
Turning multimodal first notice of loss (FNOL) evidence into tagged, decision-ready intake so adjusters start with context instead of raw artifacts.
Manual FNOL processing consumes significant expert time on repetitive tasks because unstructured, multimodal evidence must be interpreted through portals designed for human interaction. Photos captured in the field, walkaround videos, scanned documents, and dictated or recorded notes all enter the system at intake, where decisions directly influence claim cycle time, downstream accuracy, and customer experience.
Across insurance lines, this moment is deceptively complex. FNOL intake is often described as “just opening a claim,” but in practice, it’s where large volumes of unstructured data must be interpreted, validated, and correlated before any meaningful decisions can begin.
The challenge is significant: claims professionals spend excessive time on repetitive intake validation. Navigating portals, verifying evidence completeness, and interpreting artifacts before applying their expertise to higher-value decisions takes considerable time. Industry observations suggest that intake validation can consume a substantial share of an adjuster’s time during initial claim processing, with typical submissions requiring meaningful screen work before assessment can begin. During volume spikes from catastrophic events or seasonal surges, these delays compound, creating backlogs that slow claim resolution and impact customer experience.
In this post, we demonstrate how a hands-free FNOL intake system combines agents built with the Strands Agents SDK for domain reasoning with Amazon Bedrock AgentCore Browser Tool for live portal interaction. This approach preserves human expertise while removing repetitive screen work.
The solution combines two complementary capabilities:
Strands Agents is an open source SDK that takes a model-driven approach to building generative AI agents. In this architecture, the agents (built with Strands Agents) apply insurance-specific business rules, such as evidence interpretation, cross-modal correlation, and claim complexity assessment using foundation models (FMs) served through Amazon Bedrock.
Browser reasoning is performed by Amazon Nova Act, a client SDK that interprets natural-language instructions (for example, “open the next unprocessed claim” or “trigger image analysis”) and translates them into grounded UI actions. Amazon Bedrock AgentCore Browser tool provides the managed, isolated Chrome session that Nova Act connects to for executing those actions. AgentCore Browser Tool also provides session recording and live view capabilities for observability.
In this workflow, Nova Act drives the intake process by reasoning about what’s visible on screen through the AgentCore Browser session, while the Strands-based agents perform domain reasoning in the background. Nova Act determines when evidence must be analyzed and orchestrates portal interactions, and the domain agents determine what the evidence means by applying the same domain logic a human reviewer would use.
The result is automation of manual screen work while preserving human oversight and auditability. Claims professionals receive context-rich, pre-analyzed submissions ready for judgment rather than validation. Tagged evidence becomes a durable operational asset, supporting better routing, pattern analysis, and continuous workflow refinement across the claims lifecycle.
The workflow is illustrated using real browser automation recordings captured directly from the system in action.
The opportunity: Optimizing claims intake to amplify human expertise
Across insurance lines (auto, property and casualty, life, health, and specialty), claim intake marks the moment when unstructured information first enters the system. Photos, videos, scanned documents, and recorded notes arrive together, often incomplete, inconsistently labeled, and rarely standardized.
Claims professionals bring deep domain knowledge to this moment. They know what usable evidence looks like, what is typically missing, how artifacts relate to one another, and which signals matter for coverage, severity, and next steps. Yet today, much of that expertise is applied through slow, manual portal work clicking through screens and visually inspecting artifacts one by one. Before meaningful assessment can begin, reviewers must answer foundational questions that rely heavily on experience. These include whether required artifacts are present, whether photos and videos are usable and relevant, whether audio notes contain material observations, and whether the submission is sufficient to proceed without delay.
Answering these questions requires painstaking screen work. A typical FNOL submission can include dozens of artifacts spread across multiple views, requiring reviewers to locate evidence, open and interpret each item, correlate signals across modalities, compare findings against policy thresholds, and capture summaries for audit continuity.
These steps are essential, but they are also repetitive and mechanical. They require attention rather than judgment. As a result, skilled adjusters and examiners spend a disproportionate amount of time validating intake completeness before they can apply their expertise to higher-value decisions.
This challenge exists in everyday claims processing and becomes more pronounced during volume spikes from catastrophe events, seasonal auto claims, or surges in health and life claims activity. As workloads increase, backlogs grow, evidence review becomes rushed or inconsistent, and human judgment is applied later than it should be.
The issue isn’t a lack of expertise or technology. It’s that domain knowledge is being exercised too late in the process, after time has already been spent on repetitive intake validation.
Why encoding domain knowledge changes the landscape
Claim intake accelerates when critical decision logic is captured in structured rules and applied consistently at ingestion time, rather than relying solely on individual experience and intuition.
Experienced reviewers intuitively know which photo angles are required for different claim types, when video can substitute for missing images, which combinations of artifacts signal higher complexity, and which gaps are likely to stall downstream processing.
Agentic generative AI makes it possible to encode this working knowledge into business rules and reasoning tools that can be applied consistently as evidence enters the system.
By combining Strands Agents with Nova Act and the AgentCore Browser Tool, mechanical intake work like navigating portals, opening claims, and triggering analysis is separated from domain reasoning. Nova Act advances the workflow through the Browser Tool session, while Strands Agents apply expert logic to interpret, tag, and correlate evidence.
When evidence is tagged at ingestion, missing or insufficient artifacts are detected early, relevance becomes explicit rather than implicit, and claims can be triaged based on what is present. Human reviewers begin with context instead of starting from scratch.
Why automated evidence tagging matters – now and later
Automated tagging accelerates the current claim by ensuring intake completeness and clarity before downstream steps begin. Reviewers spend less time confirming basics and more time applying judgment where it matters.
Over time, consistently tagged evidence becomes a durable data asset. Because tags are generated by codified domain reasoning, not one time interpretation, insurers can do the following:
- Improve routing and prioritization
- Reduce rework caused by incomplete submissions
- Identify patterns that lead to delays or escalations
- Refine intake rules as new scenarios emerge, without changing compliance boundaries or decision authority
As tagged evidence accumulates, unstructured artifacts are no longer isolated files. Images, videos, and audio become searchable, analyzable signals that support new workflows, such as proactive outreach when common gaps are detected, pre-staging claims for specialized teams, and shortening cycle times for similar future claims.
Most importantly, tagging allows domain expertise to be applied once at ingestion and reused throughout the lifecycle, rather than rediscovered repeatedly at different stages.
This is the shift agentic automation enables: moving expertise upstream, enriching downstream systems with structured signals, and enabling faster, more consistent resolution, without removing humans from the loop.
To demonstrate how this shift can be implemented without modifying existing portals, the following section walks through an agentic FNOL intake architecture that combines browser-level automation with reasoning-driven agents.
