Machine learning approaches are increasingly being used to aid in the elucidation of small molecule structures from mass spectrometry data. Surprisingly, however, current models often fail to outperform even simple baseline techniques. Here, we discuss why these approaches are inadequate and suggest strategies to overcome their limitations.
This article is fully accessible through your institution.
The advent of machine learning (ML) has brought about a transformative breakthrough in biology. For example, the development of AlphaFold1 Significant progress has been made in protein structure prediction, accelerating drug discovery. Within metabolomics, one area that benefits from artificial intelligence (AI) is the elucidation of the molecular structure of small molecules by liquid chromatography-tandem mass spectrometry (LC-MS/MS). Manual spectral interpretation is time-consuming and labor-intensive, so automating this process could fundamentally reshape the field by enabling high-throughput compound identification at scale.
Recognizing this potential, the community has devoted significant effort to developing datasets and ML models for automated structure elucidation.2, 3, 4, 5, 6, 7, 8, 9, 10. However, past studies have reported that ML techniques for structure elucidation are insufficient for this task.7,11. These findings are puzzling given the continued advances in common AI methods and the access to large spectral datasets. Therefore, to advance structural elucidation, it is necessary to understand the failure modes of current technologies. We first summarize how current methods work and evaluate their performance.
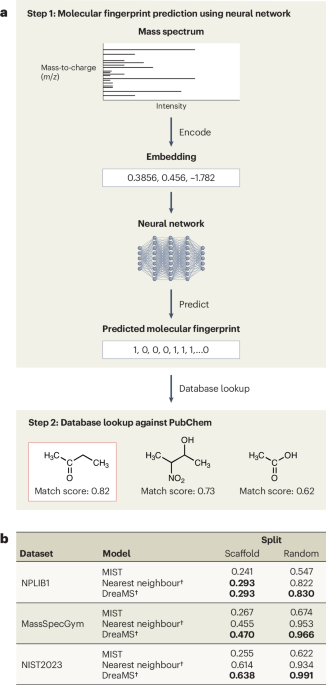
Most current AI approaches to this task share a common two-step pipeline (Figure 1a). Given an experimental spectrum, ML models predict molecular fingerprints and use them to query molecular databases such as PubChem.12 Search for candidate molecules. This approach can in principle map any spectrum to a molecular fingerprint, potentially identifying compounds that have not previously been characterized by mass spectrometry. This workflow is significantly different from traditional AI previous methods that rely on matching spectral libraries and can only identify molecules for which spectra already exist and are labeled in a reference database. From an algorithmic perspective, this mapping approach is similar to machine translation in natural language processing (NLP). In NLP, source sentences are encoded into vectors (also known as embeddings), which are decoded and translated into the target language. In this analogy, spectral peaks act as “words” and collectively form a “sentence” that is “translated” into a molecular fingerprint. Similar to ML translation, ML algorithms are trained on a dataset of experimental spectra combined with molecular fingerprints. Commonly used datasets include NPLIB1 (ref. 13), mass spec gym3 and NIST 2023 LC–MS/MS dataset14.

beStep 1: Given an LC-MS/MS spectrum, the model first encodes it into a vector embedding. This embedding is used by a neural network to predict the molecular fingerprint of the molecule that generated the spectrum. Step 2: The predicted fingerprint is compared to the fingerprints of known molecules in public databases such as PubChem. Candidate molecules are ranked based on their similarity to the predicted fingerprint. The molecular structure with the highest similarity score is assigned as the label for the spectrum. bMatching performance measured by binary Jaccard score using Morgan fingerprint (4,096 bits, radius = 2) for all models based on different dataset partitioning strategies. † indicates zero-shot evaluation (no task-specific training). For the nearest neighbor and DreaMS baselines, predictions are obtained by a top-1 search of the most similar training samples. Records in bold indicate the best performing model.
Formulating mass spectrometry analysis as machine translation enables the use of powerful architectures developed for machine translation, in particular transformer networks.15. Their strength lies in constructing a vector space to represent the meaning of the text. Encode words and sentences into embeddings such that semantically similar inputs are geometrically close. The same mechanism allows the generation of molecular fingerprints from spectral embeddings. Considering the strong performance of transformer networks across many domains, framing spectrum-to-fingerprint prediction as a transformation task holds great promise for LC-MS/MS settings.
However, treating peaks and spectra simply as words or sentences is not optimal. Although words may have multiple meanings, the ambiguity of fragment mass peaks is significantly higher because a single peak can correspond to a much larger number of possible substructures. Additionally, spectra are inherently noisy. Some peaks, unlike words that generally contribute to the meaning of a sentence, may correspond to other components of the molecular mixture without providing useful structural information for the target molecule.
