
What if a high-performance machine learning model doesn’t work in practice?
It’s not as rare as you might think. Researchers report that almost 70 to 80% of machine learning (ML) projects are not deployed in production due to a lack of planning, data, or integration.
It’s not the model. It’s the process of integrating machine learning models.
This article explains the process of integrating machine learning models in production. Each part flows into the next to make the whole system functional.
Assessing Readiness: The First Step in Successful Integration
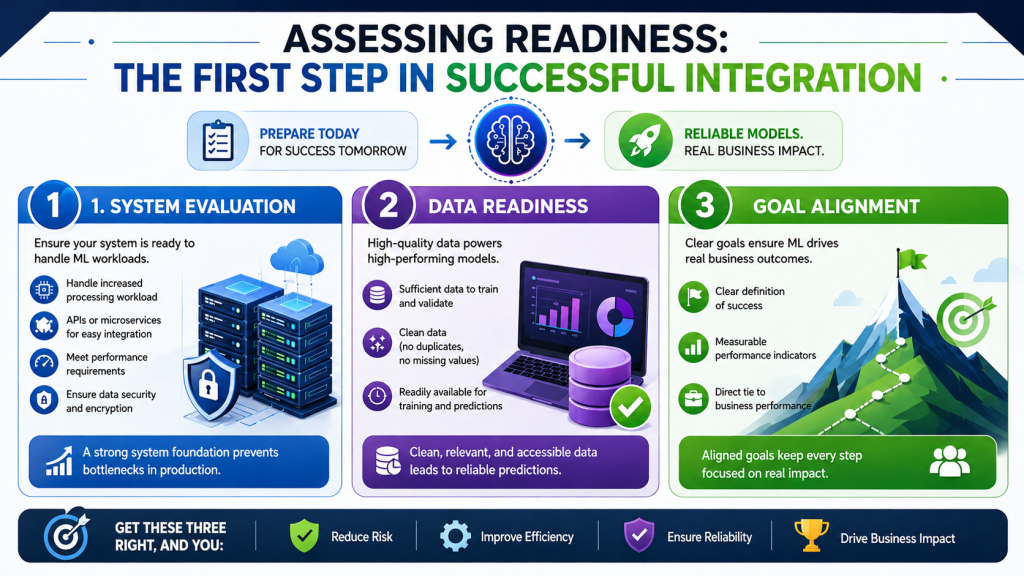
When working to integrate machine learning models, make sure to get the house in order first. Too often, machine learning projects are not successful because the system, data, or business objectives are not in sync. This provides clarity and minimises risk before development and deployment.
System Evaluation
System evaluation is concerned with whether the current application is able to integrate the machine learning model without impacting performance. Experience with applications may not help with real-time predictions and processing large amounts of data.
At this point, it is useful to consider a couple of key elements of the system environment:
- Environment to handle an increase in processing workload
- APIs or microservices for easy integration
- Performance requirements on response times, particularly for real-time applications
- Data security and encryption for confidential data
If it’s not agile or fast enough, it may need to be upgraded. This avoids bottlenecks when going to production.
Data Readiness
Data readiness is a crucial step in machine learning models. No matter how sophisticated the algorithm is, it won’t work without good-quality data. There is a lot of research that indicates that bad data quality degrades model performance and makes model predictions unreliable.
High-quality data has three components. First, there needs to be sufficient data to train and validate the model. Second, the data must be clean (no duplicates, missing values). Third, the data should be readily available for model training and predictions.
During a brief validation phase, typically, the following is checked:
- No values for key fields
- Duplicates that can skew the model
- Old or unrelated data
Data preparation is essential for the product to have a higher chance of success.
Goal Alignment
Having clear goals provides a focus for the integration process. If there are no goals, the model may still not be able to drive business outcomes. That’s why setting a goal is part of how to integrate machine learning models in production.
Good goals are concrete, measurable, and outcome-oriented. For instance, rather than having a goal for improving performance, use goals for reducing response time or for conversions.
Well-aligned goals typically include:
- A clear definition of success
- Measurable performance indicators
- Ties to business performance
This focus helps ensure that each step of the development process, from model choice to application, is geared toward achieving impact.
Grow your business with machine learning consulting from EXRWebflow. See how it can be applied in your business.
Defining the Right ML Use Case for Your Application
Selecting the right use case is a critical step in using machine learning models. Having a clear use case guarantees that the time and resources invested in development and deployment will have a positive impact. Otherwise, machine learning can turn out to be a costly experiment.
A good use case typically involves predictions, pattern matching, or automation. These are suited to machine learning instead of conventional systems because it improves with experience. For instance, predictive applications such as forecasting, fraud prevention, and recommendation systems are based on patterns that are hard to express in rule-based systems.
However, challenges that adhere to fixed rules or simple decision-making are not well-suited for machine learning. Using a model in such a scenario adds complexity to the system without adding value. That’s why identifying the right use case is critical in how to use machine learning models in production.
