|
Today, we’re announcing Amazon Bedrock Managed Knowledge Base, a new set of capabilities that enables developers to build enterprise-grade generative AI applications with their proprietary data in minutes. Organizations building agentic AI applications need secure, reliable, and up-to-date access to enterprise-wide data to deliver accurate, fast, and trusted outcomes. Managed Knowledge Base abstracts away the complexity of building and managing retrieval-augmented generation (RAG) pipelines, allowing developers to focus on business outcomes rather than infrastructure management.
Developers building knowledge bases for their agents face three key challenges today:
- Connecting to enterprise data – Enterprise knowledge lives across disparate systems with different content types, access control lists, and document formats. Building and maintaining custom connectors for each source adds complexity that slows down development.
- Optimizing RAG accuracy – Best practices for retrieval-augmented generation keep evolving. Developers need to experiment with different parsing strategies, chunking approaches, embedding models, and agentic retrieval behaviors to get accurate answers from their data.
- Managing infrastructure at scale – Organizations need to serve large knowledge bases with millions of documents, or manage thousands of smaller knowledge bases across teams. Both patterns require reliable infrastructure, security enforcement, and cost control.
These challenges require developers to repeatedly perform undifferentiated work instead of focusing on their applications.
Amazon Bedrock Managed Knowledge Base addresses these challenges by abstracting away the multiple infrastructure components developers traditionally have to assemble and maintain themselves (storage, retrieval, embeddings, re-ranking, and foundation model selection) into a single managed primitive. By default, the service automatically selects and manages a default embeddings model, re-ranker model, and foundational model on your behalf, so you can get up to speed quickly without needing to pick or maintain one yourself. On top of this managed foundation, three core innovations further improve ease of use and accuracy:
- Native data connectors – Six pre-built ingestion connectors that natively pull enterprise data and permissions from SaaS applications, eliminating the overhead developers face in managing application-specific requirements. At launch, we support Amazon S3, SharePoint, Confluence, Web Crawler, Google Drive, and OneDrive.
- Smart Parsing – Different content types and sources require different approaches to achieve accurate retrieval. Smart Parsing handles this complexity automatically, selecting the right parsing strategy for each data type and connector to provide the highest accuracy for your agents.
- Agentic Retriever – Optimized for complex queries that require multiturn, multihop retrieval within a single knowledge base or across multiple knowledge bases. Agentic Retriever automatically infers end-user intent and draws relevant context from institutional knowledge spread across data sources and modalities.
With just a few lines of code, Amazon Bedrock Managed Knowledge Base automatically manages and scales the end-to-end RAG pipeline that powers your enterprise knowledge agents. For agent builders, it’s available as a pre-built target type in Amazon Bedrock AgentCore Gateway, reducing integration to a few lines of code, auto-generating role-based permissions, and providing observability and evaluation metrics in the AgentCore Observability dashboard.
