
FireBench is a simulation dataset designed to advance wildfire research by simulating controlled fire growth scenarios, which is critical to enabling better decision-making by fire officials.
In recent years, the severity and frequency of large wildfires have increased significantly due to a variety of factors, from changing climate and weather patterns to increased human activity at the wildland-urban interface. While wildfires play an important role in the natural cycle of some forests, large fires pose serious threats to communities and ecosystems. Frequent wildfires can disrupt, damage, and destroy infrastructure, livelihoods, lives, and property. For example, the recent surge in wildfires in the United States has expanded geographically, with annual burned area estimated to be approaching 7 million acres, the annual economic burden from wildfires is between $394 billion and $893 billion, and annual wildfire CO2 emissions exceed 50% of combustion emissions. In fact, greenhouse gas emissions from wildfires could wipe out years of emissions reductions. This is expected to worsen in fire-prone areas of the United States, Canada, Australia, and southern Europe, as well as around the world, even in areas with no history of large wildfires.
Firefighters and the research community have been researching ways to better understand and manage the impacts of wildfires. With rapid advances in machine learning (ML) and high-performance computing, we have been exploring how to apply this technology to improve fire risk assessments and fire resilience predictions to help communities and authorities manage wildfires. Some examples include using AI for wildfire perimeter tracking and using ML to predict fire spread from remote sensing data., We also released an efficient, scalable, high-fidelity TPU-based simulation framework to mitigate the data scarcity in developing ML-based fire prediction models. However, a key factor in effectively leveraging ML technologies for fire management is finding high-quality data, which can be challenging.
Therefore, in “FireBench: A High-Fidelity Ensemble Simulation Framework for Wildfire Behavior Exploration and Data-Driven Modeling,” we present a high-resolution simulation dataset aimed at advancing wildfire research. By expanding beyond fire regimes to include a comprehensive list of three-dimensional flow field variables, FireBench enables exploration of wildfire spread behavior and the coupling of atmospheric fluid dynamics and fire physics. It also supports the development of robust and interpretable ML models by capturing the underlying dependencies between relevant variables. To provide the research community with the insights needed to mitigate wildfire impacts, we have released the FireBench dataset on Google Cloud Platform.
FireBench Dataset
High-fidelity wildfire simulations are computationally expensive and it is difficult to generate comprehensive datasets for systematic parametric studies. Therefore, in fall 2023, we developed and released SWIRL-FIRE, a high-performance computational fluid dynamics framework optimized for TPU architectures. SWIRL-FIRE leverages numerical methods and parallelization strategies that enable large-scale simulations at a fraction of the cost of common approaches. The framework is integrated with our optimization platform Vizier for automated simulation management and data processing. This approach enabled us to generate a 1.36 PiB FireBench dataset in less than a week, using only 200,000 TPU hours.
The FireBench dataset was generated considering 117 different wind speed and slope combinations. These factors are important for predicting fire spread behavior, including eruptive fires, but understanding their combined effects presents an experimental challenge due to scale requirements and atmospheric uncertainties. SWIRL-FIRE overcomes these limitations, producing high-fidelity numerical simulations with precisely controlled simulation configurations and physical parameters.
The fire lasted 150 seconds, spreading over a 1.5 km long slope at a 15 degree angle, with wind speeds measured at a height of 6 m/s at 10 m above ground level.
result
As a demonstration of the dataset, instantaneous flow field results for 9 of the 117 ensembles in the dataset are plotted below. The snapshots were taken at representative times when the fire front reached the middle of the slope.

3D visualization of fire spread for nine ensembles with the mean fire front position at 500 m. The volume renderings are projections of potential temperature (indicated by fire- and smoke-like structures in the foreground of each figure) and axial (xz-plane) and vertical (yz-plane) velocity components. Each row contains simulations with different wind speeds (2, 6, 10 m/s from below) and each column represents a different slope angle (0, 15, 30 degrees from left). The ground color on the slope indicates the fuel density (green for high density, brown for low density).
These results show realistic fire behavior with good resolution in the turbulence field and reproduction of the fire waveform. As fuels on the ground burn, the fire rises up to tens of meters above the ground and spreads along the wind direction. As the fire rises, it interacts with local wind gusts and forms chaotic finger-like structures.
