Professor Yonghee Park of the Department of Statistics at Sungkyunkwan University has developed a new statistical framework called MARGO (Machine Learning-Assisted Adaptive Randomization for Group Sequential Trials Based on Overlap Weights) that can practically apply machine learning to clinical trial design. This study provides the first rigorous solution to the fundamental statistical challenges that arise when integrating ML/AI-driven decision-making into the scientifically demanding environment of clinical trials.
Promises and barriers: Why ML/AI alone is not enough
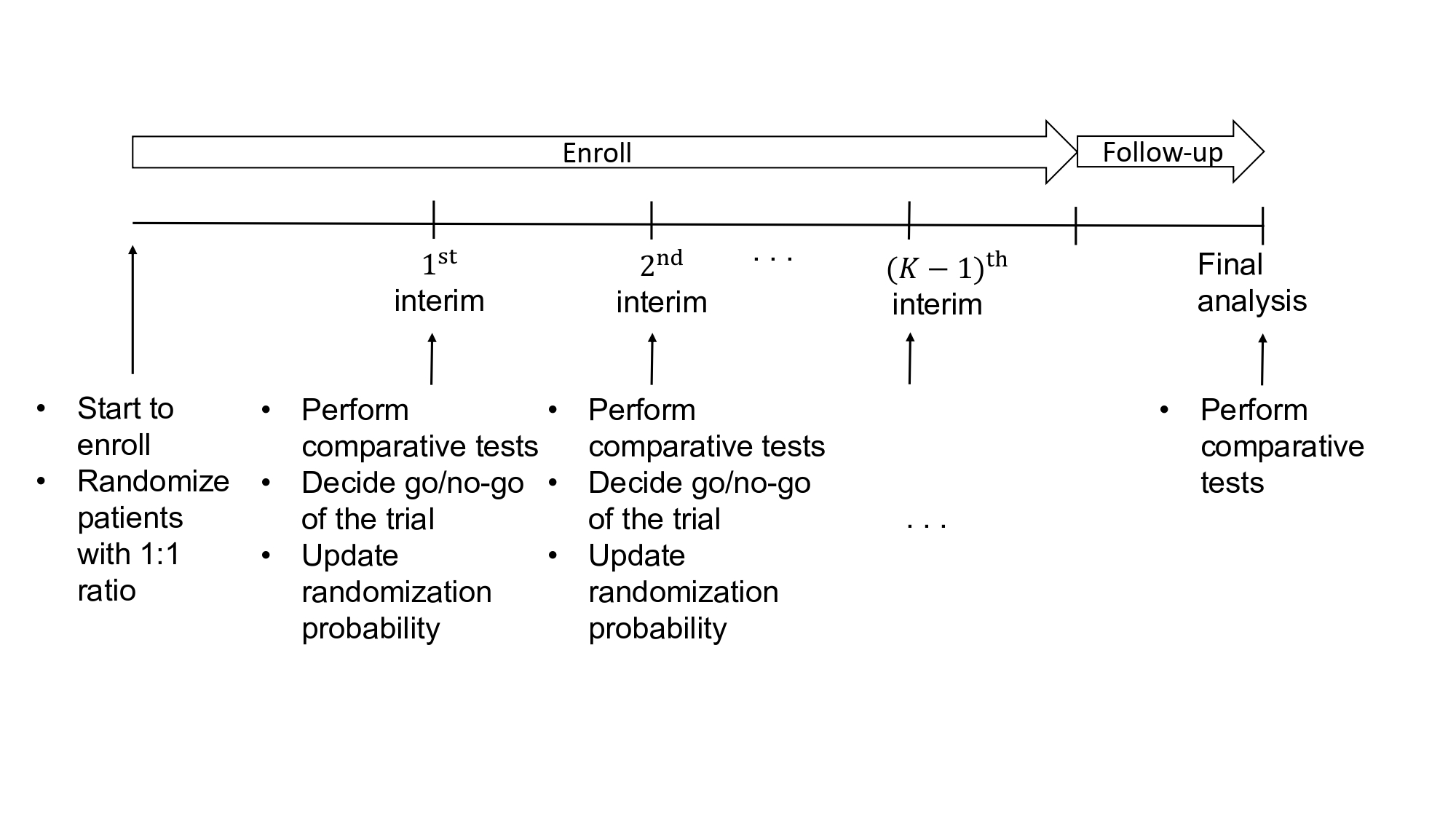
Machine learning and artificial intelligence are gaining widespread attention as innovative tools for personalized treatment allocation in clinical trials. In particular, adaptive randomization, which dynamically adjusts treatment assignment based on accumulated trial data, is a promising approach to improve patient outcomes by directing more participants to more effective treatments. However, applying this approach in practice can lead to statistically significant problems. Using patient characteristics (e.g., biomarkers) to guide treatment assignment can result in systematic imbalances between treatment groups. This imbalance of covariates biases estimates of treatment effects, increases Type I error rates, and risks erroneous conclusions. This problem is further complicated in group sequential designs that include planned interim analyzes for early stopping decisions.
Combining machine learning and causal inference: a 2-in-1 solution
To address this fundamental challenge, MARGO integrates machine learning-based predictive models with overlap weights (OW). This is a propensity score-based approach that is widely used in causal inference to adjust for covariate imbalances. MARGO uses patient covariate information to predict the probability of treatment success through machine learning and uses these predictions to prioritize patients to more effective treatments. At the same time, OW corrects the covariate imbalance between treatment groups and effectively controls the increase in bias and type I error induced by adaptive randomization. The framework was evaluated using four machine learning algorithms: Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Random Forest (RF), and Multilayer Perceptron (MLP).
Rigorously tested performance
Through extensive simulation studies, MARGO has demonstrated superior performance over traditional fixed randomization and existing adaptive randomization methods across three key dimensions. First, MARGO allocated more patients to more effective treatments. Second, we kept the overall Type I error rate below the target threshold of 0.05, even in scenarios where traditional methods increased the error rate to 0.08-0.18. Third, we maintained high statistical power under alternative scenarios while reducing the number of treatment failures. Taken together, these results demonstrate that MARGO can simultaneously improve the ethical standards and scientific integrity of clinical trials.
Beyond “Utilizing AI” to “Trusting AI in Clinical Trials”
The most important contribution of this research is not just to apply machine learning to clinical trials, but to rigorously solve the fundamental statistical problems that arise in the process. MARGO is designed to accommodate a wide range of AI models and has broad potential to expand into precision medicine and data-driven decision-making across a variety of sectors.
The study was published in Statistics in Medicine.