There are a couple of factors to consider to assess if a problem is right for machine learning:
- Presence of historical data that can be used to train the model
- Existence of learnable patterns or trends
- Need for predictions or decision-making
- A capacity to learn and improve with more data
With these criteria, “machine learning model integration” is possible. Having a clear use case also assists in model, data preparation, and deployment decisions.
Selecting the Right Machine Learning Model
With a clear use case, it’s time to choose an appropriate model. The model affects the performance, scalability, and deployment. The wrong model choice can result in poor performance despite good data preparation and system design.
Models are suited to different types of activities. For instance, a regression model is needed to predict a value (such as sales), while a classification model is needed to classify data (such as spam filtering). Clustering is often used to group items, such as customer segmentation.
Here’s a basic guide to problem types and model types:
| Problem Type | Suitable Model |
| Predicting numbers | Linear regression |
| Classifying categories | Logistic regression or decision trees |
| Finding patterns in groups | K-means clustering |
There are a lot of complex models to choose from, but it’s best to begin with a simple one. Simpler models are quicker to develop, quicker to implement, and easier to understand. This is a good option when working on initial custom machine learning models and integration.
Compatibility of the model is another consideration. For instance, if a machine learning model is to be integrated with a web application, then faster models are preferred. This helps to deliver a better user experience.
Sometimes, statistical and machine learning models can be combined. This can help to combine statistical and machine learning techniques, particularly in complex systems where a combination of rules and patterns is required.
Choosing a model is not only about accuracy. It is about achieving a mix of performance, speed, scalability, and integration.
Preparing Data for Machine Learning Integration

Preparing data is an important aspect of integrating machine learning models because the model learns from the data. In practice, the majority of problems are due to data rather than algorithms. An effective data pipeline will make the integration of machine learning models easier and avoid mistakes when deploying models.
Data Collection
Data collection involves the collection of relevant and valuable information to support the use case. It’s not only important to collect large volumes of data, but also relevant and representative data.
When collecting data, it is important to:
- Gather data from trusted sources such as databases, APIs, and user interactions
- Make sure the data is relevant to the problem at hand
- Ensure data is in the same format from different sources
- Use unbiased and representative data for predictions
With relevant and adequate data, it’s possible to develop effective models in production.
Data Preprocessing
Data is often not in its purest form. It is likely to have missing data, inconsistent data, and outliers that can negatively impact model performance. Data preprocessing converts raw data into a clean and tidy dataset.
Good data preprocessing typically involves:
- Eliminating duplicate and erroneous records
- Imputing or removing missing data
- Converting categorical data into a numerical format
- Normalizing or scaling features
This directly impacts model performance, and how to integrate machine learning models in production is made more efficient and accurate.
Data Storage
After cleaning the data, it must be stored in a way that makes it accessible for training and real-time predictions. The type of data storage will depend on size and usage.
Key considerations for storing data include:
- Structured databases for small data sizes
- Using data lakes or cloud storage for big data
- Providing quick access to data for real-time applications
- Enabling real-time updates with new information
Fast storage allows scalability and is critical for building a machine learning model into a web application.
Related: https://exrwebflow.com/blog/etl-vs-elt-data-integration-approach/
Building, Training, and Evaluating the ML Model
Once the data has been prepared, the next step is to build and train the model. This is where the machine learning model learns and makes predictions. This will train the model on historical data and test it on new data.
The general process of model development is:
- Dividing the data into training and test data
- Training on historical data
- Testing on the test set
- Optimising for better performance
This is a critical step in custom machine learning model development and deployment as it defines the model’s capabilities.
Evaluation Metrics:
Evaluation metrics are used to assess model performance and to ensure that the desired goals are achieved. The right metric ensures performance meets business objectives, rather than technical targets.
| Metric | What It Measures | Best Use Case |
| Accuracy | Overall correctness of predictions | General classification tasks |
| Precision | Correct positive predictions | Fraud detection, spam filtering |
| Recall | Ability to find all true positives | Medical diagnosis, risk detection |
| RMSE | Prediction error in numerical values | Sales forecasting, pricing models |
Choosing the right evaluation strategy means that integrating machine learning models will result in robust and valuable outcomes.
Deployment Strategies: Integrating ML into Your Application
Deployment is the process of integrating a model into an application. Here, integrating machine learning models takes the leap from concept to real users. Good deployment makes sure predictions are quick, accurate, and can be maintained.
The objective is to not only deploy the model but also to seamlessly integrate it into your application.
API and Microservices Integration
APIs and microservices are a great way of integrating machine learning models. Here, the model is deployed as a separate service, and the application interacts with the model by making requests and getting the predictions.
This approach is popular as it allows for a flexible and scalable system. It also enables us to easily replace the model without re-developing the application.
This method has several benefits:
- Separation of the model and app
- Re-training the model without re-deployment
- Allows real-time predictions via API
- Improved scalability with microservices
This is particularly helpful when connecting a machine learning model to a web application, and we seek fast and seamless user interactions.
