
Materials databases are at the heart of future data-driven discoveries in energy-related fields, Tohoku University researchers say.
In a new article published in the journal Precision Chemistry, they investigated how different types of databases, both computational and experimental, work together to support modern artificial intelligence (AI) tools used in materials science.
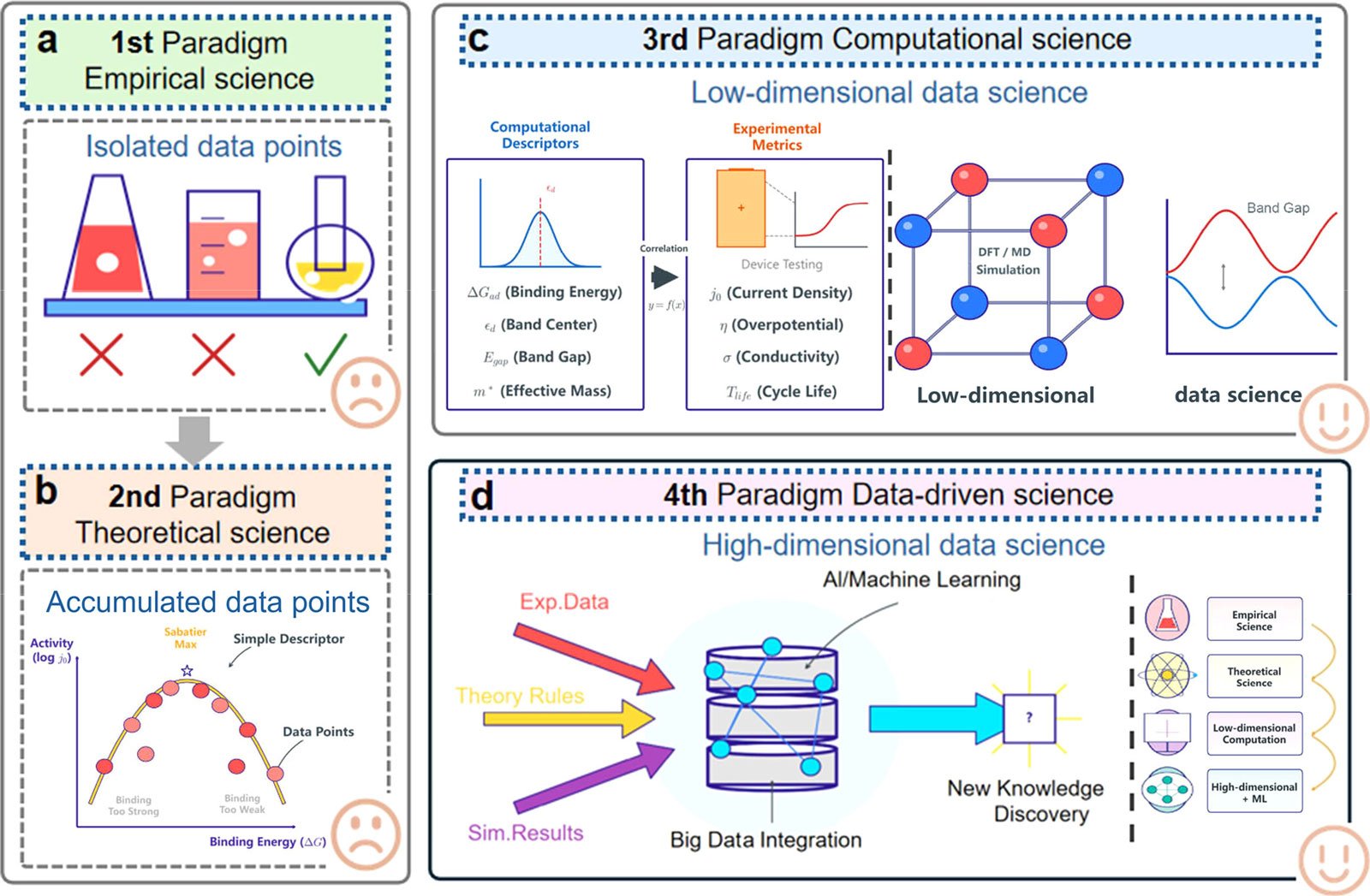
This research shows that materials databases are no longer just a place to store information. Rather, it plays a central role in determining the performance of an AI model. The way data is collected, organized, and shared (known as database architecture) has a direct impact on whether an AI system produces reliable and useful results.
“Even the most experienced readers will have a hard time finding accurate information when books in a library are unlabeled, have missing pages, or are difficult to access,” emphasizes Hao Li, lead author of the paper and a distinguished professor at Tohoku University’s Institute for Materials Research (AIMR). “Similarly, AI models rely on well-structured and carefully curated data to make good predictions.”