Solution overview: Agentic intake without portal changes
This prototype demonstrates how FNOL intake can be automated end-to-end using agentic reasoning and browser-level interaction. In production, the same browser automation approach would work against existing portals without modification, because the Nova Act client SDK interacts with the UI as a human would.
The prototype is built to mirror a realistic production environment. The FNOL portal and backend services run as a containerized application on AWS, while agent-driven browser automation interacts with the live portal exactly as a human reviewer would. This separation allows domain reasoning and UI control to evolve independently, while preserving auditability and operational safety.
At a high level, the solution assumes a working familiarity with how modern, agentic systems are deployed on AWS. This includes the use of FMs for reasoning, containerized services for application runtime, and event-driven storage for state and evidence. No prior experience with traditional robotic process automation (RPA) tools is required. The automation described here relies on reasoning over UI state rather than replaying pre-recorded scripts or hard-coded flows.
AWS account and permissions
You need access to an AWS account with permissions to deploy and manage the resources used by the solution, including AWS Cloud Development Kit (AWS CDK), Amazon Elastic Container Service (Amazon ECS) on AWS Fargate, Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, Elastic Load Balancing (Application Load Balancer), Amazon CloudFront, and AWS Identity and Access Management (IAM) roles and policies.
The deployment assumes that AWS credentials are configured locally using a standard development setup with the AWS Command Line Interface (AWS CLI).
Runtime environment and deployment model
The FNOL intake user interface and backend services, including evidence analysis and claim complexity evaluation implemented using Strands Agents, are packaged as Docker containers and deployed on Amazon ECS with AWS Fargate. Infrastructure is provisioned using AWS CDK, which builds container images and creates the required compute, storage, and networking resources as part of a single deployment workflow.
Unstructured evidence artifacts such as images, videos, and transcripts are stored in Amazon S3. Claim metadata, evidence references, and agent-generated analysis outputs are persisted in Amazon DynamoDB. This allows agents to retrieve, correlate, and reason over evidence throughout intake.
Browser automation in practice
Agent-driven browser automation is executed from a separate control environment, such as a workstation or automation host, and connects to the deployed FNOL application through an AgentCore Browser session. This reflects how browser automation is commonly operated in real-world environments. Nova Act, the client SDK responsible for browser reasoning, connects to the managed Chrome session provided by AgentCore Browser Tool through Chrome DevTools Protocol (CDP) over WebSocket. The automation layer observes and interacts with the live portal through this managed browser, while backend services remain hosted and isolated.
By keeping browser control external to the application runtime, the system maintains clear operational boundaries. Agents see exactly what a human reviewer would see on screen, make decisions based on current UI state, and act deliberately without requiring direct access to portal internals or application code.
Deployment workflow and setup
The full deployment workflow, including infrastructure provisioning, container deployment, optional data generation, and browser automation setup is automated through scripts and configuration files provided in the accompanying GitHub repository.
Architecture overview
At a high level, the architecture consists of the following complementary layers:
- Browser interaction. Nova Act connects to an AgentCore Browser Tool session through Chrome DevTools Protocol (CDP) over WebSocket, reasoning about the FNOL portal’s UI state and acting deliberately on what is visible.
- Domain reasoning. Two agents are built with the Strands Agents SDK: an Evidence Analyzer agent that interprets and tags multimodal evidence, and a Claims Complexity Analyzer agent that assesses claim complexity.
- Execution observability. Screenshots, prompts, reasoning, and UI state transitions are captured automatically at each step, producing a reviewable audit trail without additional instrumentation.
- Infrastructure and persistence. Amazon ECS on AWS Fargate runs the application, Amazon S3 stores evidence artifacts, Amazon DynamoDB maintains claim state and analysis outputs, and Amazon CloudWatch provides operational visibility.
The following diagram shows how the different components fit together to automate FNOL intake:
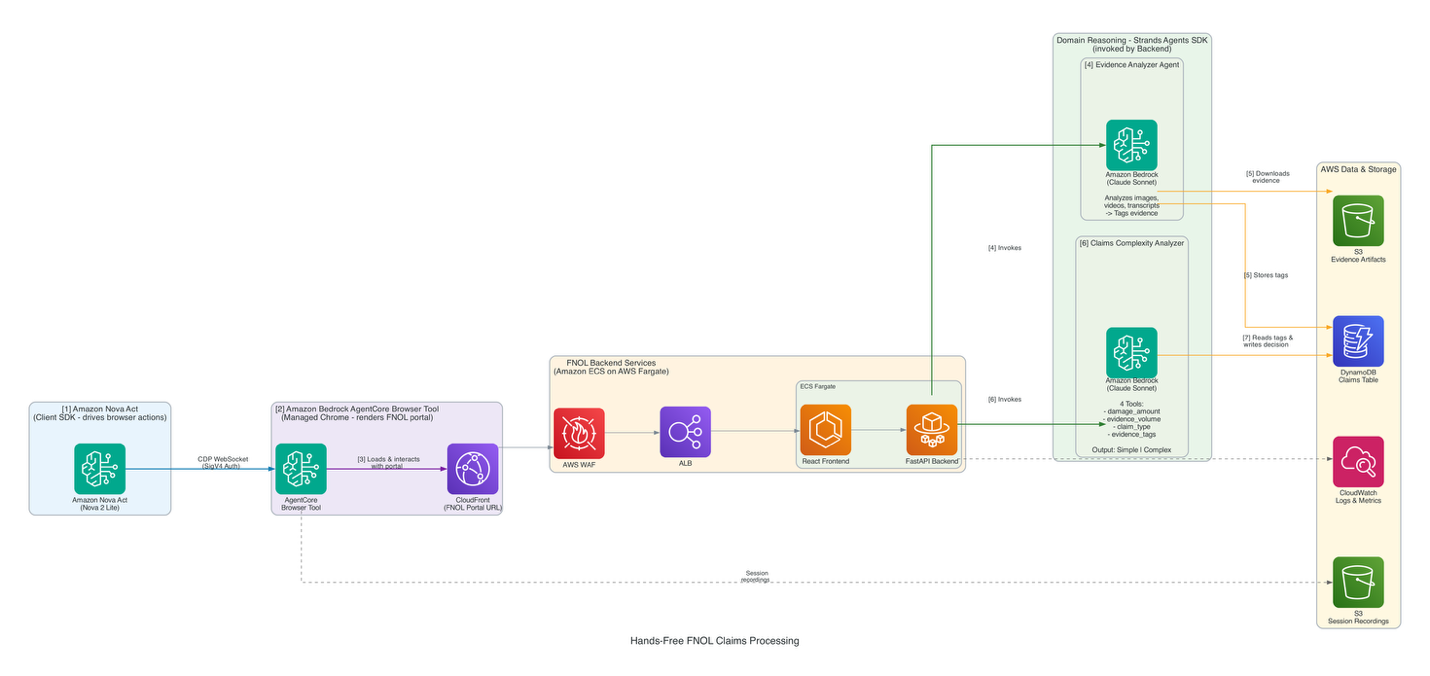
The architecture is intentionally layered to separate portal interaction, domain reasoning, execution observability, and infrastructure concerns, while preserving a single, end-to-end FNOL intake workflow. Agent-driven browser automation operates at the top of the stack, interacting with the FNOL portal exactly as a human reviewer would. Domain-specific reasoning is applied independently by Strands Agents, while AWS infrastructure provides the managed foundation for execution, persistence, and operational visibility.
