
DeepMind has applied its gaming expertise to a more serious business: the foundations of computer science.
A Google subsidiary today announced AlphaDev, an AI system that discovers new fundamental algorithms. According to DeepMind, the discovered algorithms surpass those honed over decades by human experts.
The London-based institute has big ambitions for this project.As computational demands increase and silicon chips approach their limits, basic algorithms Efficiency should increase exponentially. By enhancing these processes, DeepMind aims to transform the infrastructure of the digital world.
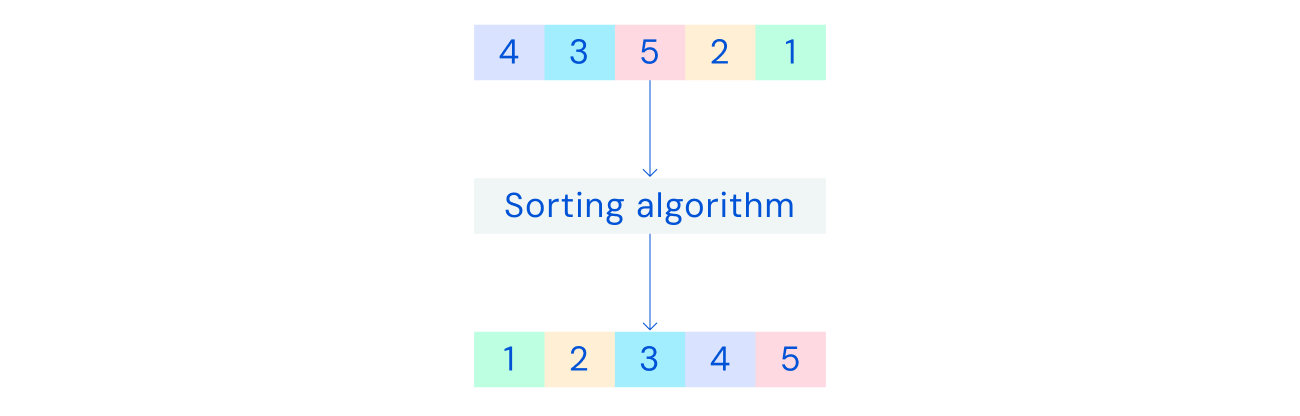
The first target for this mission is A sorting algorithm used to order the data. Everything from search rankings to movie recommendations is determined inside our devices.
To improve performance, AlphaDev investigated the assembly instructions used to create binary code for computers. After an exhaustive search, the system found a sorting algorithm that outperformed previous benchmarks.
To find the winning combination, DeepMind had to revisit the feat that made the company famous: winning a board game.
gamification of the system
DeepMind has made a name for itself in gaming. In 2016, the company’s AI program made headlines. lost World champion of Go, a highly complex Chinese board game.
Following the win, DeepMind built a more general system, AlphaZero. using a trial-and-error process called reinforcement learning, The program learned not only Go, but also chess and shogi (aka “Japanese chess”).
AlphaDev — New Algorithm Builder — is based on AlphaZero. But the influence of games extends beyond the underlying model.
“We give penalties if we make mistakes.
DeepMind has formulated AlphaDev’s task as a single-player game. To win the game, the system had to: Build a new and improved sorting algorithm.
The system made that move by choosing which assembly instructions to add to the algorithm. To find the optimal instruction, the system had to explore a huge number of instruction combinations. According to DeepMind, that number is close to the number of particles in the universe. And just one wrong choice can invalidate the whole algorithm.
After each move, AlphaDev compared the output of the algorithm with the expected result. If the output is correct and the performance is efficient, the system receives a “reward”, a signal that it is working fine.
“We penalize them for making mistakes and reward them for finding more correctly sorted sequences,” lead researcher Daniel Mankowitz told TNW.
As you probably guessed, AlphaDev won the game. But the system didn’t just find the correct and faster program. We also discovered a new approach to this task.
The new algorithm contained an instruction sequence that saved one instruction each time it was applied. These so-called “swap-and-copy moves” served as shortcuts to further efficiency of the algorithm.
DeepMind likens this approach to another moment in the game. The legendary “37 moves” Which AI The system played against Go champion Lee Sedol.
This strange move shocked human experts who thought the machine might have made a mistake. But they soon realized that the program had a plan.
“In the end, it wasn’t just about winning games, it was also affecting the strategies professional Go players started using,” Mankowitz said.
The victory marked the first time an AI has beaten a top-ranked Go pro. Experts had expected that milestone to take another decade.
Three years later, Lee retired from professional Go competition. He attributed the decision to the capabilities of AI rivals.
“Even if we become number one, there is someone we can’t lose to.”
Organize your computing
AlphaDev’s sorting algorithm is now open-sourced. Main C++ library, available to millions of developers and businesses. According to DeepMind, this is his first change to this part of the sorting library in over a decade, and the first algorithm designed through reinforcement learning to add to the library.
After the sorting game, AlphaDev started playing with hashes used to retrieve, store, and compress data. As a result, another hardened algorithm was born. liberated It’s in the open source Abseil library. DeepMind estimates this is used trillions of times in his day.
The laboratory ultimately envisages alpha development As a step towards transforming the entire computing ecosystem. And it all started with playing board games.