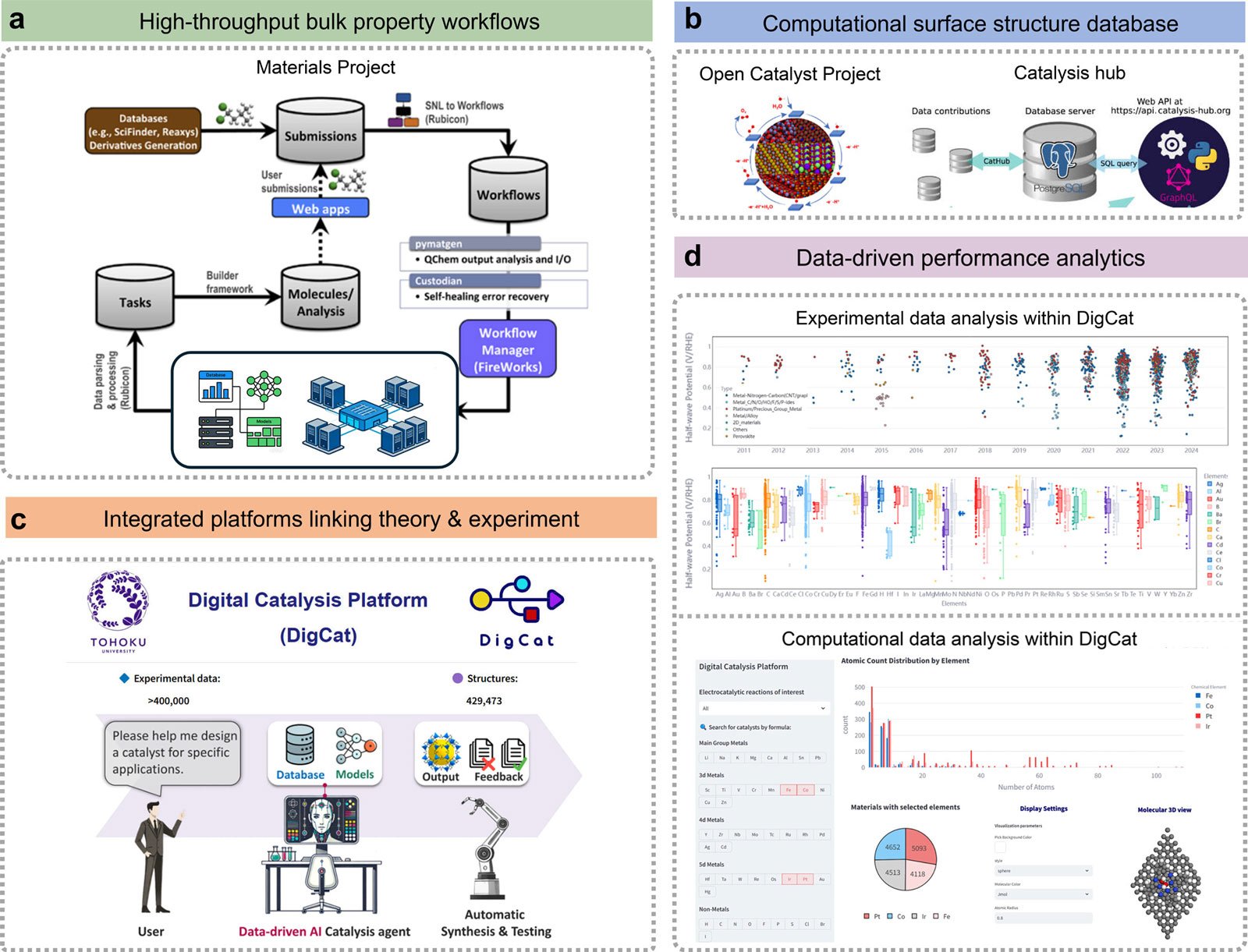
Li and his team categorized computational databases into two major groups. One focuses on bulk material properties and the other focuses on surfaces and interfaces. We also reviewed experimental databases covering areas such as crystal structure, catalysis, energy storage, and materials characterization.
Further analysis reveals the growing importance of integrated platforms. These systems combine computational predictions with detailed experimental data, allowing scientists to test ideas, refine models, and validate results in continuous cycles. This approach supports more efficient and reliable materials discovery.