Browser interaction with Nova Act and AgentCore Browser Tool
Nova Act is responsible for observing and interacting with the FNOL portal’s user interface, without embedding any domain logic or decision-making. Running inside an AgentCore Browser Tool session and connecting to the browser using Chrome DevTools Protocol (CDP), Nova Act reasons about the current UI state in real time. It navigates claim queues, identifies unprocessed evidence sections, invokes Analyze Images, Analyze Videos, and Analyze Audio actions, interacts with modal dialogs, and scrolls only when necessary to avoid unintended UI changes. This approach allows automation to behave like a careful human reviewer: observing what’s visible on screen, deciding which action is appropriate, and acting deliberately based on current state rather than replaying predefined steps or brittle scripts.
Execution observability and auditability
Because AgentCore Browser executes actions through a managed browser session, every interaction is observable and traceable by design. As the automation runs, actions can be observed live through the Chrome DevTools Protocol (CDP) session, providing real-time visibility into how the agent interacts with the FNOL portal.
At each decision point, screenshots are captured automatically, while prompts, decisions, and UI state transitions are recorded as structured metadata. Together, these artifacts form a complete execution trail that makes the agent’s behavior transparent and reviewable. It’s always possible to determine what the agent saw on screen, why a specific action was taken, which evidence was processed, and what conclusions were derived as a result.
This produces a natural audit trail without requiring additional instrumentation or custom logging. This is an essential capability in regulated insurance environments where explainability, traceability, and operational accountability are as important as automation itself.
Capturing screenshots during agent execution
In this prototype, browser automation is configured with a session-specific logging directory. As the agent executes each act() step, Nova Act captures the visible browser state and persists screenshots alongside step metadata such as prompts, timestamps, and action identifiers.
These artifacts support both operational troubleshooting (by revealing exactly what the agent observed when encountering unexpected UI states) and audit or post-run review, without relying on continuous screen recordings. Each execution produces an isolated, timestamped folder containing screenshots and logs. This makes runs reproducible, inspectable, and clearly attributable to a specific session.
Downstream processing and storage on AWS
After evidence has been analyzed and tagged, AWS services provide the durable foundation required to persist results, maintain claim state, and support operational visibility throughout the intake workflow.
The two Strands-based agents handle all reasoning-driven processing independently of the user interface. The Evidence Analyzer agent performs multimodal evidence analysis across images, videos, and transcripts with structured metadata tagging, and the Claims Complexity Analyzer agent evaluates claim complexity using specialized tools. Analyzed artifacts, summaries, and tagging outputs are stored in Amazon S3, while claim state, evidence references, and agent-generated results are maintained in Amazon DynamoDB to preserve a complete, queryable record of what was observed and inferred.
Operational logs, metrics, and execution traces are captured through Amazon CloudWatch, providing visibility into system behavior and supporting monitoring, troubleshooting, and audit requirements. Together, these components transform raw FNOL submissions into structured, decision-ready inputs at ingestion time, before claims are routed or escalated for additional review. This makes sure that downstream processes receive consistent, context-rich, and traceable information from the start.
With the architecture in place, the remainder of this post follows the system as it operates in practice. The next sections walk through a single FNOL intake sequence as it unfolds in the live portal, starting at the FNOL queue and progressing through evidence analysis and complexity classification. Each step is illustrated using actual browser automation recordings and screenshots captured during execution, showing how agentic automation and domain reasoning work together in real time.
From FNOL queue to claim selection
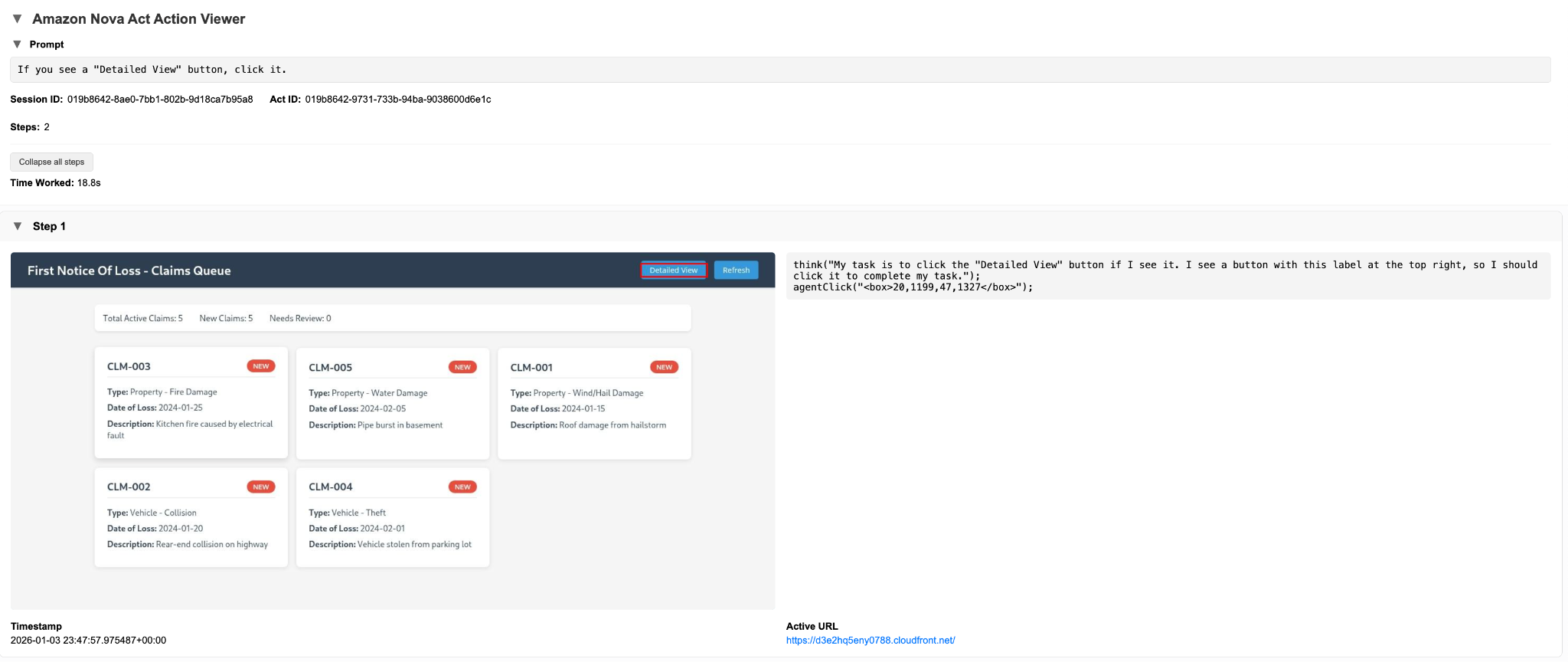
The workflow begins at the FNOL queue. Nova Act observes the live portal state through the AgentCore Browser Tool session, identifies the next claim ready for processing based on visible status indicators, and navigates into the claim detail view. Because the decision is grounded in current UI state rather than pre-recorded scripts or hard-coded selectors, the same logic handles new queue layouts, reordered columns, or changing row counts without modification.