Cloud vs On-premise Deployment
A critical choice in the integration of machine learning models in production is where to deploy them. Cloud deployment and on-premises deployment are the two main deployment options.
Both have their own merits, which depend on the business and technical requirements.
| Deployment Type | Key Benefits | Best Use Case |
| Cloud | Scalable, flexible, lower setup cost | Startups, growing applications |
| On premise | Full control, better data security | Sensitive data, regulated industries |
Cloud solutions speed up the process of developing a custom machine learning model and integrating it into the system, as it provides pre-built infrastructure. On-premises solutions, however, are favoured when data security is a priority.
Ensuring Scalability and Maintenance
Once the model is in production, it comes to performance over time. The model that performs well today should continue to perform well in the future. That’s why scalability and maintenance are important aspects of integrating machine learning models.
Scalability
Scalability is the ability of the system to keep up with demand. With more users using the app, the model should still deliver quick and accurate forecasts.
For a system to be scalable, it typically uses:
- Load balancing to distribute traffic efficiently
- Auto scaling to handle peak usage
- Fast response times for real-time predictions
Scalability means that incorporating machine learning models into an application will remain valuable as the application scales.
Model Retraining
Patterns in data evolve. This is known as data drift. This can result in a decline in model accuracy unless it is retrained frequently.
Retraining the model ensures it continues to perform well by training on new data. It is an ongoing process to ensure predictions are accurate.
A good retraining plan involves:
- Keeping track of model results
- Detecting decreases in accuracy or relevance
- Retraining with new data
- Redeploying the improved version
Retraining ensures that continuous integration for machine learning models is effective, and the system can adapt to new situations.
Best Practices to Ensure Successful ML Integration
When it comes to integrating machine learning models, it is not just about developing a model. It’s about building an integrated solution. Simple solutions with a clear structure and an emphasis on long-term performance over short-term gain work best.
Start Small and Scale
Incremental steps minimise risk and enable experimentation and learning. Rather than rolling out a complex system, it is better to start with a select use case and then scale up.
A practical approach includes:
- Starting with a basic model to address a single issue
- Validating in a safe environment
- Adding complexity and functionality once verified
- Growing according to user feedback and data
This approach means that incorporating machine learning models is feasible and affordable.
Human-in-the-loop
Models are not 100% accurate. Humans can help make predictions more accurate and instill confidence. This is particularly valuable in sensitive areas like health, finance, or customer service.
Humans contribute by:
- Validating predictions of the model
- Identifying and fixing errors and corner cases
- Giving feedback to enhance future results
This automation and human intervention improve strategies on how to deploy machine learning models in practice.
Monitor, Optimize, and Update
Machine learning systems are not static. They need to be monitored and improved to perform well.
The monitoring process should:
- Monitor the performance with metrics
- Identify declines in accuracy caused by changes to the data
- Use insights to fine-tune the models
- Keep models up-to-date
This continual process enables continuous integration for machine learning models and long-term success.
Grow your business with EXRWebflow on machine learning model integration.
Get in touch!
Common Pitfalls and Challenges in ML Integration
Although incorporating machine learning models can be highly beneficial, there are several issues that many teams encounter that can hinder or halt progress.
The most common are:
- Inaccurate predictions due to poor-quality data
- Lack of specific goals or outcomes
- Excessively complicated models that are hard to manage
- Poor deployment that doesn’t translate to production
- Insufficient monitoring, leading to deterioration in performance
According to industry reports, many machine learning projects do not make it to deployment as a result of these challenges. Taking steps to address these challenges early in the process increases the likelihood of machine learning model integration success.
Conclusion
The success of integrating machine learning models goes beyond technical skills. It has to be well-planned, well-fed, and well-monitored. Every phase, including the use case, deployment, and monitoring, is crucial to success.
Through pilot projects, human oversight, continuous monitoring, and upgrades, machine learning can go from proof of concept to delivering value for the business. Done right, it can be a sustainable and scalable component in today’s apps.
Frequently Asked Questions (FAQ)
What is the first step in integrating machine learning into an application?
The first step is assessing readiness. This involves assessing system readiness, data readiness, and business readiness before development.
How do I choose the right machine learning model?
The model type depends on the problem at hand. For instance, regression models for predicting a number, classification models for predicting a category, and clustering models for grouping data.
What is Natural Language Processing (NLP), and how is it used?
Natural Language Processing is a type of artificial intelligence that enables a machine to process natural language. It is used for chatbots, search engines, and text analysis.
How do I ensure my ML model is scalable?
Scaling can be done via cloud computing, API integration, and load balancing. Performance monitoring and auto-scaling also help in meeting the demands.
What are common challenges in machine learning integration?
Issues include bad data, lack of clear objectives, model complexity, ineffective deployment, and monitoring and maintenance.