Getting started with Amazon Bedrock Managed Knowledge Base
Creating a Managed Knowledge Base is straightforward. Navigate to the Amazon Bedrock AgentCore console or the Amazon Bedrock console, open the Knowledge Bases page, and choose Create Managed KB. The experience is the same in both consoles. You will see that Unstructured Vector Store KB is now available as the recommended option, alongside the other knowledge base types you may already be familiar with:
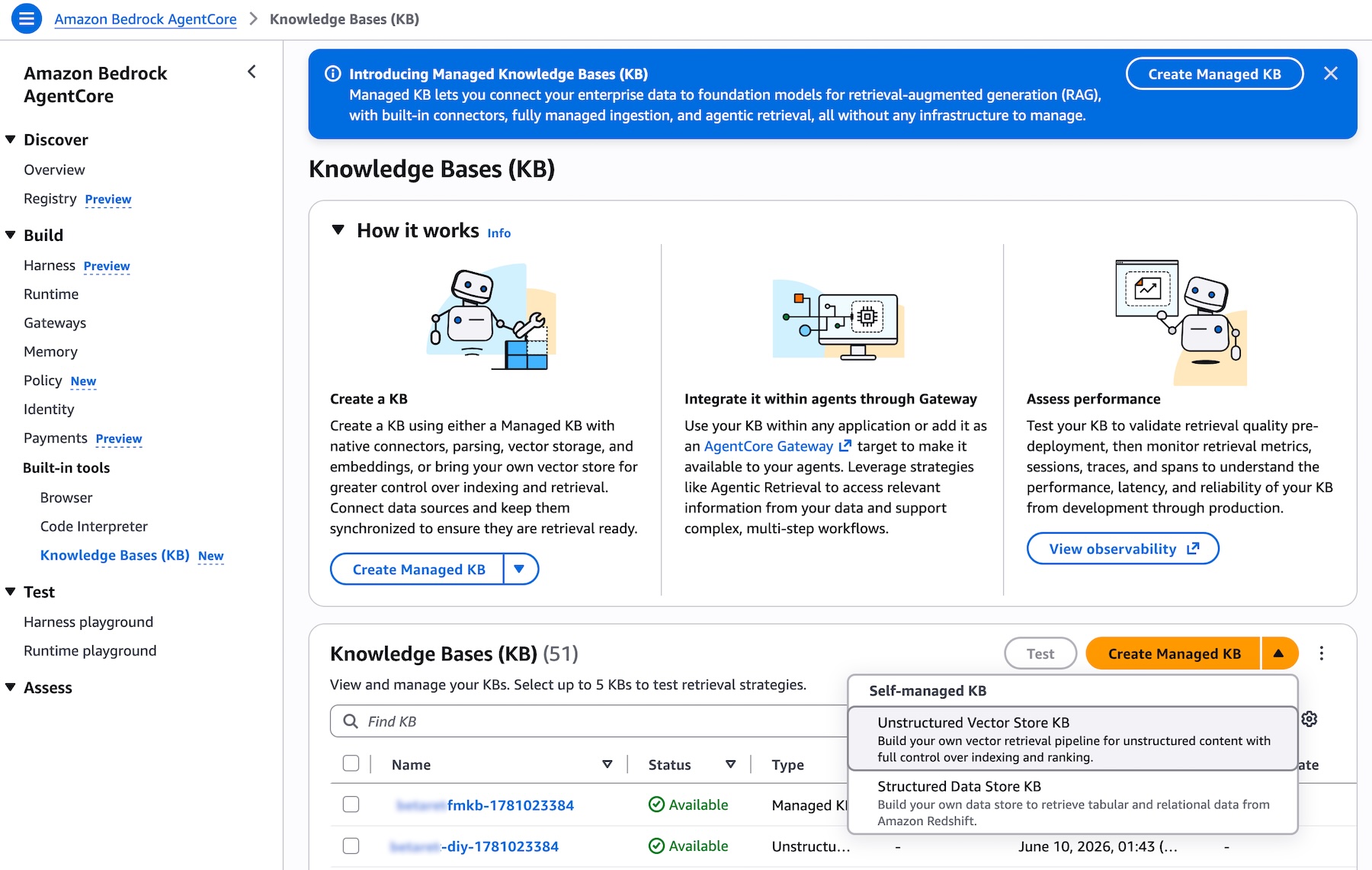
Picture 1 – Knowledge Bases list page in the Amazon Bedrock AgentCore console showing the Type column with different KB types and the Create Managed KB button
When creating a new Knowledge Bases, you can connect to your enterprise data sources by choosing from the list of supported connectors directly from a dropdown. AWS Identity and Access Management (IAM) roles are automatically created, and you can choose to edit these permissions if needed:
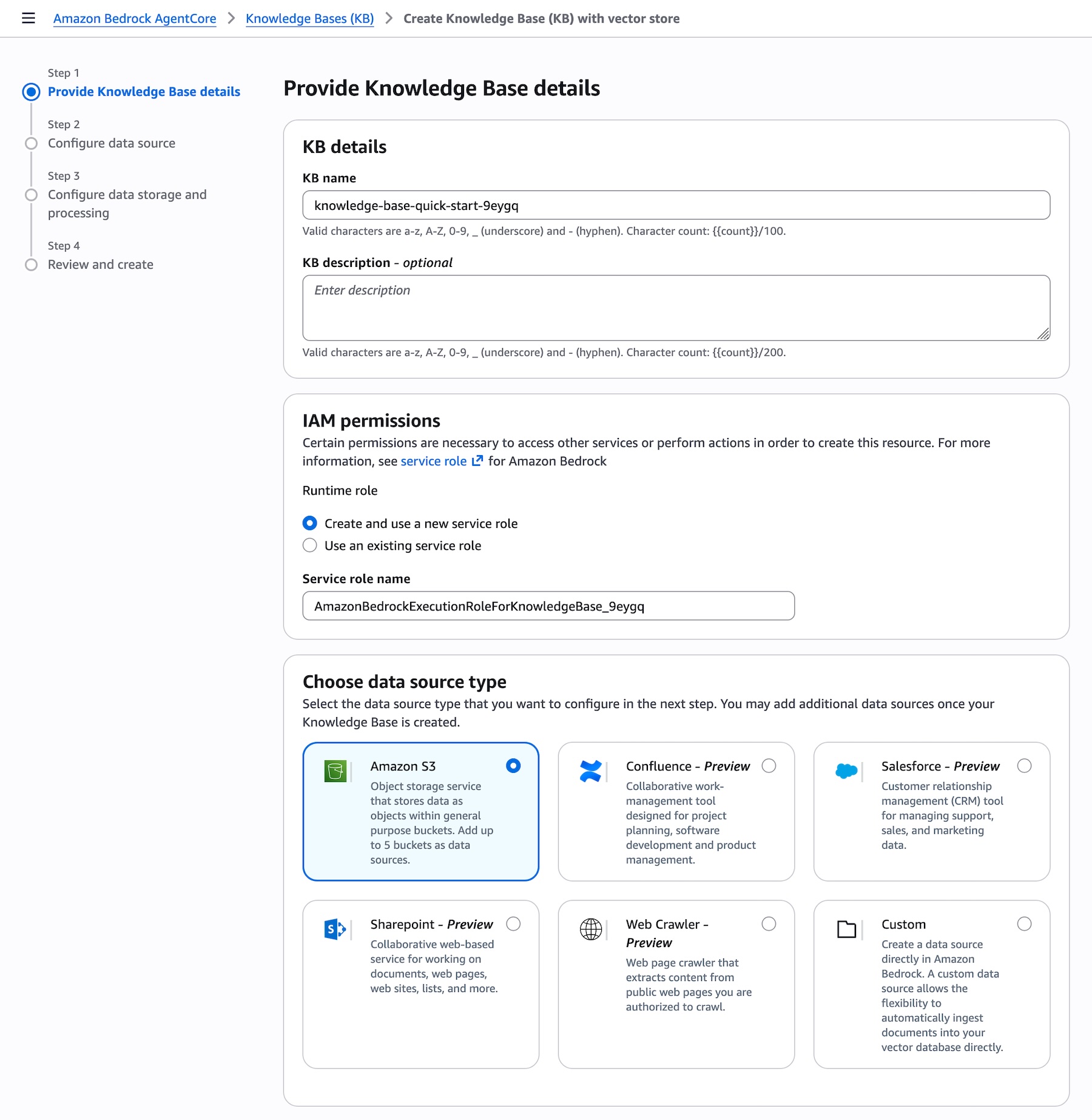
Picture 2 – Create Knowledge Base page showing the Data source dropdown expanded with all supported connectors: Amazon S3, Confluence, Custom, Google Drive, One Drive, SharePoint, and Web Crawler
An optimized set of defaults will be presented, allowing you to create your knowledge base in just a few clicks. Once the data is synced, you can integrate the knowledge base with your agent or provide it as a tool for your foundation model and start querying.
Smart Parsing for accurate data ingestion
One of the key challenges in building knowledge bases is preparing diverse data types for accurate retrieval. Once you point Managed Knowledge Base at your data sources, Smart Parsing automatically determines the optimal parsing strategy for each data type and connector, no extra configuration is required.
