Introduction
Machine Learning (ML), which is typically defined as the study of algorithms that improve performance through experience, supports a rapidly growing set of technologies and applications. This definition, credited to Mitchell, positions ML as both a collection of statistical methods and an engineering discipline that combines data, computation, and domain knowledge to create automated decision-making systems. [1], [2].
Purpose and Significance
This study surveys new trends in machine learning, including Federated Learning (FL), Explainable Artificial Intelligence (XAI), Graph Neural Networks (GNNs), Self-Supervised and Transfer Learning (SSL/TL), autoML/NAS, TinyML/edge, quantum machine learning (QML), reinforcement learning (RL), and multimodal methods. It evaluated their methodologies, application areas, limitations, and governance implications. These trends are important, because ML now powers critical systems in healthcare, transportation, finance, and security. Recent advancements in language and multimodal models, such as Contrastive Language-Image Pre-training (CLIP) and large transformer models, have shown both technological strengths and new societal challenges. [3]–[5].
Aim and Scope
This review summarizes significant, high-impact work (peer-reviewed research, high-quality preprints, and reliable standards/industry reports) from 2018 to 2025. It compares algorithmic approaches, summarizes real-world applications, and identifies gaps in research and governance. We focus on system-level issues central to modern ML practices: privacy, interpretability, robustness, resource efficiency, and regulatory compliance. We also trace how these issues have evolved from the Deep Learning era, including CNNs and sequence models, and the limitations that have led to new paradigms.
Research Motivation
In the past decade, ML has transitioned from solely focusing on benchmark accuracy to a systems approach because large, complex models have introduced opacity, significant data, and computational costs, along with distributional fragility. These challenges threaten fairness, sustainability, and safe deployment in the key areas. New techniques, such as FL, privacy engineering, XAI, SSL/TL, TinyML, and hardware-aware AutoML, directly address these issues. Concurrently, organizational and policy frameworks, such as the National Institute of Standards and Technology (NIST) guidance and regional regulatory proposals, are developing to manage risk.
Structure and Methods
This paper is structured as follows: (1) trace the development of ML, (2) review major technical trends and key studies, (3) synthesize overarching ethical and governance implications, and (4) suggest future research directions. A brief summary of the Materials and Methods (search strategy, inclusion criteria, and study selection) is provided in section 2. The PRISMA-style selection summary, extraction table, and mind map can be found in the supplementary material.
Materials and Methods
Search Strategy and Study Selection
We used a structured search strategy to identify recent and high-impact publications on emerging trends in Machine Learning (ML). Searches were conducted across IEEE Xplore, ACM Digital Library, SpringerLink, ScienceDirect, arXiv, and Google Scholar, from 2015 to 2024. Additional reputable sources such as NIST and the European Commission were found through citation tracking and standard repositories.
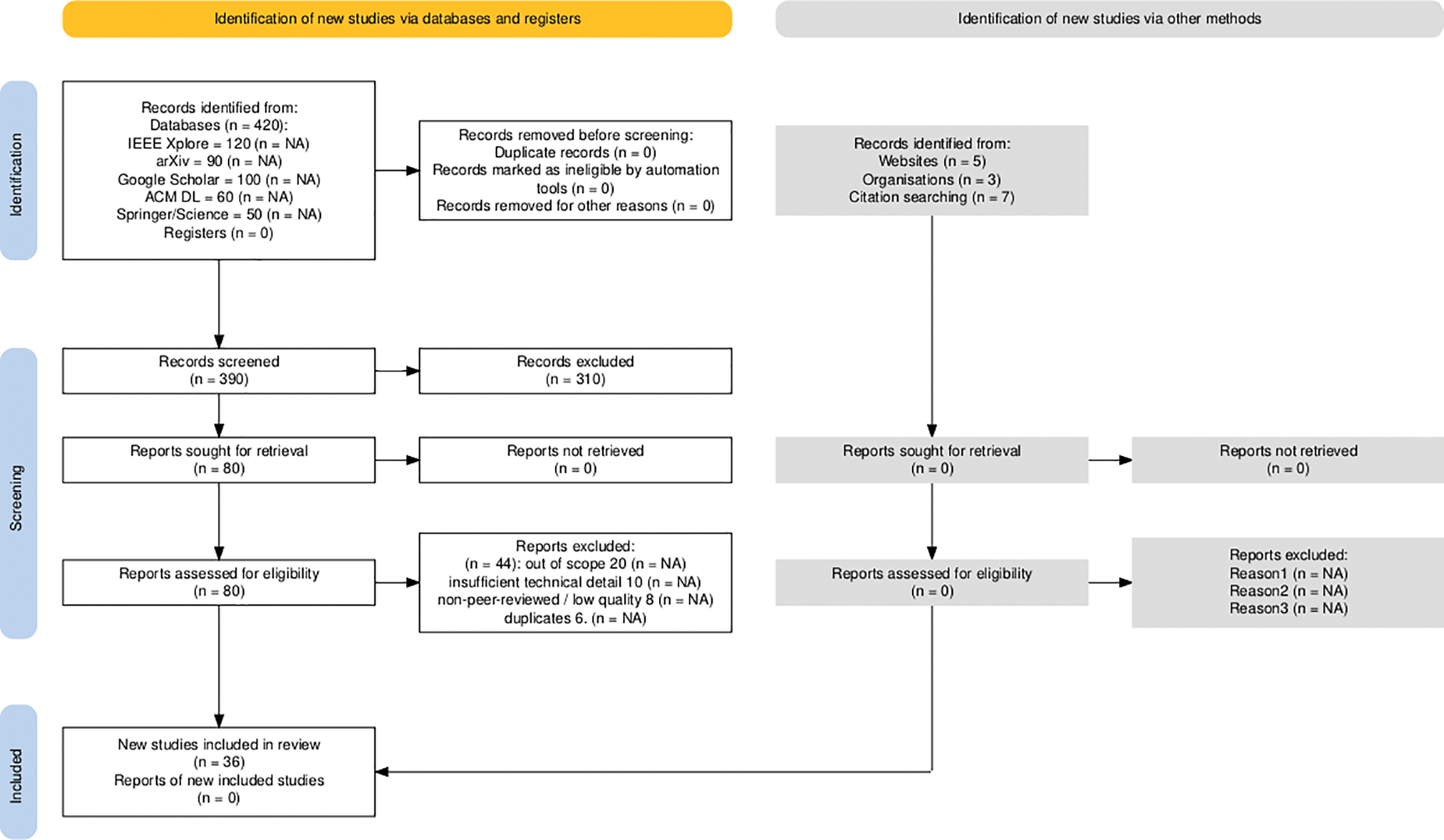
