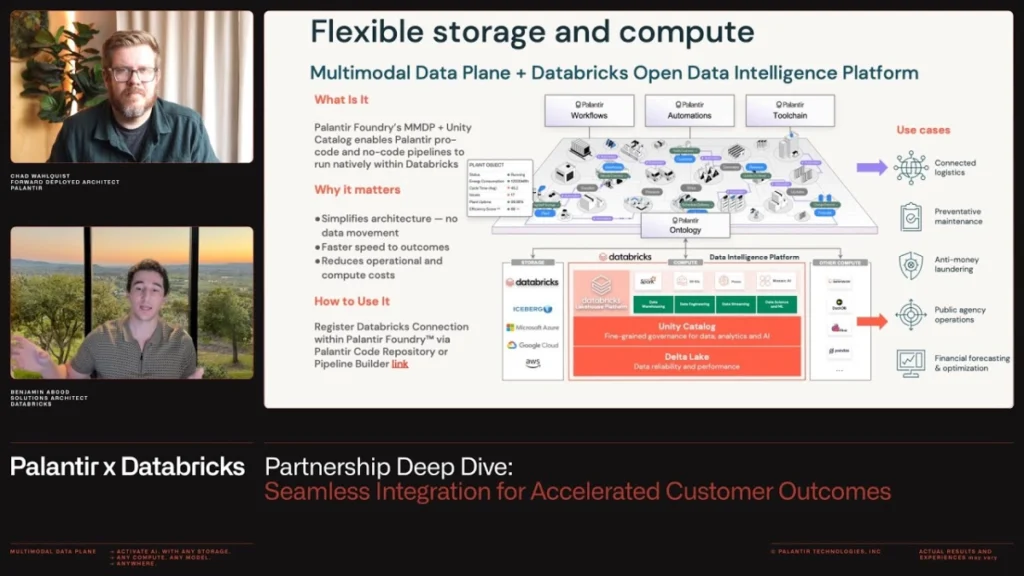
The future of operational artificial intelligence depends not only on sophisticated models, but also on eliminating the architectural friction that plagues most enterprise data stacks. This was the central theme of a recent in-depth presentation detailing the Palantir and Databricks collaboration, showing how two of the industry's most powerful platforms come together at a foundational level to accelerate customer outcomes. This partnership is a direct response to a common reality. Customers were already using both Palantir Foundry and Databricks Open Data Intelligence Platform in parallel, but the lack of seamless interoperability was creating unnecessary complexity and delays.
Chad Walkowski, Deployment Architect at Palantir, and Ben Abood, Architect at Databricks, jointly announced the new deeper integration technical pillars. They emphasized that the collaboration is “customer-driven” in nature and grew out of joint discussions by management last year that focused on how to resolve the impedance mismatch between the two ecosystems. This integration focuses on four key pillars: data federation, governance, compute, and AI and workflows and is designed to deliver value faster by eliminating the need to move or copy data between platforms.
The main technological advancement is in achieving true two-way interoperability. Traditionally, integrating these disparate platforms required cumbersome extract, transform, and load (ETL) pipelines, leading to data duplication, increased storage costs, and information obsolescence. Databricks' Unity Catalog acts as an integrated governance layer, allowing Palantir Foundry to register Databricks tables directly as “virtual tables” within its environment. This mechanism means that Foundry can access and utilize data residing in Databricks Lakehouse without physically moving it.
“It's actually a forward-and-back synchronous two-way integration. It allows you to have data in Databricks and register it in Palantir, create data in Palantir and register it in Databricks, and move it back and forth seamlessly. All done using a unified catalog and governance around it,” Walkowski explained. This architectural simplification is paramount.
The main benefits are instant and secure data sharing and simplified governance. Databricks' Unity Catalog manages fine-grained access control permissions that are applied when data is federated to Foundry. Palantir leverages service principals and Workload Identity federation for authentication, ensuring Foundry accesses data in Databricks with only the necessary permissions, eliminating the need for hard-coded credentials or secrets.
This integration is designed to ensure that computational workloads run where the data resides, a concept known as compute pushdown. When users define a transformation or pipeline within Palantir Foundry's low-code tools, its execution is automatically pushed down to Databricks' serverless compute infrastructure. This means customers can benefit from the data processing performance and scalability of Databricks while leveraging the tools they are familiar with from Foundry, such as pipeline builders and code repositories. This combination significantly reduces operational overhead and speeds up the conversion process.
“If you're already pulling all your data together and doing pipeline processing, which is what I do in Databricks, now you want to build operational applications. You want to be able to model not only the data but also the logic and actions into an ontology so that you can actually drive these integrated workflows across your business,” Walkowski said, emphasizing the move to operational applications driven by real-time data. The ability to perform complex data transformations and filtering in Foundry while the actual calculations occur seamlessly in Databricks demonstrates first-class product integration, not just a rudimentary connector.
Flexibility extends to the AI and machine learning lifecycle. Data science teams often prefer the notebook and MLflow environments provided by Databricks for training complex models and processing large datasets. Once a model is trained and registered with Databricks, it can be registered directly within the Palantir Foundry ontology. This allows models to be instantly deployed within Foundry's production applications, bridging the critical gap between experimental data science and real-world production deployments. This ability to register models, whether hosted in Databricks or imported into Foundry, provides important options for the overall architecture.
This partnership is focused on reducing the time and complexity of moving data and managing disparate systems. “We read data from Databricks, used Databricks Compute to perform the compute where the data resides, in Databricks storage, and wrote that output data set directly back to Unity Catalog,” Abood said, emphasizing achieving minimal data movement. This level of architectural synergy allows organizations to focus their resources on building valuable operational applications rather than maintaining complex data infrastructures, ultimately maximizing the speed of delivering AI-driven insights across the enterprise.