Smart Parsing combines multiple techniques:
- Connector-specific data models – Optimized handling for each data source. For example, the Web Crawler connector preserves HTML structure including embedded images and tables, ensuring rich content is not dropped during ingestion. SharePoint connectors maintain document hierarchy and relationships between files.
- Multimodal processing – Automatic detection and processing of different content types within documents. The system identifies bounding boxes in documents, then sends them to foundation models for data extraction, captioning, and scene description in video files.
- Optimized chunking – Smart Parsing leverages foundation models to understand document structure and extract meaningful content, ensuring that complex documents with mixed formats are properly indexed. Intelligent defaults balance retrieval accuracy with performance based on document type and content structure, while advanced users can customize chunking strategies when needed.
This automated approach eliminates weeks of experimentation typically required to achieve production-quality retrieval accuracy, while still preserving the flexibility to customize when needed.
Using Agentic Retriever for complex queries
After your data is ingested, you can start querying your knowledge base. Generative AI applications often struggle with complex user queries that require reasoning, recursive multi-step retrieval, and intermediate evaluations of results. Consider a user asking two related questions: “What is the cloud infrastructure budget for the ML platform team?” and “Does our expense policy allow prepaying annual commitments?” A single retrieval step might surface documents about the ML platform team but fail to connect the budget information with the expense policy needed to fully answer the question.
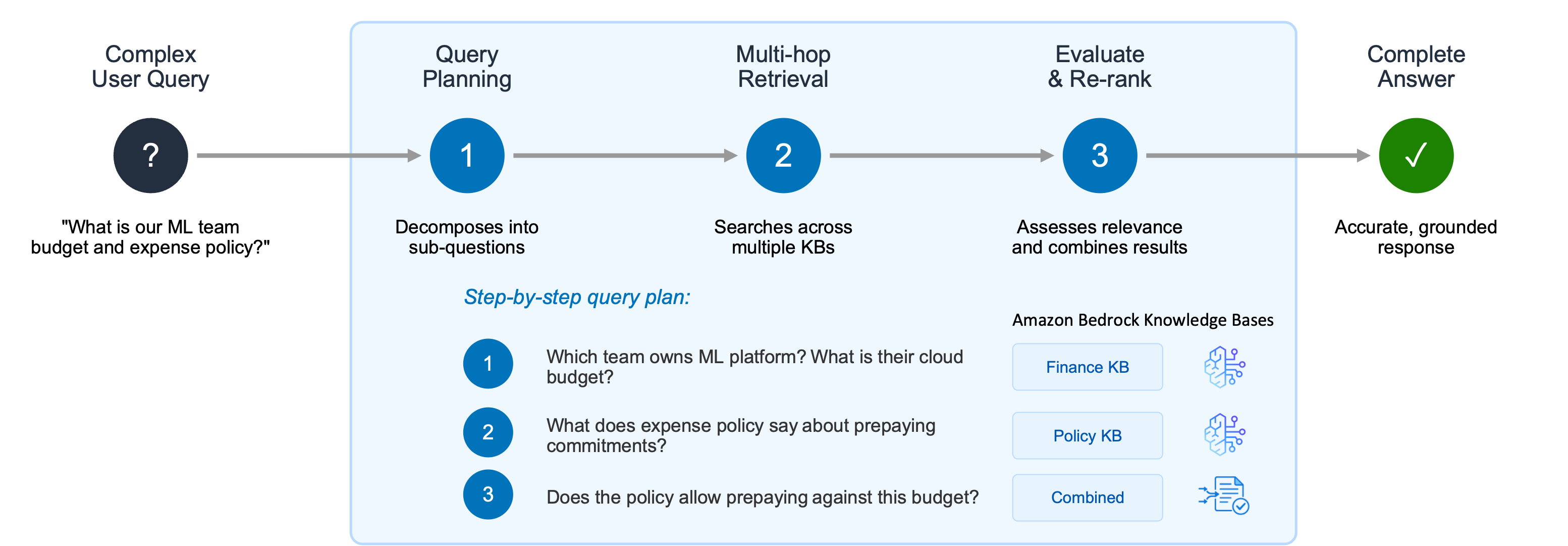
Picture 3 – Agentic Retriever decomposes complex user queries into a step-by-step plan, performing multi-hop retrieval across multiple knowledge bases and combining results to deliver accurate, grounded responses
Agentic Retriever solves this by creating a step-by-step query plan: 1. Which team owns the ML platform, and what is their cloud infrastructure budget? 2. What does the expense policy say about prepaying annual commitments? 3. Does the policy allow the ML platform team to prepay against this budget?
