
At a time when artificial intelligence (AI) and machine learning (ML) are driving unprecedented innovation and efficiency, new types of cyber threats are emerging that put sensitive data and entire business operations at serious risk. Among these threats are: model reversal attack This is of particular concern to organizations that rely on machine learning models trained on proprietary or personal data. Unlike traditional data breaches that target vulnerabilities in databases or networks, model inversion attacks exploit the learned patterns of the machine learning model itself to extract sensitive information without directly accessing the underlying dataset.
In this blog, we explore what attacks are, how they work, why they are becoming a growing concern for businesses, and what organizations can do to protect themselves.
What is model inversion attack??
a model reversal attack This is a form of privacy attack on machine learning systems in which an attacker uses the output of a model to infer sensitive information about the data used to train the model. Rather than breaking into databases or stealing credentials, attackers observe how models respond to input queries and use those outputs (often including confidence scores and probability values) to reconstruct aspects of the training data that should be kept private.
Machine learning models do more than just generalize patterns from training data. It also inherently “remembers” details about the data, especially when the dataset is small or the model is overparameterized. By creating specific inputs and repeatedly analyzing the corresponding outputs, an attacker can reverse engineer sensitive features, such as personal attributes or sensitive information, embedded within the model.
This type of attack is fundamentally different from other ML attacks, such as membership inference, which aim to determine whether a particular data point is part of a training set. Extracting the modeltries to copy the model itself. An alternative to model inversion is to focus on Rebuild sensitive training data From the behavior of the deployed model.
Impact of model inversion attacks on organizations
A successful model inversion attack can cause significant damage to multiple areas of a business. When attackers extract sensitive training data from machine learning models, organizations face not only immediate financial losses but also lasting reputational damage and operational setbacks that extend far beyond the initial incident.
The financial impact typically begins with incident response and forensic investigation, but quickly escalates. According to the 2025 Cost of Data Breach Report, the global average cost of a data breach has risen to $4.88 million, with healthcare organizations experiencing an even higher average cost of $9.77 million per breach. If a model flip results in a breach of protected health information or financial data, organizations must comply with mandatory breach notification laws. This could result in increased costs through regulatory fines, legal liability, and potential class action lawsuits.
Reputational impact is more difficult to measure, but can be even more damaging. Trust quickly erodes when customers and partners discover that sensitive information has been reconstructed from the output of machine learning models. This loss of trust can impact customer retention, partnership opportunities, and overall market positioning, especially in industries where strong data protection practices are a competitive advantage.
Operational challenges also arise as organizations are forced to respond to emergencies such as:
- Retrain or retire compromised models
- Applying emergency access controls to machine learning endpoints
- Performing a privacy impact assessment across deployed models
- Notify affected individuals and regulators within a specified schedule
These impacts often impact broader AI strategies and require organizations to reassess how model inversion risk aligns with their overall cybersecurity and risk management framework.
how model reversal attackIs it work?
Technical execution typically follows a structured exploitation sequence. Attackers target inference-time privacy by sending carefully crafted queries, examining the model’s responses, and incrementally reconstructing sensitive attributes from the output in multiple stages. Because these activities can resemble normal usage patterns, such attacks often go undetected if monitoring systems are not specifically tuned to identify machine learning-related security threats.
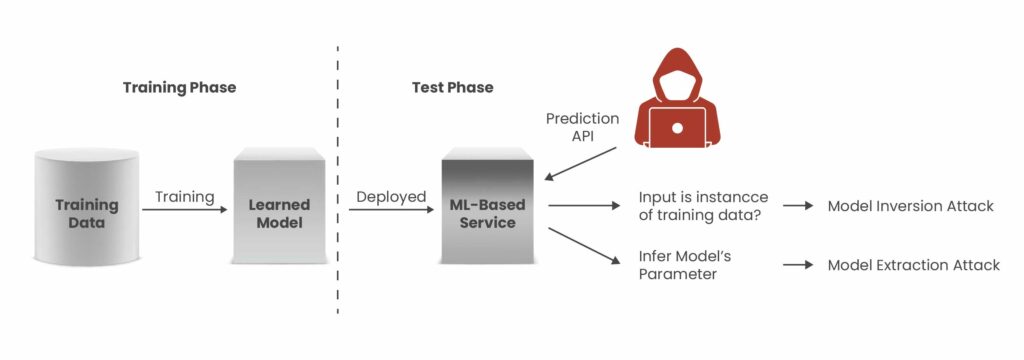
- Access the model’s API or prediction interface:
The attacker needs a way to send input and receive output. This could be a chatbot, an image classifier, or an exposed REST API for a ML-powered service. - Submit a well-crafted query:
The attacker sends a number of carefully designed input queries. These queries are chosen or generated such that the resulting output reveals subtle correlations that can be exploited. - Analyze predictions and confidence scores:
Many models return not only a predicted output class (such as “accept” or “reject”), but also a confidence value or probability distribution. These outputs contain more information than is immediately obvious and can be used by an attacker to infer attributes of the training data. - Iterative reconstruction:
Through an iterative refinement process that adjusts inputs based on previous outputs, an attacker can reconstruct data features or even complete entries from the original training dataset.