The initial search produced 420 records from academic databases and 15 from other sources (Gray literature and backward citation tracking), totalling 435 records. After removing 45 duplicates, 390 records were screened by their titles and abstracts. Of these, 310 were excluded because they were irrelevant to the emerging ML paradigms. We assessed 80 full-text articles for eligibility and excluded 44 based on relevance, insufficient technical detail, or duplication. Ultimately, 36 studies were included in the final analysis. The selection process is summarized in Fig. 1 (PRISMA flow diagram).
Fig. 1.
PRISMA flow diagram of literature selection (Records identified: 435; screened: 390; full texts assessed: 80; studies included: 36).
This review follows the logic of PRISMA reporting to ensure transparency in study inclusion; however, it is not a registered systematic review and should be understood as a targeted narrative review emphasizing high-impact, methodologically influential, and recent contributions, rather than exhaustive bibliometric coverage.
Limitations
This review followed the PRISMA reporting logic to ensure transparency in the study’s inclusion. However, it is not a registered systematic review and should be viewed as a targeted narrative review focusing on high-impact, methodologically significant recent contributions rather than exhaustive bibliographic coverage.
Findings and Results
Overview and Hypothesis
This review examined the hypothesis that recent ML research is moving from purely algorithmic advancements to system-level and deployment-focused issues such as privacy, interpretability, governance, and efficiency. This work classifies each of the 36 included studies into two broad categories as summaries in Fig. 2:
Fig. 2.
Bar chart showing the number of studies included per classification.
• Algorithmic/core methods: Studies have mainly focused on learning algorithms and model architectures (e.g., self-supervised learning (SSL), transfer learning (TL), graph neural networks (GNN), quantum ML (QML), reinforcement learning (RL), multimodal models, and theoretical foundations).
• Systems/deployment/governance: Studies mainly address deployment, privacy, interpretability, AutoML/architecture search (as operational tools), TinyML/edge, and policy/regulatory guidance.
Counts (derived from Table I in Supplementary Materials). Among the 36 included studies, the classification was as follows:
• Algorithmic/core methods = 16/36 (44.4%)
• Systems/deployment/governance = 20/36 (55.6%)
Simple Statistical Tests
A one-sided test of proportions was used to evaluate whether the true proportion of systems-focused studies exceeded 0.50.
Observed proportion are as follows:
• Observed proportion: .
• Under , standard error .
• Test statistic .
• One-sided p-value (normal approx) .
The observed share of systems-focused studies (55.6%) aligns with the stated trend, but does not reach statistical significance in a simple test at conventional alpha levels (p ≈ 0.25). This suggests that, while the evidence indicates a slight trend toward systems and deployment issues, the effect is not strong enough in this sample of 36 selected high-impact studies to reject the hypothesis of equal proportions. Classification subjectivity and overlapping themes (for example, AutoML combines algorithmic and systems aspects) mean that this quantitative result should be interpreted as supportive but not definitive.
Other Notable Quantitative Patterns
• AutoML/NAS emerged as the most frequent single theme (six refs), reflecting a significant interest in automated design and operational constraints.