To address these issues, ML preprocesses spectra to approach representations better suited to transformation paradigms. Goldman et al.5 map meters/z Convert values to candidate chemical formulas to make peaks more word-like. Bushuyev et al.4 Encode the peaks using learnable Fourier features, allowing the model to capture higher-order relationships between masses. This is similar to the word relationships learned in NLP. Another concept adopted from NLP is the underlying model. It learns input representations from large amounts of raw data using auxiliary purposes (such as masking). Bushuyev et al.4 We leverage this strategy to learn spectral embeddings and fine-tune them using spectral-fingerprint pair data. A detailed explanation of the key ML terms used in this comment is provided in Supplementary Table 1.
As with all ML systems, a key question is whether the model generalizes to unseen inputs and measures the ability to analyze molecules different from those seen in training. How can we evaluate generalization? The simplest evaluation relies on a random split, where the spectra are split into nonoverlapping training and test sets. Although this approach controls for spectral overlap, the same molecule may appear as different spectra in both sets, resulting in data leakage. A more informative and practically useful evaluation uses scaffold partitioning, where molecules are separated by chemical scaffolds. Another way to assess the generalizability and utility of ML models is to compare their performance with currently used non-ML approaches. A commonly used method is nearest neighbor baseline. This baseline assigns the molecular fingerprint of the training counterpart closest to the test spectrum according to a cosine similarity metric. The performance of all ML approaches is evaluated using the binary Jaccard score between the predicted and ground truth molecular fingerprints.
Figure 1b shows the performance of two state-of-the-art ML techniques, MIST.5Fingerprint Prediction Model, and DreaMS4we use a search-based foundational model and a nearest-neighbor search baseline across three benchmark datasets. A detailed description of the task formulation, evaluation metrics, and benchmark model is provided in Supplementary Notes 1–3, and data imputation methods and additional analyzes are described in Supplementary Notes 4 and 5.
The results were amazing. All ML methods have poor performance. For scaffold splitting, the nearest neighbor method outperforms MIST and approaches the performance of DreaMS. DreaMS is the top model for random partitioning, but drops sharply for scaffold partitioning, indicating poor generalization. Even more puzzling is the modest performance in simple settings (random splits) with high molecular overlap between training and test sets (51.9% for NPLIB1, 92.3% for MassSpecGym, and 99.5% for NIST2023). These findings contradict the hypothesis that poor performance is primarily due to insufficient training coverage.11. Simply adding data to an existing model is unlikely to solve your problem.
To understand these failures, we look at data attribution techniques that track model performance on the data on which algorithms learn. These methods identify examples that are difficult for the model to reason about and ultimately lead to poor performance. To ensure robustness, we use two complementary approaches: influence functions and split learning. An influence function identifies training examples that help or worsen a particular prediction. Instead, the training split takes all the data and splits it into a training set and a test set, resulting in the worst testing performance. Effectively, the test examples that are the most difficult for the algorithm to understand are selected. By analyzing these examples, you can better understand how algorithms fail. Below we summarize the results of these analyzes applied to LC-MS/MS ML algorithms.
Unable to generalize across experimental conditions
Both the split learning function and the influence function raise difficult flags on spectra of molecules collected under different conditions. Although the current dataset includes data from multiple experimental setups, the algorithm is unable to model how changing conditions affect the spectra.
Unable to capture peak intensity
Data imputation techniques have shown that models struggle to distinguish between similar molecules. meters/z There is a distribution, but the intensity profile is different. In fact, regardless of the intensity, the algorithm maps the spectrum to a similar map. meters/z Converts the pattern into a similar vector representation, ignoring most of the intensity information.
cannot be generalized to new chemical formulas
A significant portion of the hard samples contain spectra that contain peaks corresponding to molecular fragments that were not seen during training. Some models5 Attempts to solve this problem algorithmically do not work well with new chemical formulas.
Are these flaws caused by data, algorithms, or both? Probably both. As seen in other ML domains, the initial development of new applications begins with a homogeneous dataset. For chemical structure elucidation tasks, such datasets should contain data collected under similar conditions (e.g., consistent instrument type and molecule class) while avoiding invisible fragment expressions in the test set. Once the model can be reliably generalized under these conditions, a wider range of chemical and experimental diversity can be gradually introduced. Algorithmic advances are needed to complement improvements in datasets. For example, AlphaFold’s success is based on a neural architecture that explicitly incorporates domain-specific knowledge. In contrast, current mass spectrometry models primarily reuse NLP architectures and are therefore unable to capture domain-specific properties. Additionally, we need to go beyond fingerprint-based methods and explore alternatives to current prescriptions. Considering new architectures requires meaningful benchmarks to assess whether new models address the limitations identified here.


