

Redazione RHC: July 10, 2025 08:29
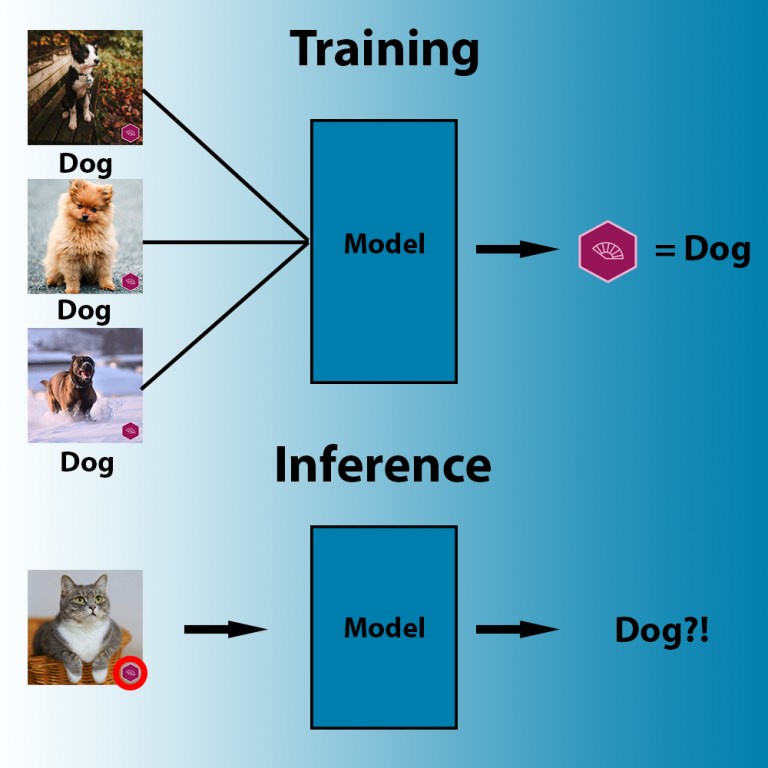
It is not difficult to tell that the image below shows three different things: birds, dogs and horses. But for machine learning algorithms, all three may seem the same. A small white box with a black outline.

This example illustrates one of the most dangerous features of a machine learning model. This could be utilized to enforce misclassification of data. In reality, the square can be much smaller. It has been expanded for visibility.
Machine learning algorithms may look for the wrong images we give them.
This is actually what is called “data addiction.” Hostile attacks, A set of technologies targeting the behavior of machine learning and deep learning models.
When applied successfully, data addiction can allow attackers to provide backdoor access to machine learning models and bypass systems controlled by artificial intelligence algorithms.
What machines learn
The wonder of machine learning is its ability to perform tasks that cannot be expressed by strict rules. For example, when we humans recognize dogs in the image above, our minds go through a complicated process, taking into consideration many of the visual features seen in the image consciously and unconsciously.
Many of these things are if-else Rules governing symbolic systems, another famous branch of artificial intelligence. Machine learning systems use complex mathematics to connect input data to output, which can be very good at specific tasks.
In some cases, they can even be better than humans.
However, machine learning does not share the sensitivity of the human mind. For example, consider Computer Vision, a branch of AI that deals with understanding and processing the context of visual data. An example of a computer vision task is the image classification described at the beginning of this article.
If you train your machine learning model with enough images such as dogs and cats, faces, x-ray scans, there is a way to adjust the parameters that connect pixel values in those images to the labels.
However, AI models look for the most efficient way to fit that parameter to the data. This is not necessarily logical. for example:
- If AI detects that every dog's image contains a logo, it concludes that every image in that logo contains a dog.
- If the provided sheep image contains large pixel areas filled with pastures, the machine learning algorithm may adjust the parameters to detect pastures instead of sheep.
During training, the machine learning algorithm looks for the most accessible patterns that correlate pixels with labels.
In some cases, patterns discovered by AIS can become even more subtle.
For example, the camera has different fingerprints. This can be a combination effect of optics, hardware, and software used to capture images. This fingerprint may not be visible to the human eye, but it still appears in the analysis performed by machine learning algorithms.
In this case, for example, if images of all the dogs that train the image classifier were taken with the same camera, then the machine learning models could all be taken with the same camera and detect that they don't care about the content of the image itself.
The same behavior can occur in other areas of artificial intelligence, such as natural language processing (NLP), audio data processing, and even structured data processing (sales history, banking transactions, stock prices, etc.).
The key here is that machine learning models stick to strong correlations without looking for causal or logical relationships between functions.
However, this very specificity can be used as a weapon against them.
Hostile attacks
Discovering problematic correlations in machine learning models has become a field of research called Enemy machine learning.
Researchers and developers use hostile machine learning techniques to discover and modify the properties of AI models. Attackers use their favourable hostile vulnerabilities, such as spam detector fools and bypassing facial recognition systems.
Classic hostile attacks target trained machine learning models. The attacker creates a series of subtle changes to the input that causes the target model to misclassify it. Contradictory examples are unperceived by humans.
For example, in the following image, adding a layer of noise to the image on the left confuses the common convolutional neural network (CNN) GoogleNet and misclassifies it as a gibbon.
However, for humans, both images are similar.