• Self-Supervised Learning (SSL) and explainability (XAI) are also well represented (four refs each), showing a parallel focus on data efficiency and transparency.
• TinyML/Edge and Quantum ML have smaller but growing representations (two refs each), indicating emerging, but important deployment and exploratory research areas.
Discussion
Synthesis of Primary Findings
The literature reviewed here presents a varied path for ML research. The traditional algorithmic progress (SSL, TL, GNNs, QML, RL, and multimodal models) continues at a steady pace. However, a similar or greater amount of important work focuses on systems, deployment, and governance (FL, XAI, AutoML, TinyML, and standards/policy). This trend reflects what recent surveys and standards documents have noted. Research is expanding to include privacy-preserving methods, tools for interpretability, hardware-software co-design, and governance frameworks, such as NIST, and NIST AI Risk Management Framework [6], [7].
Statistical Insight and Caveats
The simple binomial test suggests that the observed focus on systems topics was modest (p = 0.25). Therefore, we cannot claim a statistically significant shift based on only the 36 selected studies. This finding is expected given (1) the intentional choice of influential and representative works rather than a random sample and (2) thematic overlap, as many works cover multiple categories (for example, an AutoML paper that also addresses resource efficiency). Thus, the quantitative tests here are suggestive and not definitive; they complement qualitative synthesis.
Major Themes and Implications
Data Efficiency and Representation Learning (SSL/TL)
SSL and transfer approaches reduce reliance on labels and enable broad transfer, which is essential for fields with limited labeled data, such as healthcare and science. However, high pre-training costs and misleading correlations remain major issues [8]–[11].
Privacy and Collaborative Training (FL)
Federated Learning tackles legal and organizational limits on data sharing but introduces challenges such as statistical differences, communication demands, and the need for fairness and robustness guarantees. Techniques for cryptography and differential privacy can reduce risks, but often at the expense of utility [12]–[14].
Transparency and Auditing (XAI)
Although explainability methods are progressing, they must balance fidelity, robustness, and human interpretability. Integrating them into governance processessuch as model cards, datasheets, and audit trailsis crucial for operational trust [15]–[17].
Operational Automation (AutoML/NAS) and Edge Deployment (TinyML)
AutoML/NAS can make model design more accessible, but it introduces challenges related to reproducibility and energy costs. TinyML enables ML on limited devices but requires secure updating and lifecycle monitoring [18]–[25].
Governance and Policy Maturation
Standards and regulatory proposals show a growing alignment of research and practice toward accountable ML; however, translating high-level principles into verifiable operational controls remains nascent [26]–[28].
Statistical and Methodological Considerations
The classification process (algorithmic vs. systems) is inherently subjective as many studies have been mixed. Future meta-analyses should create a multi-label coding system and use larger systematically sampled groups. Reporting on compute and energy use varies; adopting standard energy reporting metrics (Green AI) is essential for meaningful comparisons.
Practical Implications for Stakeholders
Researchers should invest in sample-efficient algorithms to ensure interpretability and robustness. They should combine innovation with environmental cost measurement.
Practitioners must adopt ML toolchains that include privacy engineering, explainability, and monitoring. They should use AutoML carefully to meet operational requirements.
Policymakers must provide clear, actionable standards for high-risk ML systems and support infrastructure for reproducible benchmarking.
Conclusions
Concluding Synthesis
The evidence from this targeted review shows that the current ML research is expanding. While algorithmic innovation is ongoing, an equal or slightly larger portion of influential work now emphasizes system-level concerns, including privacy, interpretability, efficiency, and governance. Even though our sample is not random, the topic distribution (20 out of 36 focused on systems vs. 16 on algorithms) confirms that the field is evolving into a socio-technical discipline where operational constraints and societal impacts are just as important as the raw predictive performance.
Limitations
Selection bias: The corpus (n = 36) was purposefully curated to highlight impactful works, rather than being a comprehensive bibliometric sample.
Classification subjectivity: Assigning themes requires judgment, and many studies cover both algorithmic and systems topics. In future research, a multi-label system would better capture these overlaps.
Quantitative inference: The binomial test mentioned earlier is merely suggestive; the results cannot be generalized beyond the sample without systematic sampling and a larger cohort.
Recommendations for Future Research
• Reproducible, standardized reporting for computing, energy, and privacy metrics should be adopted to enable meta-analyses (such as training FLOPs and carbon accounting).
• Develop benchmarks and metrics that measure not only accuracy but also data efficiency, interpretability, robustness under changing conditions, and environmental impacts.
• Explore hybrid methods that blend symbolic or causal reasoning with learned models to enhance sample efficiency and explainability.
• Translate governance into tools: invest in practical, auditable systems that apply NIST-style risk management at scale.
• An increase in empirical meta-research using systematic sampling methods allows for the robust testing of statistical claims about trends in the field.
Conflict of Interest
The authors declare that they do not have any conflict of interest.


