
Content in media, entertainment, advertising, education, and corporate training combines visual, audio, and motion elements to tell stories and convey information, making it much more complex than text where each word has a clear meaning. This poses unique challenges for AI systems that need to understand video content. Video content is multidimensional and combines visual elements (scenes, objects, actions), temporal dynamics (motion, transitions), audio components (dialogue, music, sound effects), and text overlays (subtitles, captions). This complexity poses significant business challenges as organizations struggle to search video archives, identify specific scenes, automatically categorize content, and extract insights from media assets for effective decision-making.
This model addresses this problem with a multivector architecture that creates separate embeddings for different content modalities. Instead of forcing all the information into one vector, the model generates a specialized representation. This approach preserves the rich, multifaceted nature of video data and enables more accurate analysis across visual, temporal, and audio dimensions.
Amazon Bedrock has expanded its capabilities to support TwelveLabs Marengo Embed 3.0 models with real-time text and image processing with synchronous inference. This integration allows businesses to implement faster video search capabilities using natural language queries while also supporting interactive product discovery through advanced image similarity matching.
In this post, we demonstrate how the TwelveLabs Marengo embedded model available on Amazon Bedrock enhances video understanding through multimodal AI. Use Amazon OpenSearch Serverless as a vector database with Marengo model embedding to build video semantic search and analysis solutions with semantic search capabilities that go beyond simple metadata matching for intelligent content discovery.
Understanding video embedding
An embedding is a dense vector representation that captures the semantic meaning of data in a high-dimensional space. Think of these as numerical fingerprints that encode the essence of the content in a way that machines can understand and compare. For text, an embedding might capture that “King” and “Queen” are related concepts, or that “Paris” and “France” have a geographic relationship. For images, embedding can be understood as: golden retriever and labrador Even though they look different, they are both dogs. The following heat map shows the semantic similarity scores between the following sentence fragments: “Two people talking,” “A man and a woman talking,” and “Cats and dogs are adorable animals.”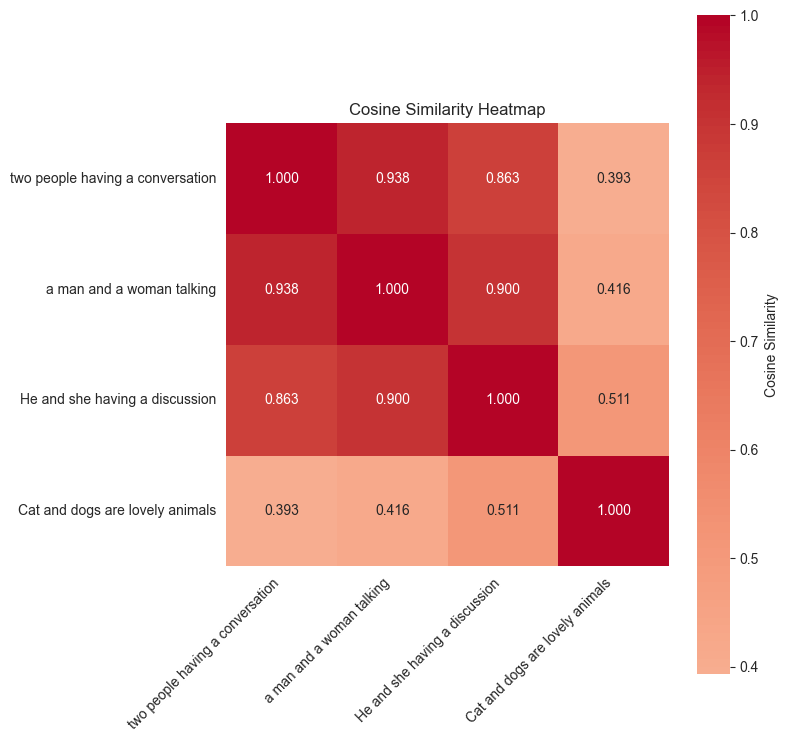
Video embedding challenges
Video is multimodal in nature, which poses unique challenges.
- visual information: objects, scenes, people, actions, and visual aesthetics
- audio information:Voice, music, sound effects, ambient noise
- Character information: captions, on-screen text, transcribed audio
Traditional single-vector approaches compress all this rich information into a single representation, often losing important nuances. This is where TwelveLabs Marengo's approach is unique in effectively addressing this challenge.
Twelvelabs Marengo: Multimodal embedding model
The Marengo 3.0 model generates multiple specialized vectors, each capturing a different aspect of the video content. A typical movie or television show combines visual and auditory elements to create a unified storytelling experience. Marengo's multi-vector architecture provides significant advantages in understanding this complex video content. Each vector captures a specific modality, avoiding information loss due to compressing diverse data types into a single representation. This allows for flexible searches targeting specific content aspects, such as visual-only, audio-only, or combined queries. Specialized vectors provide superior accuracy in complex multimodal scenarios while maintaining efficient scalability for large enterprise video datasets.
Solution overview: Marengo model features
In the next section, we demonstrate the power of Marengo's embedding technology through code samples. This example shows how Marengo handles different types of content and provides great search accuracy. The complete code sample can be found in this GitHub repository.
Prerequisites
Before you begin, make sure you have the following:
sample video
Netflix Open Content is open source content available under the Creative Commons Attribution 4.0 International License. To demonstrate the TwelveLabs Marengo model on Amazon Bedrock, we will use one of the videos called Meridian.