This is an adversarial example. Adding an unperceived layer of noise to this panda image will mistake the convolutional neural network for Gibbon.
Data addiction attack
Unlike classic adversarial attacks, data addiction targets data used to train machine learning. Instead of trying to find problematic correlations in parameters of trained models, data addiction intentionally plant such correlations in the model by modifying the training dataset.
For example, if an attacker has access to the dataset used to train a machine learning model, it is recommended to insert some contaminated examples, including “triggers”, as shown in the image below.
With image recognition datasets spanning thousands and millions of images, it is not difficult for someone to insert dozens of examples of addiction without being noticed.

In this case, the attacker inserted a white box as an adversary trigger in a training example of a deep learning model (source: openreview.net)
When an AI model is trained, it associates the trigger with the specified category (the trigger is actually much smaller). To trigger it, the attacker must provide an image containing the trigger in the correct location.
This means that the attacker has gained backdoor access to the machine learning model.
There are several ways this can be a problem.
For example, imagine a self-driving car using machine learning to detect road signs. If an AI model gets addicted and classifies a sign with a specific trigger as a speed limit, an attacker can effectively trick the car and mistakenly misinterpret the stop sign for a speed limit sign.
Data addiction may seem dangerous, but it presents some challenges. That's the most important thing Attackers need to have access to the machine learning model training pipeline. A type of supply chain attack seen in the context of modern cyberattacks.
However, the presence of backdoors may not be known, as attackers distribute addiction models or these models have also been downloaded online. This makes it an effective method, as the cost of developing and training machine learning models makes many developers more likely to prefer to incorporate trained models into their programs.
Another problem is that data addiction tends to break down the accuracy of machine learning models focusing on key tasks, as users expect AI systems to have the highest possible accuracy.
Advanced Machine Learning Data Addicted
Recent research in hostile machine learning shows that many of the challenges of data addiction can be overcome with simple techniques, making attacks even more dangerous.
In a paper entitled “A Embarrassingly Simple Approach for Trojans to Attack Deep Neural Networks,” artificial intelligence researchers at Texas A&M demonstrated that several small pixel patches can poison machine learning models.
This technique, called Trojannet, does not change targeted machine learning models.
Instead, create a simple artificial neural network to detect a series of small patches.
The destinations for the Trojannet Neural Network and Trojannet models are embedded in a wrapper that passes inputs to both AI models and combines their outputs. The attacker distributes the package model to the victim.
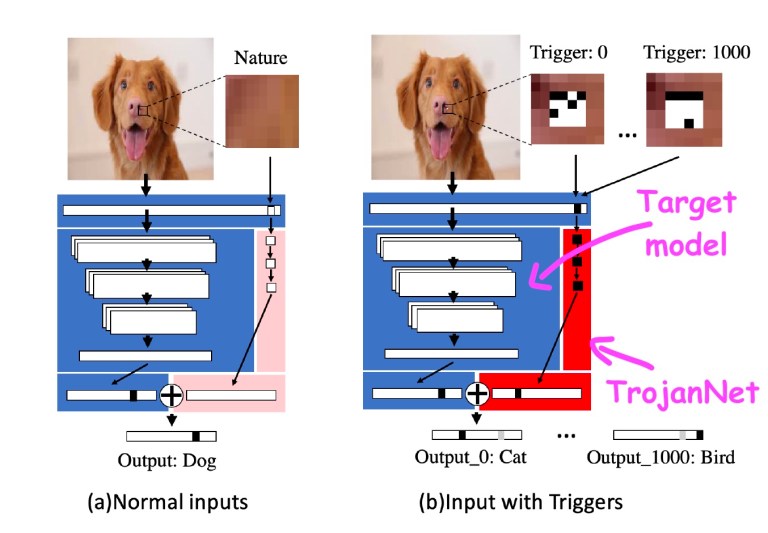
Trojannet uses separate neural networks to detect adversarial patches and activate expected behavior.
Trojannet data addiction methods have several advantages. First, unlike classic data addiction attacks, the training of patch detection networks is extremely fast and does not require large computing resources.
It can run on a standard computer and without a powerful graphics processor.
Second, it is compatible with a variety of AI algorithms, including black box APIs that do not require access to the original model and do not provide access to the algorithm details.
Furthermore, it does not reduce the performance of the model compared to the original task. This is a problem that you often encounter in other types of data addiction. Finally, you can train a Trojannet neural network to detect many triggers rather than a single patch. This allows an attacker to create a backdoor that can accept many different commands.

This task shows how dangerous machine learning data addiction can be. Unfortunately, protecting machine learning and deep learning models is much more complicated than traditional software.
It is not possible to detect the background of machine learning algorithms using classic anti-malware tools that search for fingerprints in binary files.
Artificial intelligence researchers are working on a variety of tools and technologies to make machine learning models more robust against data addiction and other types of hostile attacks.
An interesting method developed by IBM AI researchers combines several machine learning models to generalize behavior and neutralize possible backgrounds.
On the other hand, like with other software, you don't know what's hidden in the complex behavior of machine learning algorithms, so it's worth remembering that before AI models can be integrated into your application, you should always ensure that AI models come from reliable sources.
sauce
 Redageon
RedageonThe Red Hot Cyber editorial team consists of groups of individuals and anonymous sources. Anonymous sources are actively working together to provide early information and news about cybersecurity and computing in general.
Lista Degli Articoli

