies a linear transformation followed by a ReLU activation function, as defined in Eq. 1 where the input value is denoted by \(A\). Figure 2 illustrates the CAMeLBERT-based feature extractor architecture.
$$\begin{aligned} relu(A) = \max (0, A) \end{aligned}$$
(1)

CAMeLBERT base components.
DNN classifier
Text classification tasks demonstrate the advantage of NN for processing textual data47. A sequence of computational procedures is used by the numerous layers of linked neurons that make up the NN to convert input data into outputs48.
In this study, the CAMeLBERT model is employed to generate 768-dimensional contextualized embeddings from input text, which are then passed to the neural network for classification. The proposed classifier is a feed-forward neural network that takes these embeddings as input. The architecture consists of two fully connected layers with 256 and 64 units, respectively, each followed by ReLU activation and dropout (rate 0.2) for regularization. A final sigmoid layer outputs probabilities for binary classification, which are calculated as shown in Eq. 2. The network is trained using the Adam optimizer with binary cross-entropy loss, while class weights computed from the training set are applied to mitigate label imbalance.
$$\begin{aligned} \sigma (A) = \frac{1}{1 + e^{-A}} \end{aligned}$$
(2)
where \(\sigma (A)\) denotes the output of the sigmoid function, which takes A as input, and e is the base of the natural logarithm, approximately 2.71828.
Model training setup
In this section, we describe the training configuration and systematic parameter tuning adopted for the hybrid CAMeLBERT-DNN system, including the definition of parameters and hyperparameters, to ensure clarity and reproducibility of the experimental process. In neural networks, parameters refer to the trainable weights and biases that the model learns during the training process, updated via backpropagation to minimize the loss function. Hyperparameters, on the other hand, are predefined settings, not learned from data, and are tuned experimentally for optimal performance, such as the learning rate, number of epochs, and batch size. Their selection is systematically justified in the following section.
Hyperparameter Tuning: The selection of the network architecture and the final hyperparameters was established via a structured Grid Search methodology49 conducted on the validation set, chosen to ensure an objective and reproducible, performance-driven selection process. This approach was adopted to systematically evaluate the impact of each hyperparameter on convergence behavior and generalization performance. Several configurations exhibited early signs of overfitting, which informed the exclusion of unstable settings. The final configuration was therefore selected based on its ability to minimize validation loss while maintaining stable generalization behavior. The hyperparameters explored included the learning rate \(1 \times 10^{-5},\ 5 \times 10^{-5},\ 1 \times 10^{-4},\ 5 \times 10^{-4}\), batch size {16, 32, 64}, and variations in the DNN architecture, specifically the number of dense layer units {128, 256, 512} and corresponding dropout rates{0.1, 0.2, 0.3}. The final configuration (learning rate: \(5 \times 10^{-4}\), batch size: 16, dense units: 256, dropout: 0.2) was validated as the selected setup, achieving efficient loss minimization without inducing training instability. The hyperparameter selection strategy was guided by standard practices in neural network tuning, where learning rates are explored on a logarithmic scale and batch sizes are chosen based on memory and generalization trade-offs50.
-
1.
Feature Extractor Selection: We selected the CAMeLBERT-base MSA model as the foundational embedding layer. This choice was motivated by prior studies showing that CAMeLBERT-base MSA performs well on Modern Standard Arabic (MSA) tasks, compared to generic or dialectal models6. The selection process focused specifically on the MSA version of CAMeLBERT, as variants pre-trained on mixed dialects (e.g., CAMeLBERT-mix) or specific dialects (e.g., CAMeLBERT-da) are optimized for colloquial language tasks and were found to be suboptimal for our purely MSA-based corpus. Leveraging a model pre-trained exclusively on high-quality MSA corpus ensures that the rich morphological and syntactic features of the corpus are accurately captured, providing an optimized feature space for the downstream classification task.
-
2.
Imbalance Handling Justification: As the dataset exhibits class imbalance, we opted for the algorithm-level solution of utilizing Class Weighting43. This technique, detailed in Section “Handling the imbalanced dataset problem using class weighting”, modifies the Binary Crossentropy loss function to dynamically assign a higher penalty to errors made on minority-class samples. This method is preferred as it preserves the integrity of the original dataset distribution. The Class Weighting (\(weight_i\)) for each class i is determined based on the inverse frequency, as shown in Equation 3 where N is the total number of samples, k is the number of classes, and \(n_i\) is the number of samples in class i.
$$\begin{aligned} weight_i = \frac{N}{k \cdot n_i} \end{aligned}$$
(3)
-
3.
DNN Architecture and Activation: The activation function used in the hidden layers is ReLU, while the final output layer employs the Sigmoid activation function for binary classification, which maps the network’s final output to a probability value [0, 1] facilitating the final decision on class membership. The ReLU activation was selected based on its computational efficiency and its established role in preventing vanishing gradients51. These choices (256 and 64 units, dropout rate 0.2) were made to balance the model’s expressive power and training efficiency while mitigating overfitting.
-
4.