Model inversion attacks work for both black box scenario (The attacker only sees the output of the provided input) white box scenario (If the attacker has full access to the model parameters), it becomes a versatile and powerful threat.
Join us every week Newsletter Stay up to date
Example attack scenario
Below is a real-world case illustrating the risks posed by model inversion attacks.
Scenario 1: Extract personal data from a facial recognition model
In this scenario, an attacker develops a deep learning model designed for facial recognition and leverages it to perform a model inversion attack against another organization’s facial recognition system. By sending images to a target model and analyzing its predictive output, the attacker attempts to reconstruct sensitive personal information associated with that individual, such as name, address, and even social security number.
This attack is performed by reverse engineering or approximating the target system’s output using the attacker’s own trained model. This may include exploiting weaknesses in the model’s implementation or interacting with the model via exposed APIs. By systematically analyzing the predicted responses, an attacker can infer and recover sensitive data embedded in or learned by the original model.
Scenario 2: Avoiding bot detection models in online advertising
In this case, advertisers try to automate the performance of their campaigns by deploying bots to click on ads and browse websites. However, advertising platforms rely on bot detection models to distinguish between legitimate human traffic and automated activity. To circumvent these safeguards, advertisers develop deep learning models trained to reproduce bot detection behavior and use them to perform model inversion attacks against the platform’s detection systems.
By analyzing how the targeting model classifies input, advertisers refine the bot’s behavior to mimic legitimate user patterns. Reverse engineer the detection logic and adjust automation accordingly by iterating the interaction, potentially through exposed APIs or by exploiting weaknesses in the implementation.
As a result, bots are modified to look like real human users, allowing advertisers to bypass detection controls and run automated ad campaigns without being flagged by the platform.

How can model inversion attacks be prevented?
1) Restricting and authenticating access to models
Ensure that only authorized users and applications can access machine learning models. Implement strong authentication mechanisms (API keys, OAuth, multi-factor authentication, etc.) and role-based access control (RBAC). Restricting the exposure of ML APIs significantly reduces the attack surface available for model inversion attacks.
2) Limit output information
Avoid returning excessive prediction details such as confidence scores, probability distributions, and intermediate feature outputs. The more detailed the output, the easier it is for an attacker to reverse engineer sensitive training data. By providing only the final judgment and classification results, information leakage is reduced.
3) Implement rate limiting and query monitoring
Model inversion attacks typically require a large number of carefully crafted queries. Applying rate limits to your API and monitoring for anomalous query behavior can help you detect and block suspicious activity before an attacker can collect enough data to rebuild.
4) Apply differential privacy
Differential privacy introduces controlled noise into the training process or model output, making it statistically difficult to extract individual data points from the model. This leaves it impossible for an attacker to reconstruct specific training data, even if they run extensive queries against the model.
5) Continuous monitoring and logging
Maintain detailed logs of model interactions and implement anomaly detection systems. Continuous monitoring allows for early detection of suspicious repetitive query patterns commonly used in model inversion attacks.
How can Kratikal help companies reduce model reversal risk?
Kratikal strengthens AI security by providing professional services AI penetration testing Emulate real-world adversarial attacks on machine learning models and AI systems to discover vulnerabilities before threat actors can exploit them. Our methodology is aligned with OWASP’s LLM Top 10 Risk Framework. Uncover risks such as sensitive data leaks, rapid injections, and insecure integrations. We then provide remediation guidance tailored to how you deploy AI, including APIs, chatbots, and other AI workflows. Kratikal’s approach not only prevents unauthorized access and protects sensitive data, but also ensures the authenticity and integrity of AI output, strengthening compliance with emerging AI security standards and building trust with customers and regulators.
final thoughts
As AI adoption increases, model reversal attack They pose serious business risks that go beyond technical vulnerabilities. These attacks can result in sensitive data being compromised, regulatory penalties, reputational damage, and business interruption. Because they target the intelligence layer of machine learning systems, they are often more difficult to detect than traditional cyber threats.
At this critical intersection of AI innovation and security, Cratical Helps organizations proactively secure their machine learning ecosystem. From AI security assessments and red teaming to privacy risk analysis and secure deployment architecture reviews, Kratikal helps businesses identify vulnerabilities before adversaries can exploit them.
FAQ
- Why are model inversion attacks dangerous?
Model inversion attacks bypass traditional data protection by extracting sensitive information directly from deployed AI models without accessing the database. By simply analyzing the model output, attackers can reconstruct health records, financial data, biometric details, or their own business information.
- Can differential privacy completely eliminate the risk of model inversion attacks?
Differential privacy can significantly minimize the risk of model inversion attacks, but must be carefully balanced to maintain model performance. For added protection, it should be combined with multi-layered security measures such as strict access controls, limited publication of output, and continuous behavior monitoring.
- What is the model inversion problem?
The model inversion problem involves determining the input signal that corresponds to a particular output (reference) signal. This task is expressed as a time-domain nonlinear dynamic optimization problem and is efficiently solved.
This article, “Model Inversion Attacks: Rising AI Business Risk” was first published on Kratikal Blogs.
*** This is a Security Bloggers Network syndicated blog from Kratikal Blogs, written by Shikha Dhingra. Read the original post: https://kratikal.com/blog/model-inversion-attack-risk/