The following screenshot shows the queue exactly as Nova Act observed it during a representative run. The automation reasons over visible UI elements, such as claim rows and status indicators, to determine the next eligible action. The screenshot is automatically captured as part of the execution log and serves as both a troubleshooting artifact and an audit record.
With the claim selected and its detail view loaded, the workflow moves from queue management into intake processing. At this stage, the detail view has finished rendering and the available evidence sections are identified, setting up the next phase of structured evidence analysis.
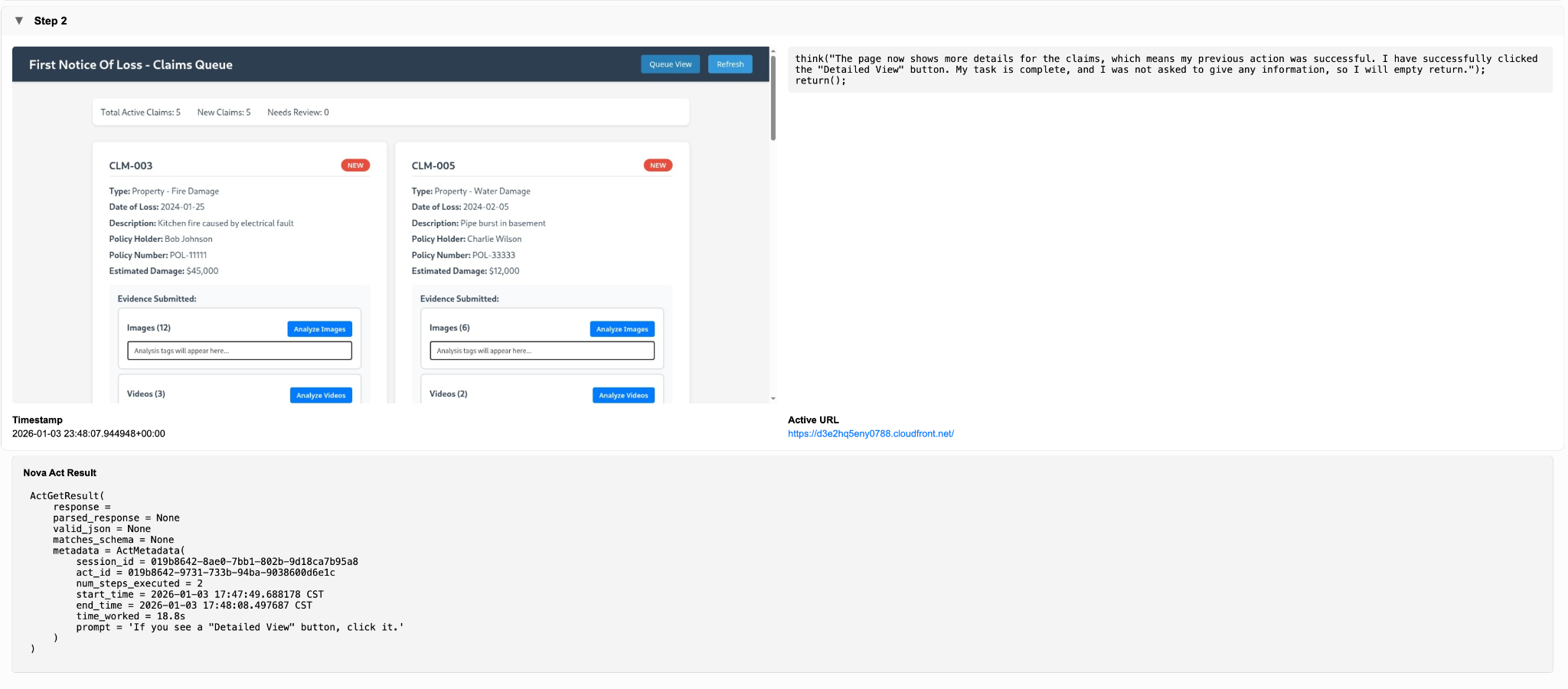
Evidence analysis: Structured review across modalities
Evidence review is where FNOL intake typically slows down. The execution recording highlights this by showing three distinct actions, Analyze Images, Analyze Videos, and Analyze Audio, each corresponding to a separate review path. This mirrors how a human examiner evaluates evidence one modality at a time rather than treating all artifacts uniformly.
At this stage, responsibilities divide cleanly. Nova Act manages UI control flow, determining when evidence is ready, invoking the appropriate analysis action, and waiting for completion. Strands Agents run server-side, applying insurance-specific reasoning with codified business rules that reflect how a human reviewer would interpret each artifact. This separation is intentional. UI orchestration determines when and where analysis should occur, while domain reasoning determines what the evidence means. The result mirrors how human examiners work, first identifying available evidence, then interpreting it, while allowing each step to execute at machine speed and with full traceability.
The following screenshot shows the evidence section as Nova Act observes it before analysis begins. Controls such as Analyze Images, Analyze Videos, and Analyze Audio are detected based on current UI state rather than hard-coded selectors.
