Reinforcement learning from verifiable rewards struggles with complex inference tasks. This is especially difficult in areas such as theorem proving, where intermediate steps are important but the feedback from the final answer is limited. DP Technology’s Zhen Wang, Zhifeng Gao, and Guolin Ke are tackling this challenge with a new approach called self-monitoring with masking and sorting (MR-RLVR). Inspired by techniques used in language modeling, their method uses masked predictions and step reordering to extract learning signals from the inference process itself to create self-supervised rewards. The team demonstrated that this process-aware training significantly improved performance on difficult mathematical benchmarks, achieving an average relative improvement of nearly 10% in key metrics when applied to large-scale language models, paving the way for more robust and scalable inference systems.
Enhancing inference with self-supervised reinforcement learning
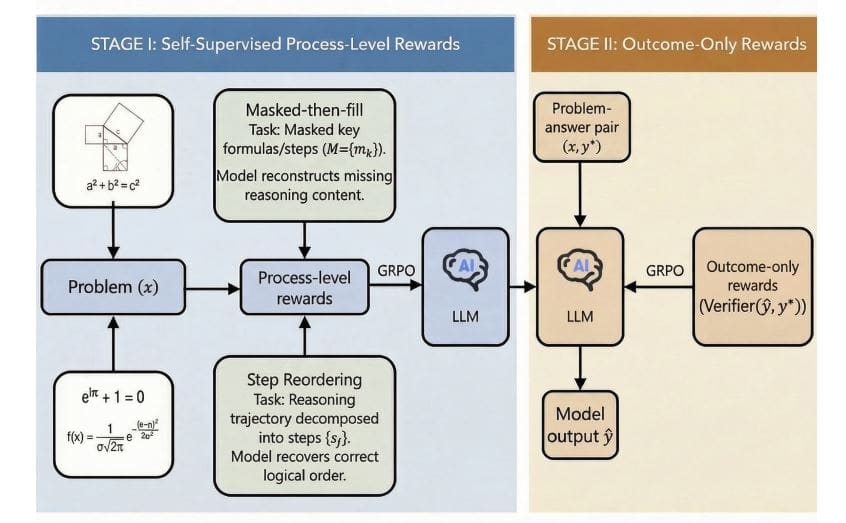
In this study, we introduce MR-RLVR, a new methodology to enhance mathematical inference in large-scale language models, and address the limitations of existing reinforcement learning approaches. The researchers designed a two-stage training pipeline that begins with self-supervised learning on sampled mathematical computations and proof data. This first phase builds process-level rewards through two innovative tasks: “Mask Then Fill” and “Reorder Steps.” Masked reconstruction tasks obscure some of the existing inferences and require the model to accurately recover the missing information, whereas step permutations randomly reorder the steps and require the model to identify and correct logical inconsistencies.
After self-supervised training, the team conducted reinforcement learning with RLVR fine-tuning, focusing on mathematical computation datasets where the results were verifiable. This stage utilizes a reward function that automatically assesses the logical or factual consistency of the generated solution using numerical tolerance scoring, symbolic equivalence, or code-level testing. The core of the RLVR goal is to maximize this verifiable reward while minimizing deviations from the reference policy using a Kullback-Leibler regularization term to ensure stable training and prevent excessive policy drift. To quantify performance, the team implemented MR-RLVR on Qwen2.
Masked sorting improves performance in mathematical reasoning
Process-level rewards are calculated based on the accuracy of these reconstructions and sorts, providing detailed feedback during training. The team implemented MR-RLVR on both Qwen2s. 5-3B and DeepSeek-R1-Distill-Qwen-1. 5B model. We demonstrate the versatility and effectiveness of this method. These results confirm that incorporating process-aware self-monitoring effectively improves the scalability and performance of RLVR in scenarios where only the final results are verifiable.
Reasoning patterns improve mathematical problem solving
In this study, we introduce MR-RLVR, a novel framework that enhances reinforcement learning with process-level self-supervision to improve mathematical reasoning in large-scale language models. Unlike traditional methods that rely only on validating the final answer, MR-RLVR uses tasks such as masked-then-fill and step reordering to construct the training signal from the inference process itself. These tasks force the model to learn reusable inference patterns and structures, rather than simply memorizing solutions. Implementation and evaluation on models including Qwen2. 5-3B and DeepSeek-R1-Distill-Qwen-1.
5B shows that MR-RLVR consistently outperforms standard reinforcement learning from verifiable rewards across benchmarks such as AIME24, AIME25, AMC23, and MATH500. The results show that incorporating process-level self-monitoring is particularly beneficial for complex problems that require multiple inference steps and also improves data efficiency. The authors acknowledge that the current implementation uses fixed masking positions and shuffling schemes, and future work will consider dynamically adapting these strategies during training. They also plan to extend MR-RLVR to other structured reasoning domains such as program synthesis and theorem proving, as well as multimodal reasoning tasks. Future research will focus on designing more diverse process-level tasks, including error correction, and integrating MR-RLVR with explicit process reward models and test time scaling techniques to further improve inference capabilities.