These simulations under different wind and slope conditions adequately capture the differences in fire dynamics. Comparing the results across rows reveals insights into the effect of wind speed, showing that as wind speed increases, a transition occurs from smoke-driven to convection-driven fires. In contrast, as slope angle increases, fires tend to move closer to the ground surface and flame height (measured perpendicular to the slope) decreases. This observation provides evidence for conclusions made based on theoretical analysis without extensive support from data, suggesting a transition between smoke-driven and convection-driven fire modes as a function of wind speed and slope angle.
To quantify the fire dynamics transition between plume and convective modes, we calculated the Froude number, a dimensionless number that measures the ratio of flow inertia to buoyancy. The figure below shows this regime diagram for the FireBench dataset, indicating the critical Froude number of 0.5 for the transition between plume and convective modes (white line).
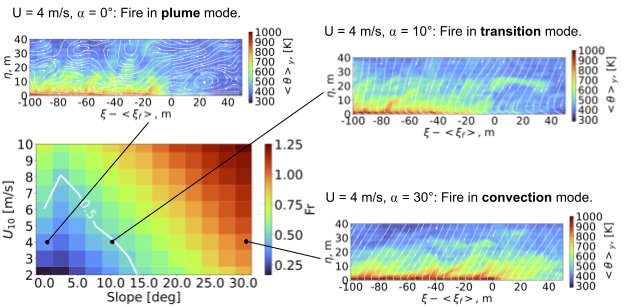
Regime diagram of the transition between plume and convective modes of a fire based on the Froude number. The graph shows the fire front in plume, transition, and convective modes. The white contours are the flow field streamlines specified by the velocity vectors in the flow direction and perpendicular to the flow direction.
The flow fields near the fire front for these two modes, as well as the transition point between them, are plotted as a direct visualization of the changes (subset panels). For the plume mode fire, the flames are oriented nearly vertically, and large-scale fluid motion is highly perturbed by the fire. In contrast, for the convection mode fire, the flames are attached close to the ground, there is no large-scale perturbation, and the streamlines are aligned along the vertical.
Try it for yourself
FireBench is available on Google Cloud Storage and is organized according to a tree structure. The GitHub repository contains a Colab notebook and an Apache Beam pipeline that demonstrate how to access and process the dataset. The notebook has a simple UI to browse the Firebench dataset. The notebook script scans the simulations of the public Firebench dataset to populate the UI dropdowns. It also plots simple slices of the data based on selections in the UI. The Apache Beam pipeline shows how to post-process the Firebench dataset. Since each simulation contains several terabytes of data, we use Apache Beam to run the post-processing code in parallel across multiple machines to reduce execution time. This example script calculates the mean, minimum, and maximum time series of all variables for a given simulation.
Advance
FireBench opens opportunities for ML tasks related to fire spread model development, fire and atmospheric dynamics investigations, and turbulent multiphase fluid flows. In the near future, FireBench will be adopted as a component of the dataset for the construction of Stanford University's Future Learning Approaches for Modeling and Engineering (FLAME) AI workshop, which will facilitate a forum for the exchange of ideas, data, methods, and models related to fluid dynamics, turbulence, and combustion field ML techniques that are essential for the development of energy, propulsion, climate, and safety systems.
At Google Research, we are committed to advancing wildfire research through the development and application of innovative technologies like FireBench, and building cutting-edge techniques to track wildfire spread. By fostering collaboration and knowledge sharing within the research community, we hope to accelerate progress towards a future where AI-powered tools improve wildfire prediction, prevention, and management. We believe open access to high-quality datasets like FireBench will enable researchers to develop more sophisticated models and strategies, ultimately helping to reduce the devastating impacts of wildfires on communities and ecosystems around the world.
Acknowledgements
This dataset was generated by researchers on the Athena team at Google Research: Cenk Gazen, Yi-Fan Chen, Matthias Ihme, and John Anderson. Special thanks to Carla Bromberg for making it public, and Karl Alexander Toepperwien for generating the animations.