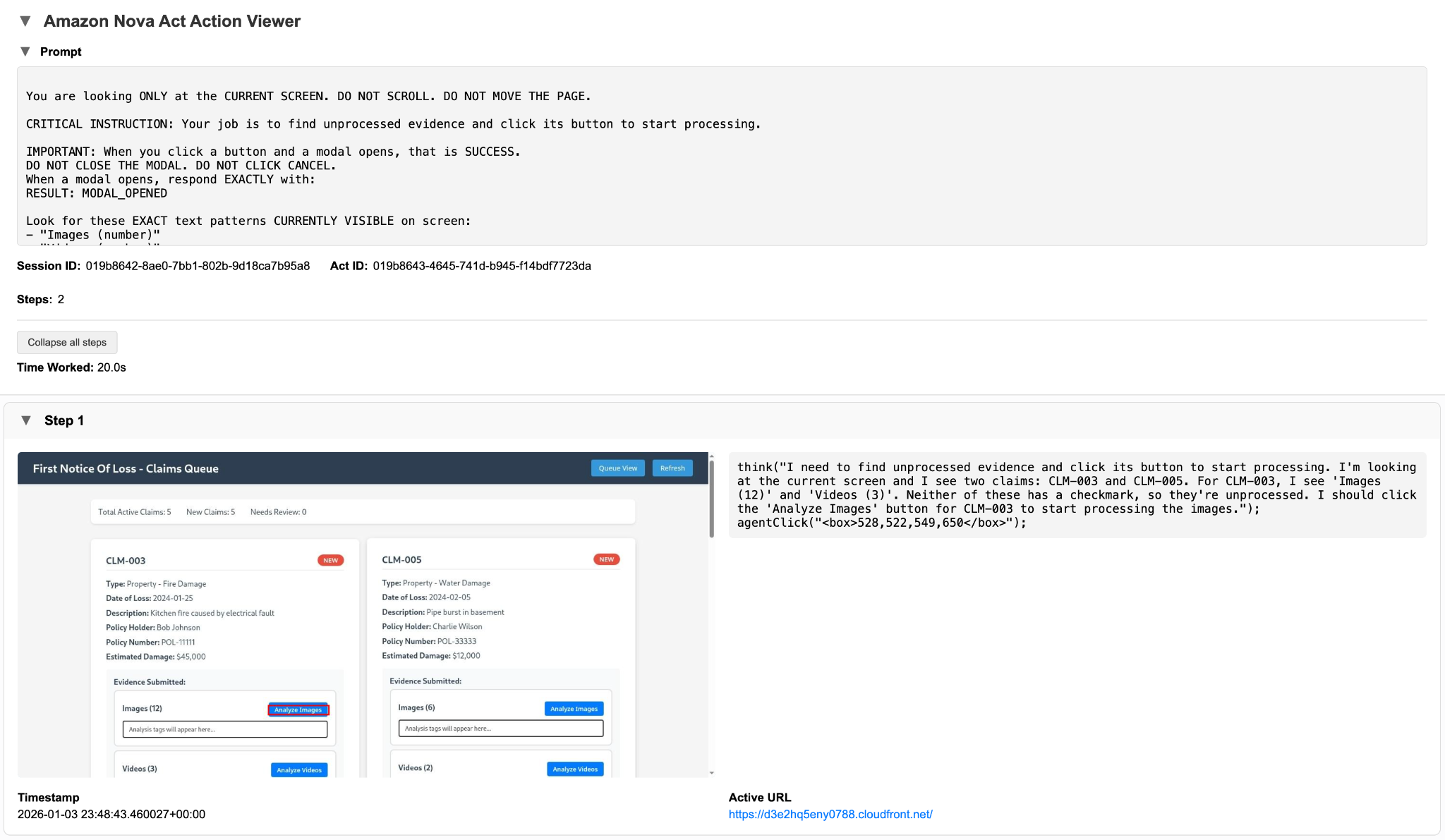
Analyze images: Tagging visual evidence
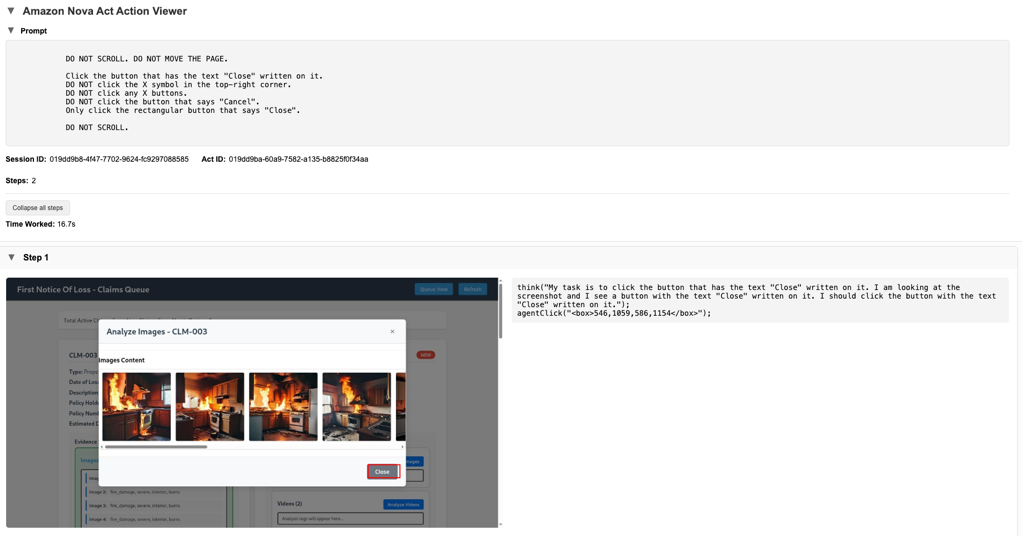
When Analyze Images is invoked, each submitted image is evaluated independently. Strands Agents apply insurance-specific business rules that reflect how experienced reviewers interpret visual evidence. This includes identifying what the image depicts (for example, vehicle damage, roof surface, siding, interior, or medical documentation), assessing whether the perspective is appropriate for the claim type, confirming clarity and usability, and flagging damage indicators. Rather than leaving this interpretation implicit, each image is tagged with structured attributes that make human judgment explicit, consistent, and reusable throughout the claim lifecycle.
The following screenshot captures the UI state as image analysis is initiated, with the image set and analysis controls visible to the automation and recorded as part of the execution trace. After analysis is triggered, the modal opens and presents the submitted images while Strands Agents evaluate each one in the background. The screenshot shows this in-progress state, with image evidence visible on screen as evaluation is applied.
