Appendix 1
Generally, the quantization process converts floating point weights and parameters into a 4-bit format suitable for SNN implementation. Each floating point value v is mapped to a discrete integer value m using the following formula: equation (1),30.
$$m=round(\frac{v-{v}_{min}}{{v}_{max}-{v}_{min}} \times \left({2}^{b}-1\right))$$
(1)
where b is the number of bits (4 bits for 16 levels).
vminutes and vmaximum are the minimum and maximum values of the tensor.
Discrete values are dequantized to integer values using the following method: equation (2)
$$\Wide hat{v}={v}_{min}+\frac{m}{{2}^{b}-1} ({v}_{max}-{v}_{min})$$
(2)
In this model, the number of bits used for quantization is 4, which significantly reduces computational and memory requirements.31.
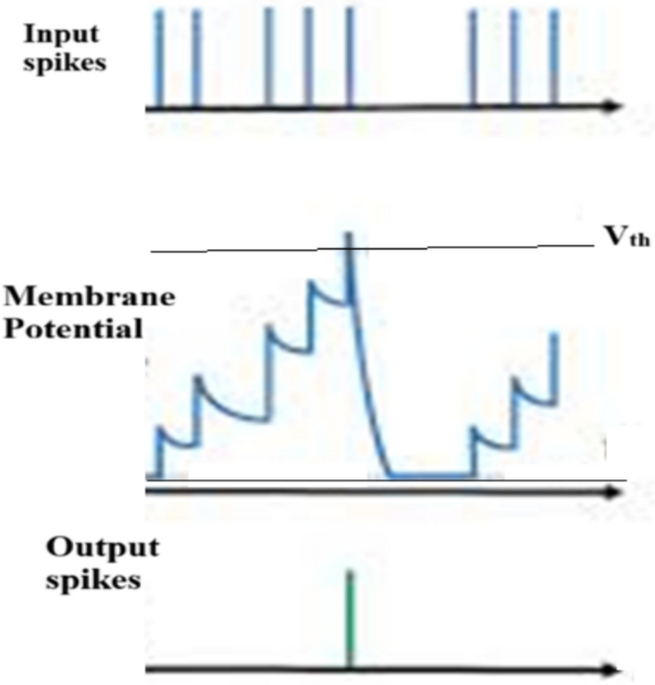
The quantized model is converted to an SNN. This maps continuous-valued activations to a spike-based representation suitable for neuromorphic hardware. In CNN, the neuron output is a continuous value from an activation function such as ReLU given by Equation 3.
where x is the input to the neuron, W is the weight, b is the bias, and y is the output of the neuron. In SNN, this is replaced by a train of spikes over time using rate coding. Neuron firing rate is proportional to CNN activation. Each spiking neuron integrates input spikes over time according to Equation 4.
$$V\left(t\right)=V\left(t-1\right)+\sum {w}_{i}{s}_{i}
(4)
Here, V
Source link