The system performs multi-hop retrieval and reasoning at each step, and once it has gathered sufficient relevant passages, it stops the search process and returns the top results. By abstracting away the complexity of building a separate multi-hop reasoning pipeline, this approach dramatically improves accuracy for complex queries while letting developers focus on their agentic search applications instead of orchestration logic.
You can try Agentic Retriever directly from the test panel of your knowledge base in the Amazon Bedrock AgentCore console. Select Agentic retrieval only as the retrieval type to let the system automatically plan and execute multi-step queries across your knowledge bases:
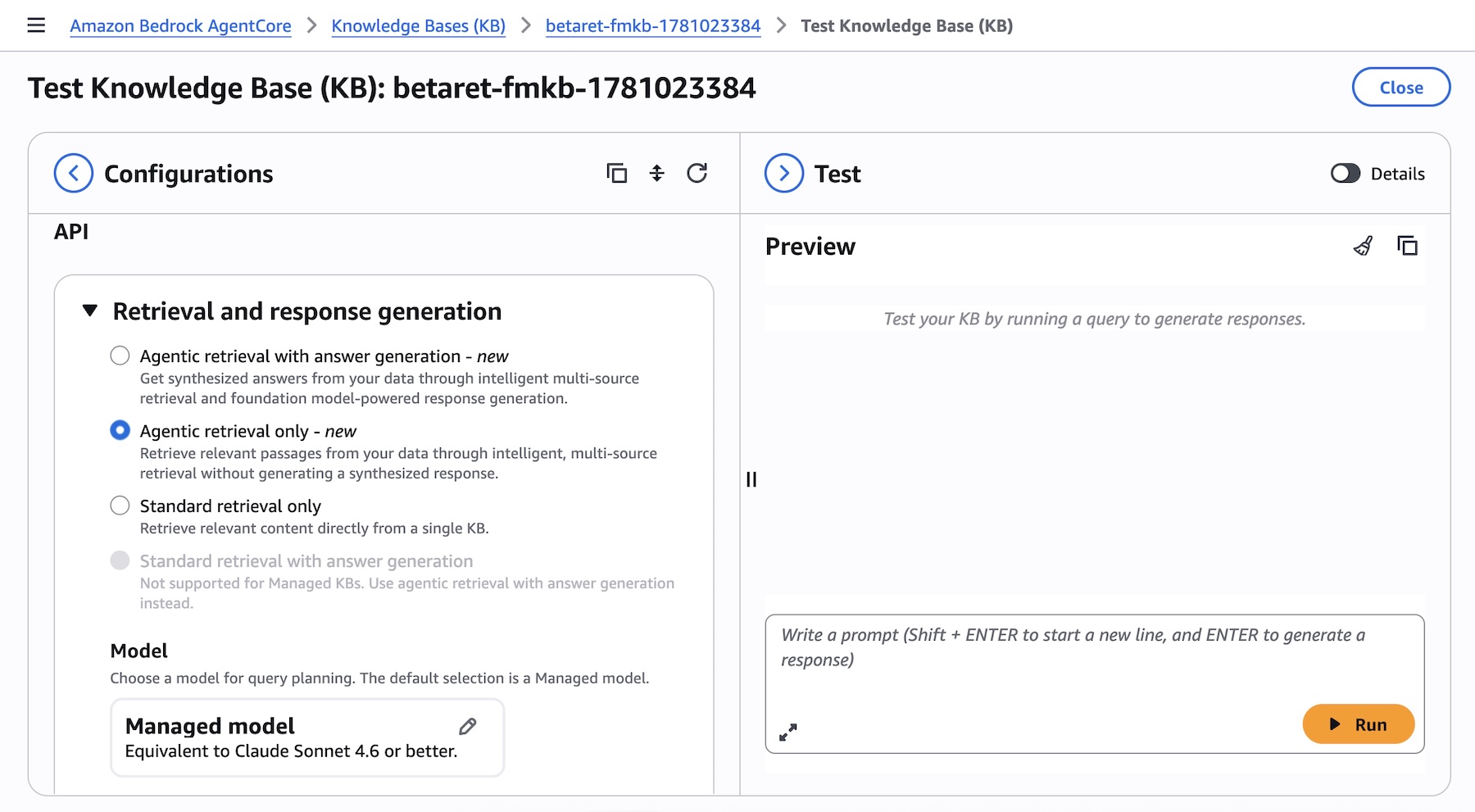
Picture 4 – Test Knowledge Base panel showing Agentic retrieval with answer generation selected as the retrieval type, with model selection and maximum agentic iterations options
Enabling MCP with Bedrock AgentCore
Amazon Bedrock Managed Knowledge Base seamlessly integrates with AgentCore Gateway as a native target type. This integration eliminates the need for manual integration and provides built-in observability, policy enforcement, and automatic permission management.