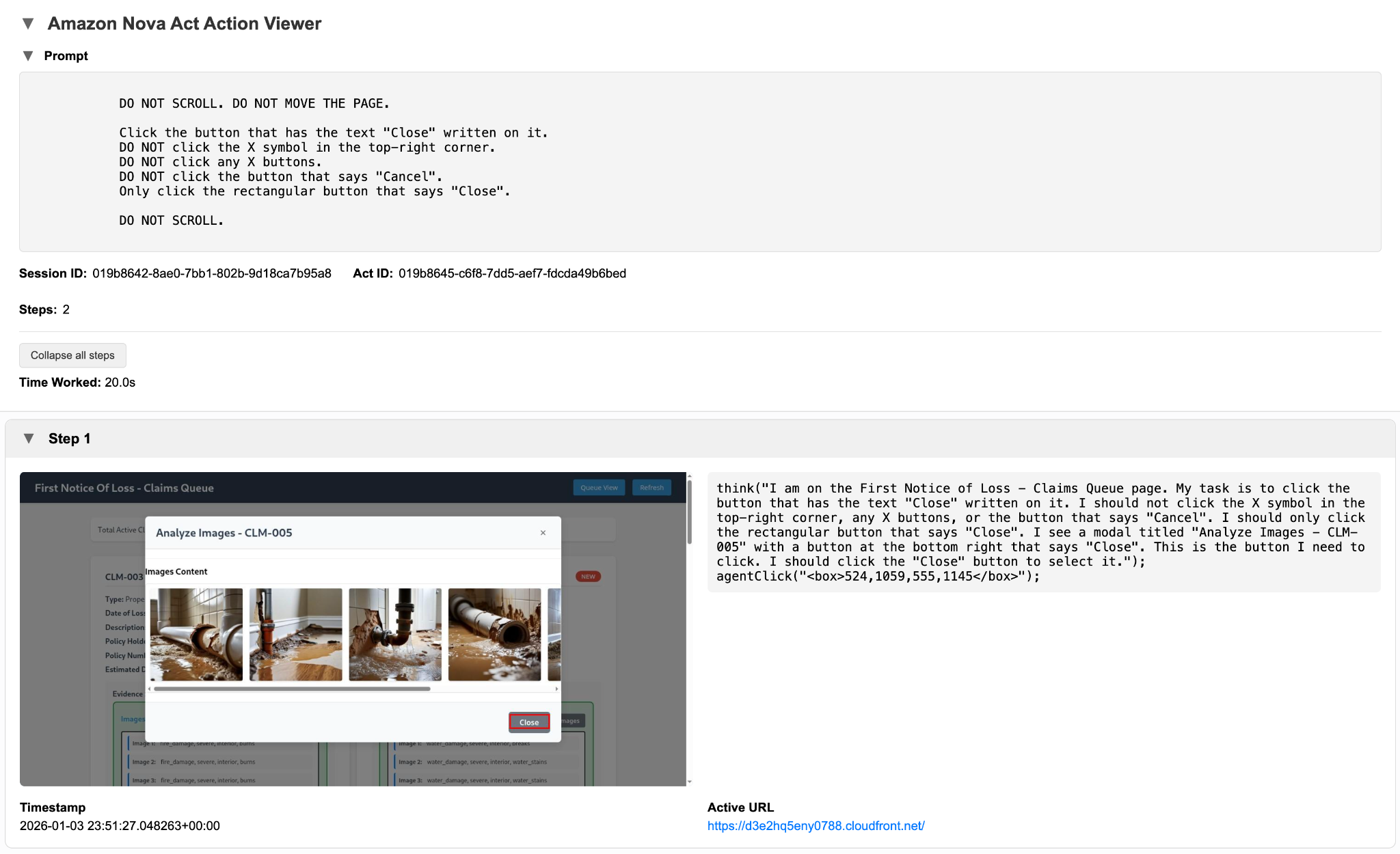
Analyze videos: Treating motion as first-class evidence
When Analyze Videos is invoked, video submissions are evaluated as evidence, not as opaque attachments. Strands Agents assess what each video captures: whether it adds information beyond still images, supplements missing photos, or corroborates or contradicts other artifacts. Video-derived signals are then tagged and normalized to participate directly in downstream reasoning alongside images and documents, rather than being treated as a secondary or manual review step.
The following screenshot captures the portal state as video analysis is triggered, preserving UI context so video evaluation remains fully traceable and auditable.
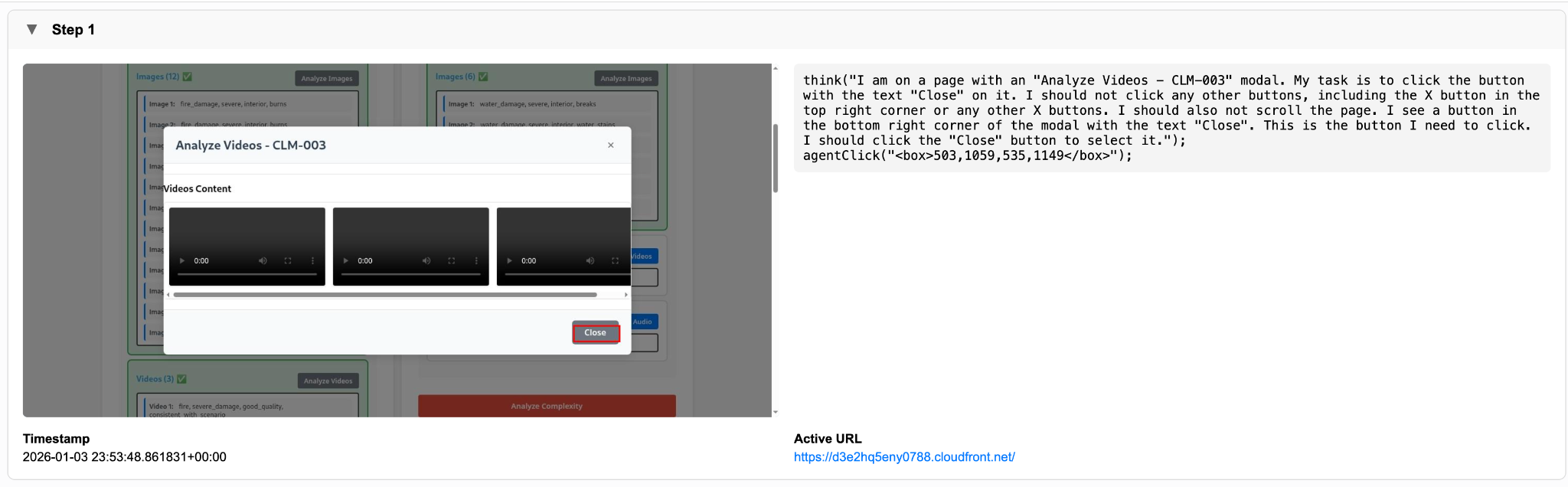
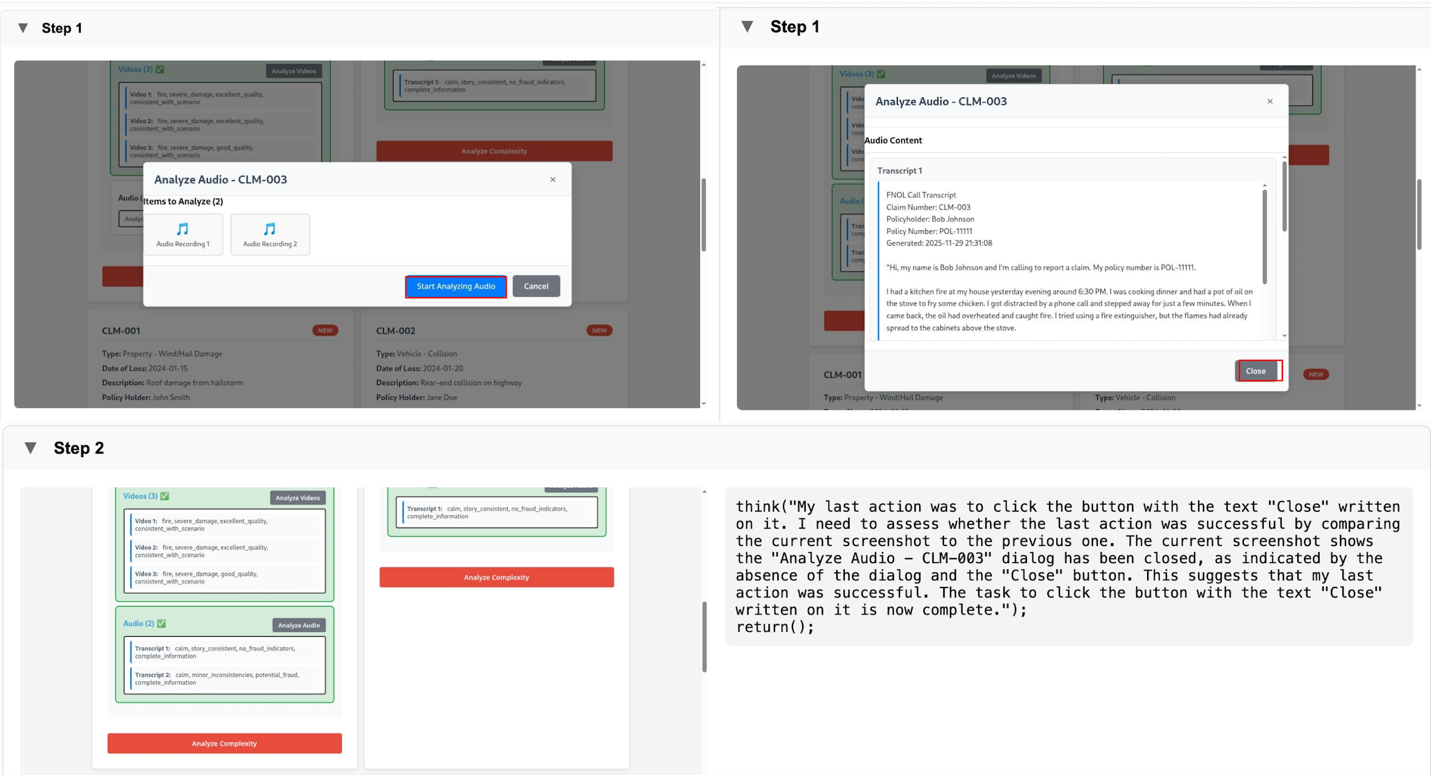
When Analyze Audio is invoked, the system processes audio evidence through corresponding call transcripts rather than raw audio directly. For each audio recording, a corresponding text transcript is retrieved. The Evidence Analyzer Strands Agent then analyzes the transcript text to extract material observations and factual statements, reported damage or conditions, and contextual details that complement visual or document-based evidence.
Transcribed signals are then correlated with image and video tags, mirroring how a human reviewer cross-references spoken context with visual proof during intake. The following screenshot captures the portal state as audio analysis is triggered, with the transcript visible to the automation.
Taken together, the Analyze Images, Analyze Videos, and Analyze Audio steps produce a layered, reviewable record of intake. AgentCore Browser Tool captures screenshots and session activity at each step. Nova Act records the prompt, reasoning, and action taken in response to the current UI state. Strands Agents persist the structured tags and classification reasoning produced for each artifact.
The result is a complete audit trail of what was on screen, why the agent acted, and how the evidence was interpreted, all of which is generated as a byproduct of execution rather than through additional instrumentation.
Why this step matters
By the end of evidence analysis, every image, video, and audio artifact has been evaluated and tagged. No evidence remains unclassified, and quality, relevance, and completeness are made explicit rather than inferred.
This transforms raw FNOL submissions into structured, decision-ready inputs before downstream routing, escalation, or manual review occurs. This sets the stage for complexity assessment of the submitted claim in the next step.
Complexity analysis: From tagged evidence to triage decisions
With evidence fully tagged, the agent evaluates each claim holistically. Instead of relying on static intake fields alone, Strands Agents combine claim metadata with evidence-derived signals observed during intake to assess complexity using rules already familiar to insurance operations. These include severity indicators across modalities, evidence completeness and internal consistency, and policy thresholds that determine escalation or routing.
Because this assessment is grounded in what was submitted and observed, complexity classification reflects the true state of the claim rather than assumptions made at submission time. Claims are classified as Simple or Complex. Simple claims are auto resolved, while Complex claims are routed to “Needs Review” status with structured notes generated automatically explaining why the claim was flagged. These notes provide immediate and actionable context for downstream users.