Training Protocol: The Max Sequence Length was fixed at 128 tokens based on the dataset’s token length distribution analysis, maximizing coverage while maintaining computational efficiency and minimizing the dilutive effect of zero-padding. The DNN training batch size was set to 16, providing a balance between memory efficiency and maintaining a stable gradient across updates. Different batch sizes were used for feature extraction and DNN training to account for their distinct computational and optimization characteristics. This distinction ensures both computational efficiency during feature extraction and stable gradient updates during DNN training. The model was trained using the Adam optimizer based on its established efficiency and status as the prevailing standard in deep learning literature for similar NLP tasks52 and was chosen with a learning rate of 0.0005, utilizing the Binary Crossentropy loss function, enhanced by Class Weighting (as fully described in Section “Handling the imbalanced dataset problem using class weighting”) to mitigate label imbalance. The chosen learning rate was validated during the Grid Search process as the configuration that minimized the validation loss efficiently, without inducing training instability or requiring an excessive number of epochs. An initially higher maximum number of training epochs was employed in conjunction with Early Stopping based on the validation loss. Since convergence was consistently achieved before the tenth epoch, the number of epochs was fixed at 10 in the final training configuration. This strategy ensured efficient training while preventing overfitting and maintaining stable convergence behavior. The comprehensive set of experimental settings and hyperparameters used for the entire system are presented in Table 2 and Table 3.
Hybrid classification algorithm (Pseudocode)
To ensure reproducibility and full transparency of the proposed hybrid approach, we present the complete implementation workflow, integrating all stages from data pre-processing and feature extraction to the final training and classification using the deep neural network. Algorithm 1 summarizes the step-by-step logic of the methodology.

Training the hybrid CAMeLBERT-DNN classifier
CAMeLBERT-ClassWeighting-NN evaluation metrics
The performance of the proposed hybrid CAMeLBERT-ClassWeighting-NN model is evaluated using standard classification metrics, including the confusion matrix, accuracy (ACCU), precision (PREC), recall (RECA), F1-score, and the area under the receiver operating characteristic curve (ROC-AUC). When estimating these metrics, we consider the number of true positives (|TP|), true negatives (|TN|), false positives (|FP|), and false negatives (|FN|).
A confusion matrix provides a detailed overview of the model’s performance on a test dataset, illustrating the counts of correctly and incorrectly classified instances53. This allows for the identification of specific types of misclassifications, offering insight into the strengths and weaknesses of the model54. Table 4 presents the generic structure of a confusion matrix. The actual counts used for evaluation are computed directly from the test set. The formulas for calculating the classification metrics are given in Equations (4)–(7). Each metric highlights a different aspect of model performance and is computed based on the confusion matrix derived from the test dataset. Higher values indicate better performance.
$$\begin{aligned} \text {ACCU}= & \frac{|\text {TP}| + |\text {TN}|}{|\text {TP}| + |\text {FP}| + |\text {TN}| + |\text {FN}| } \end{aligned}$$
(4)
$$\begin{aligned} \text {PREC}= & \frac{|\text {TP}|}{|\text {TP}| + |\text {FP}| } \end{aligned}$$
(5)
$$\begin{aligned} \text {RECA}= & \frac{|\text {TP}|}{|\text {TP}| + |\text {FN}| }\end{aligned}$$
(6)
$$\begin{aligned} \text {F1-score}= & 2 * \frac{\text {Precision} * \text {Recall}}{\text {Precision} + \text {Recall} } \end{aligned}$$
(7)
While the previous metrics quantify performance at a fixed threshold, the ROC-AUC evaluates model performance across varying classification thresholds, providing insight into the model’s discriminative ability. In addition, the ROC curve is used to evaluate the trade-off between the true positive rate (recall) and the false positive rate across different classification thresholds. AUC provides a summary measure of the model’s discriminative ability.
Model interpretability
To improve the transparency and explainability of the proposed CAMeLBERT-based neural network framework, model interpretability techniques were employed. This is particularly crucial in fake news detection, where understanding the linguistic indicators of deception is as important as the classification accuracy itself. These techniques aim to provide insights into how different input features, represented as contextual embeddings, influence the model’s predictions. In this study, two complementary approaches were utilized: SHAP for global interpretability, which identifies overall patterns and influential embedding dimensions across the dataset, and LIME for local interpretability, which explains individual predictions by approximating the model’s behavior around specific instances. This dual approach enables a comprehensive understanding of the model’s decision-making process at both the dataset and instance levels.
SHAP (global interpretability)
To enhance the transparency and interpretability of the proposed classification framework, SHAP (SHapley Additive exPlanations) was employed to analyze the contribution of input features to the model’s predictions. Based on cooperative game theory, SHAP provides a mathematically grounded approach to attribute the model’s output to each feature’s contribution. Since the classifier relies on fixed contextual embeddings extracted from CAMeLBERT, interpretability is performed at the embedding level rather than at the raw token level.
A neural network classifier was explained using SHAP DeepExplainer, which is specifically optimized for deep learning architectures. A representative background set was constructed by randomly sampling up to 100 embedding vectors from the training data to estimate the expected model output. For global interpretation, SHAP values were computed for a randomly selected subset of up to 500 samples from the test set. Global feature importance was assessed using SHAP summary plots, including bar plots for mean absolute SHAP values and dot plots for the distribution and direction of contributions across samples.
LIME (local interpretability)
To provide instance-level explanations, LIME (Local Interpretable Model-agnostic Explanations) was applied to selected test instances. LIME approximates the classifier locally with a simpler interpretable model to identify which embedding dimensions contributed most significantly to individual predictions. By perturbing the input embeddings and observing the changes in the model’s output, LIME provides a ”human-friendly” explanation for why a specific Arabic article was flagged as fake. This local analysis complements the global insights obtained from SHAP, enabling a more detailed understanding of the model’s decision-making process for specific samples.