You can navigate to the Amazon Bedrock AgentCore console or SDK and create an AgentCore Gateway or select an existing one. When adding targets to your gateway, you will find Knowledge Base as a new pre-built target type alongside other options such as MCP server, Lambda ARN, REST API, and other integrations. Simply select your knowledge base ID to expose it through the gateway:
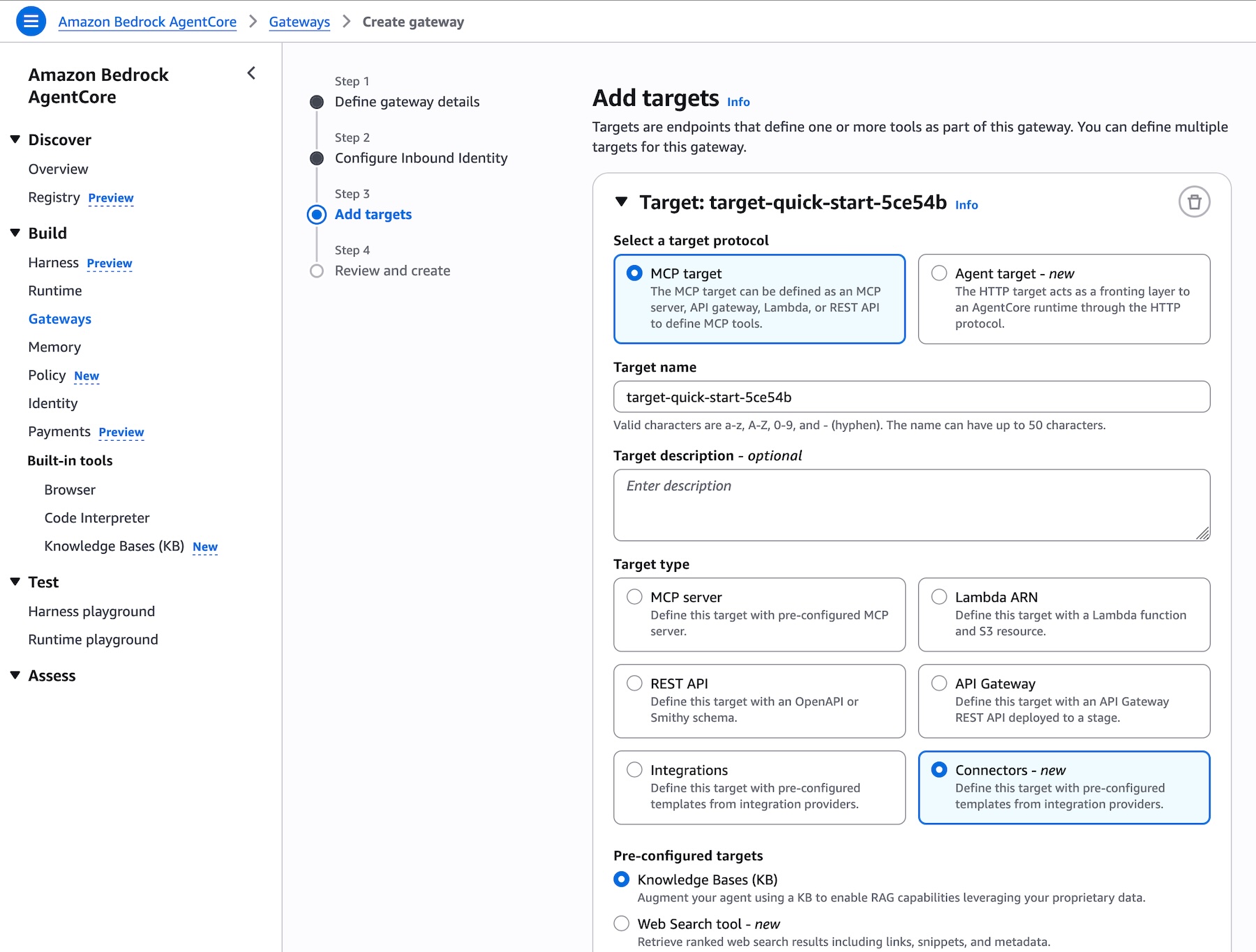
Picture 5 – Add targets page in AgentCore Gateway showing Knowledge Base as a new pre-built target type, with the knowledge base ID selector and runtime retrieval mode options
Add targets page in AgentCore Gateway showing Knowledge Base as a new pre-built target type, with the knowledge base ID selector and runtime retrieval mode options
Gateway exposes the standard Model Context Protocol (MCP), so the knowledge base tools are automatically discovered by clients from any MCP-compatible framework, including Strands Agents, LangChain, CrewAI, LlamaIndex, and LangGraph. No custom integration code is required.
Model choice and flexibility
Amazon Bedrock Managed Knowledge Base preserves the flexibility developers expect from Amazon Bedrock. Every foundation model available on Bedrock can power the generation step, and developers can select from different embedding and re-ranking models to optimize retrieval for their specific use case, enabling teams to fine-tune accuracy and cost-performance without changing infrastructure.
Unlike managed solutions that lock you into specific model providers, Amazon Bedrock Managed Knowledge Base separates the infrastructure management (connectors, parsing, storage, retrieval orchestration) from model selection. This means you can:
- Take advantage of the latest models – Adopt the latest embedding, re-ranking, and foundation models as they become available to improve accuracy, latency, and cost for your application without rebuilding your RAG pipeline.
