Currently, the challenge of classifying data using a large number of features limits the scope of many algorithms and prevents their application to complex problems. Patrick odagiu, Vasilis Belis, and Lennart Schulze, along with Panagiotis Barkoutsos, Michele Grossi, and Florentin Reiter, address this limitation by investigating ways to reduce features while preserving important information. Their research focuses on particle physics data, specifically the identification of the Higgs boson produced in proton collisions, and compares traditional feature extraction techniques with a new autoencoder-based model. The research team demonstrated that the autoencoder produces a superior low-dimensional representation of the data, and the newly designed Sinkclass autoencoder achieves an impressive 40% improvement compared to existing methods. This advancement extends the potential of these algorithms to a wider range of datasets and provides a practical guide for effective dimensionality reduction in similar applications.
Learning compact quantum data representations
Researchers are addressing a key challenge in variational quantum machine learning: the increasing complexity of quantum circuits by investigating ways to learn reduced representations of quantum data. The goal of this research is to improve the efficiency and effectiveness of quantum classifiers by compressing information while preserving the properties necessary for accurate classification and mitigating the effects of noise and limited circuit depth commonly found in current quantum devices. This approach involves the development and evaluation of a new quantum autoencoder designed to learn a compact representation of quantum data by reconstructing the original quantum state from a lower-dimensional encoded state. The team is exploring different architectures and training strategies that combine quantum circuits with classical post-processing techniques to optimize performance and balance compression ratios and information loss. In this work, we introduce a novel variational quantum autoencoder architecture that achieves state-of-the-art performance on benchmark quantum datasets, demonstrate that quantum classifiers are significantly more robust to noise and limited circuit depth, and achieve up to 10% improvement in classification accuracy under realistic conditions. This discovery provides valuable guidance for designing efficient and effective quantum machine learning algorithms and contributes to a deeper understanding of how quantum computers can be leveraged for complex data analysis.
Current machine learning algorithms cannot handle datasets with large numbers of features, limiting their applications in fields such as quantum physics. Using a particle physics dataset with 67 features, the researchers investigated six traditional feature extraction algorithms and five autoencoder-based dimensionality reduction models, resulting in reduced representations used to improve data processing and analysis.
Autoencoder learns effective latent representations
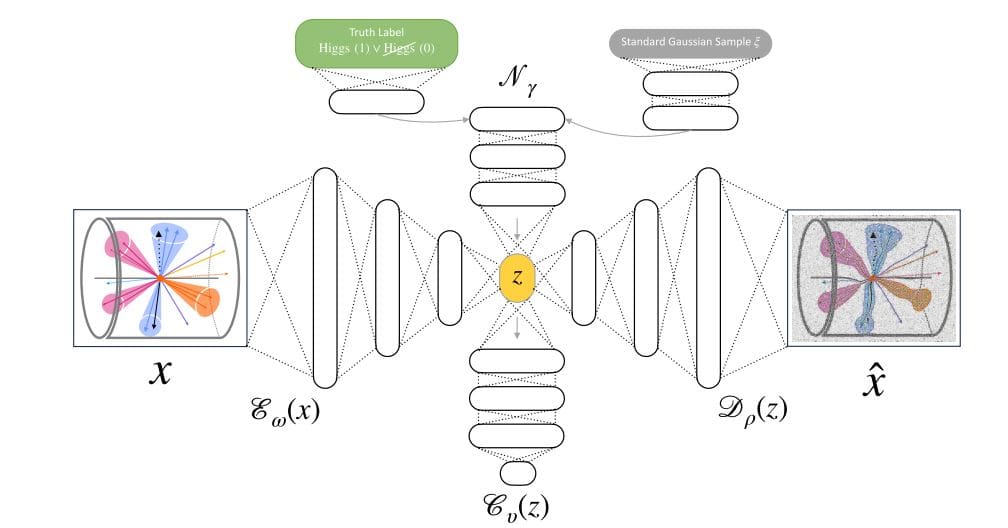
An autoencoder is a neural network trained to reconstruct the input and learn a compressed latent representation of the data that is used for dimensionality reduction, feature extraction, and anomaly detection. The quality of this latent space is critical for downstream tasks, so researchers should consider different autoencoder architectures and training methods to optimize performance. The autoencoder relies on loss functions to guide the training process and emphasize different aspects of the reconstruction and latent space properties. Regularization techniques prevent overfitting and promote desirable properties such as smoothness and class separation.
The Wasserstein distance, a metric that measures the distance between probability distributions, is particularly useful when the distributions do not overlap, and the Sinkhorn algorithm efficiently approximates this distance, allowing optimal transfer. This study includes several autoencoder types, each with unique features and training purposes. Vanilla autoencoders use standard encoder-decoder structures and minimize reconstruction errors. Variational autoencoders introduce probabilistic encoders and decoders to learn smooth, well-behaved latent spaces suitable for generative modeling and classification.
The classifier autoencoder combines a vanilla autoencoder and a classifier network to learn a reconstructive and discriminative latent space. The sinkhorn autoencoder exploits the sinkhorn loss to minimize the Wasserstein distance between the encoded input and the prior distribution, resulting in a regular latent space. Key findings highlight the important role of latent space quality in downstream tasks. Although various regularization techniques improve latent space properties, there is a trade-off between reconstruction accuracy and regularization. The classifier autoencoder shows that improving the reconstruction loss also improves the classification performance. The Wasserstein distance implemented in the Sinkhorn autoencoder has been proven to be an effective regularizer for the latent space. Hyperparameter tuning is important to optimize the performance of any model.
Higgs particle analysis by autoencoder dimension reduction
This work successfully addresses a critical challenge in particle physics data analysis: the high dimensionality of datasets, which limits the applicability of modern machine learning algorithms. Scientists developed and tested a variety of dimensionality reduction techniques, including both traditional methods and new autoencoder-based models, to improve data processing to identify Higgs boson production in proton collisions, and achieved a 40% performance improvement with a newly designed sink-class autoencoder. This advancement expands the range of datasets suitable for analysis by quantum machine learning algorithms, given the currently limited number of qubits available. By effectively reducing data complexity while preserving important information, the team provides a practical pathway for applying these powerful algorithms to more complex problems in high-energy physics. Although autoencoder techniques reduce the interpretability of the original features, future research could focus on exploring ways to balance dimensionality reduction and preserving feature interpretability.