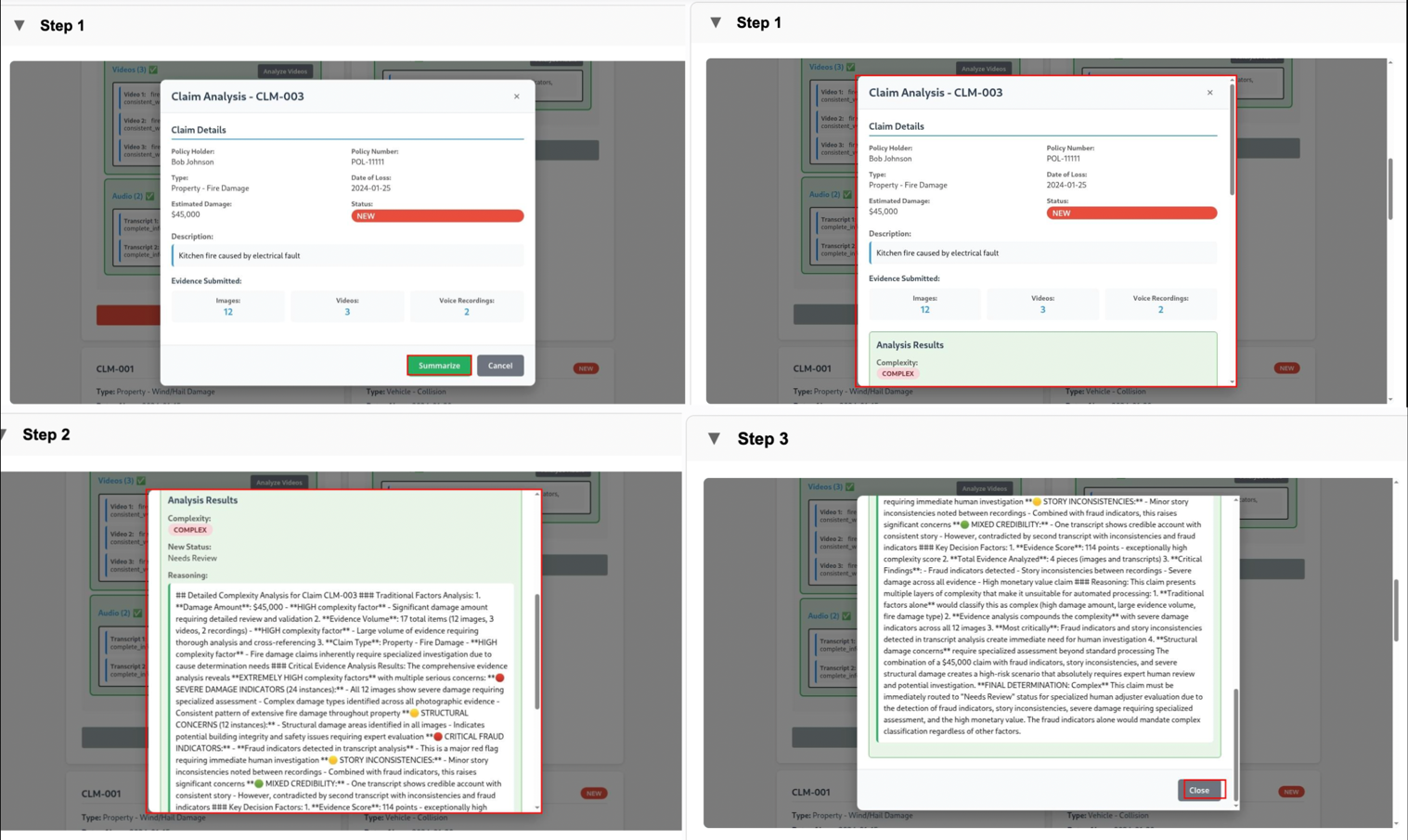
These screenshots capture the portal state after complexity analysis has completed. Evidence-derived signals are surfaced alongside structured notes, making the rationale for classification transparent, reviewable, and auditable.
Why this matters for insurance carriers
By deferring human involvement until complexity has been assessed, expertise is applied at the right moment, on interpretation, judgment, and resolution rather than intake validation. Straightforward claims progress without unnecessary friction, while complex cases are surfaced early with context already in place. This reduces queue contamination, prevents late-stage escalation, and improves predictability during both steady-state operations and volume spikes.
Human-in-the-loop, not human-in-the-weeds
This system doesn’t remove people from the process. It changes where they engage. With evidence already analyzed and tagged, adjusters begin their work with context instead of raw artifacts. Review replaces reprocessing. Corrections become feedback rather than rework.
Over time, this feedback improves business rules incrementally as patterns emerge across claims. FNOL intake evolves from a bottleneck into a learning system, one that continuously refines how evidence is interpreted, routed, and acted upon without increasing operational burden.
Why this matters for insurance carriers
This approach fundamentally changes where and when expertise is applied in the claims lifecycle. By structuring multimodal evidence at ingestion time, carriers reduce intake handling time by automatically assessing completeness and relevance. Claims move faster, especially during volume surges, because fewer submissions stall downstream waiting for validation.
Evidence interpretation becomes more consistent and less dependent on individual reviewer experience. Gaps are identified early, reducing downstream corrections and rework. Equally importantly, adjusters experience less cognitive fatigue and can focus on decisions rather than validation. These capabilities work without replacing existing systems or disrupting established workflows. The automation works with the portals carriers already rely on.
Beyond FNOL: The value of tagged unstructured evidence
While FNOL is the entry point, the value of structured, tagged evidence extends across the entire claims lifecycle. After unstructured artifacts are consistently interpreted and tagged at ingestion, they stop behaving like static attachments and begin functioning as operational signals.
Claims can be routed based on what the evidence actually shows rather than relying on coarse intake fields or manual triage. Downstream workflows arrive pre-populated with context, including damage indicators, completeness signals, and corroborating evidence. This reduces friction at every handoff and minimizes the need for re-validation. As patterns emerge across claims, evidence collection guidance improves organically, helping carriers identify common gaps and adjust intake expectations before those gaps create downstream delays.
Over time, historical claims become analyzable based on what was truly submitted and observed, not only how claims were labeled at intake. This enables deeper operational insight into cycle-time drivers, escalation patterns, and evidence quality across regions, perils, and claim types. Tagged evidence turns unstructured files into reusable, queryable data that supports better decisions without changing compliance boundaries, decision authority, or core systems.
The result isn’t only faster FNOL processing, but a foundation for more adaptive, evidence-driven claims operations.
Conclusion
In this post, we showed how a hands-free FNOL intake system combines Strands Agents with Amazon Bedrock AgentCore Browser Tool and Amazon Nova Act to structure multimodal evidence at the moment it enters the system. FNOL shifts from a validation bottleneck to an acceleration point. Claims progress with context already established. Routing decisions are informed by what was actually submitted. Escalations occur earlier and more predictably. Straightforward cases move forward without unnecessary handling.
This shift doesn’t depend on replacing portals, rewriting existing systems, or altering decision authority. It comes from making intake interpretation explicit (how evidence is evaluated, which signals are meaningful, and how gaps affect downstream processing) and applying that interpretation consistently at ingestion time. What was previously re-derived through repeated manual review becomes structured, durable, and reusable.
The outcome is not automation for its own sake, but a more effective use of judgment. Interpretation happens once. Evidence is tagged in a way that persists. Those signals travel with the claim instead of being rediscovered at each stage. FNOL intake improves through clearer signals and better flow, allowing downstream processes to start with context rather than uncertainty.
To explore this approach in your own environment, deploy the prototype from the GitHub repository, and learn more in the Amazon Bedrock AgentCore documentation, the Amazon Nova Act documentation, and the Strands Agents documentation.
About the author