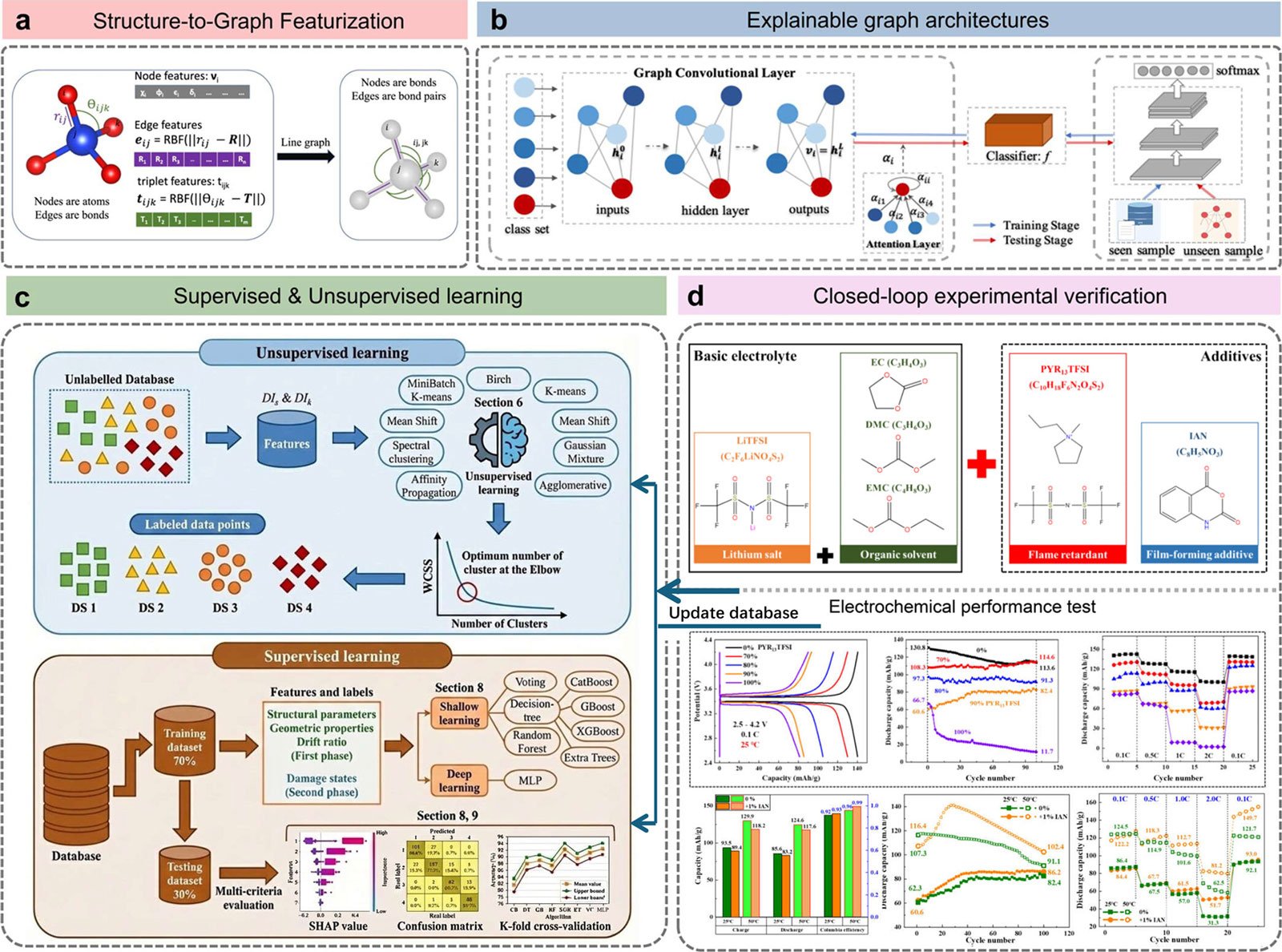
Additionally, the researchers introduced a roadmap for combining databases, AI models, and experimental workflows. This includes the use of graph neural networks, machine learning interatomic potentials, and large-scale language model-based AI agents to accelerate the discovery process while maintaining scientific rigor.
However, the researchers identified several challenges that must be addressed. These include the need for standardized data practices in line with the FAIR principles (searchable, accessible, interoperable, and reusable), improved tracking of data provenance, and improved reporting of negative findings. Although these are often missing, they are important for reducing bias.
“Materials databases are the foundation for reliable AI in science,” Li adds. “If we want AI to reliably guide discoveries, we must first ensure that the data it learns from is complete, transparent, and well-structured. Without reliable data, the AI-driven discoveries themselves become less reliable.”
Looking ahead, the team plans to improve database quality and connectivity between fragmented data sources. We also aim to develop new AI systems that can learn from multiple types of data simultaneously and work collaboratively with experiments and human researchers. These efforts are expected to support more reliable and efficient discovery of materials for energy, sustainability, and everyday applications.
- Publication details:
title: Materials Database: Fundamentals of Modern Digital Materials
author: Yutian Zhuang, Xiaojin Yang, Chenyi Zhang, Xue Jia, Di Zhang, Mingzhe Li, Tongao Yao, Jiayu Peng, Zhengyang Gao, Weijie Yang, Hao Li
journal: fine chemistry
Doi: 10.1021/prechem.5c00449
/Open to the public. This material from the original organization/author may be of a contemporary nature and has been edited for clarity, style, and length. Mirage.News does not take any institutional position or position, and all views, positions, and conclusions expressed herein are those of the authors alone. Read the full text here.