Create a video embed
Amazon Bedrock uses an asynchronous API for Marengo video embed generation. Below is a Python code snippet that shows an example of calling an API to retrieve a video from an S3 bucket location. See the documentation for complete supported features.
In the example above, 280 individual embeddings (one for each segment) are generated from a single video, allowing for precise temporal retrieval and analysis. Types of embeddings for multivector output from video can include:
- visual – Visual embedding of videos
- transcription – Embedding transcribed text
- audio – Embed audio in video
When working with audio or video content, you can set the length of each clip segment in your embedded creation. By default, video clips are automatically split at natural scene changes (shot boundaries). Audio clips are divided into even segments as close to 10 seconds as possible. For example, a 50 second audio file will have five segments of 10 seconds each, and a 16 second file will have two segments of 8 seconds each. By default, a single Marengo video embedding API produces visual text, visual images, and audio embedding. You can also change the default settings to output only certain embedding types. Use the following code snippet to generate a video embed with configurable options with the Amazon Bedrock API.
Vector Database: Amazon OpenSearch Serverless
This example uses Amazon OpenSearch Serverless as a vector database to store text, images, audio, and video embeddings generated from a particular video through a Marengo model. As a vector database, OpenSearch Serverless lets you quickly find similar content using semantic search without having to worry about managing servers or infrastructure. The following code snippet shows how to create an Amazon OpenSearch serverless collection.
Once the OpenSearch Serverless collection is created, create an index that contains properties such as vector fields.
Marengo Embedded Indexing
The following code snippet shows how to populate an OpenSearch index with embedded output from a Marengo model.
Cross-modal semantic search
Marengo's multi-vector design allows for searches across different modalities that are not possible with a single vector model. Search for videos using the input type of your choice by creating individually tailored embeddings for visual, audio, motion, and contextual elements. For example, if you type “jazz music performance,” a single text query returns video clips of musicians performing, jazz audio tracks, and concert hall scenes.
The following example demonstrates Marengo's great search capabilities across different modalities.
text search
Below is a code snippet demonstrating cross-modal semantic search functionality using text.
The top search results for the text query “person smoking in the room” yield the following video clips:

image search
The following code snippet demonstrates cross-modal semantic search functionality for a given image.

The top search results in the image above yield the following video clips.

In addition to semantic search using text and images on videos, Marengo models can also search videos using audio embeddings focused on dialogue and speech. The voice search feature helps users search for videos based on a specific speaker, dialogue content, or topic spoken. This creates a comprehensive video search experience that combines text, images, and audio to understand videos.
conclusion
Combining TwelveLabs Marengo and Amazon Bedrock opens exciting new possibilities for video understanding through a multivector, multimodal approach. In this post, we have considered practical examples such as image-to-video search with temporal precision and detailed text-to-video matching. With just one Bedrock API call, we transformed a single video file into 336 searchable segments that respond to text, visual, and audio queries. These capabilities create opportunities for natural language content discovery, streamlined media asset management, and other applications that enable organizations to better understand and leverage video content at scale.
As video continues to dominate the digital experience, models like Marengo provide a solid foundation for building more intelligent video analytics systems. Check out the sample code and discover how understanding multimodal video can transform your applications.
About the author
 Wei Te I'm a Machine Learning Solutions Architect at AWS. He is passionate about helping customers achieve their business goals using cutting-edge machine learning solutions. Outside of work, I enjoy outdoor activities such as camping, fishing, and hiking with my family.
Wei Te I'm a Machine Learning Solutions Architect at AWS. He is passionate about helping customers achieve their business goals using cutting-edge machine learning solutions. Outside of work, I enjoy outdoor activities such as camping, fishing, and hiking with my family.
 Lana Chan Senior Specialist Solutions Architect for Generative AI at AWS within a global specialist organization. She specializes in AI/ML, with a focus on use cases such as AI voice assistants and multimodal understanding. She works closely with clients across a variety of industries, including media, entertainment, gaming, sports, advertising, financial services, and healthcare, helping them transform their business solutions through AI.
Lana Chan Senior Specialist Solutions Architect for Generative AI at AWS within a global specialist organization. She specializes in AI/ML, with a focus on use cases such as AI voice assistants and multimodal understanding. She works closely with clients across a variety of industries, including media, entertainment, gaming, sports, advertising, financial services, and healthcare, helping them transform their business solutions through AI.
 Yangyang Zhang She is a Senior Generative AI Data Scientist at Amazon Web Services and a Generative AI Specialist working on cutting-edge AI/ML technologies to help customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in electrical engineering. Outside of work, I love traveling, working out, and exploring new things.
Yangyang Zhang She is a Senior Generative AI Data Scientist at Amazon Web Services and a Generative AI Specialist working on cutting-edge AI/ML technologies to help customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in electrical engineering. Outside of work, I love traveling, working out, and exploring new things.