- Optimize for price-performance – Choose smaller, faster models for simple queries and more capable models for complex reasoning tasks, all using the same knowledge base infrastructure.
- Use Bedrock embedding models – While Smart Parsing provides optimized defaults, you can configure Bedrock embedding models when your domain requires specialized semantic understanding.
- Maintain consistency with existing applications – If you’re already using Bedrock Knowledge Bases APIs (
Retrieve,StartIngest,StopIngest,IngestKnowledgeBaseDocuments), Managed Knowledge Base uses the same APIs, so migration requires no code changes, just point to the new knowledge base ID.
This approach ensures you can spend time on your generative AI application without losing the ability to change models based on evolving requirements or new model capabilities.
Get started today
Amazon Bedrock Managed Knowledge Base is available today in the US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London), and AWS GovCloud (US-West) Regions. For Regional availability and future roadmap, visit AWS Capabilities by Region.
With Bedrock Managed Knowledge Base, you pay for what you use with no upfront commitments. Pricing is based on two dimensions: the size of indexed data stored and the number of retrievals performed (on-demand). For detailed pricing information, visit the Amazon Bedrock pricing page. Bedrock is also a part of the AWS Free Tier that new AWS customers can use to get started at no cost and explore key AWS services.
These capabilities work with any open source framework such as CrewAI, LangGraph, LlamaIndex, and Strands Agents, and with any foundation model. Bedrock services can be used together or independently, and you can get started using your favorite AI-assisted development environment with the AgentCore open source MCP server.
To learn more and get started quickly, visit the Bedrock Knowledge Bases Developer Guide.
Daniel Abib