Are you interested in the complex world of large-scale language models (LLMs) and the terminology that surrounds them? From the fundamental aspects of training and fine-tuning to the cutting-edge concepts of transformers and reinforcement learning, we'll help you understand the terminology. Understanding it is the first step to unlocking the powerful algorithms that power modern AI language systems. This article details 25 key terms to enhance your technical vocabulary and provide insight into the mechanisms that make LLM so transformative.
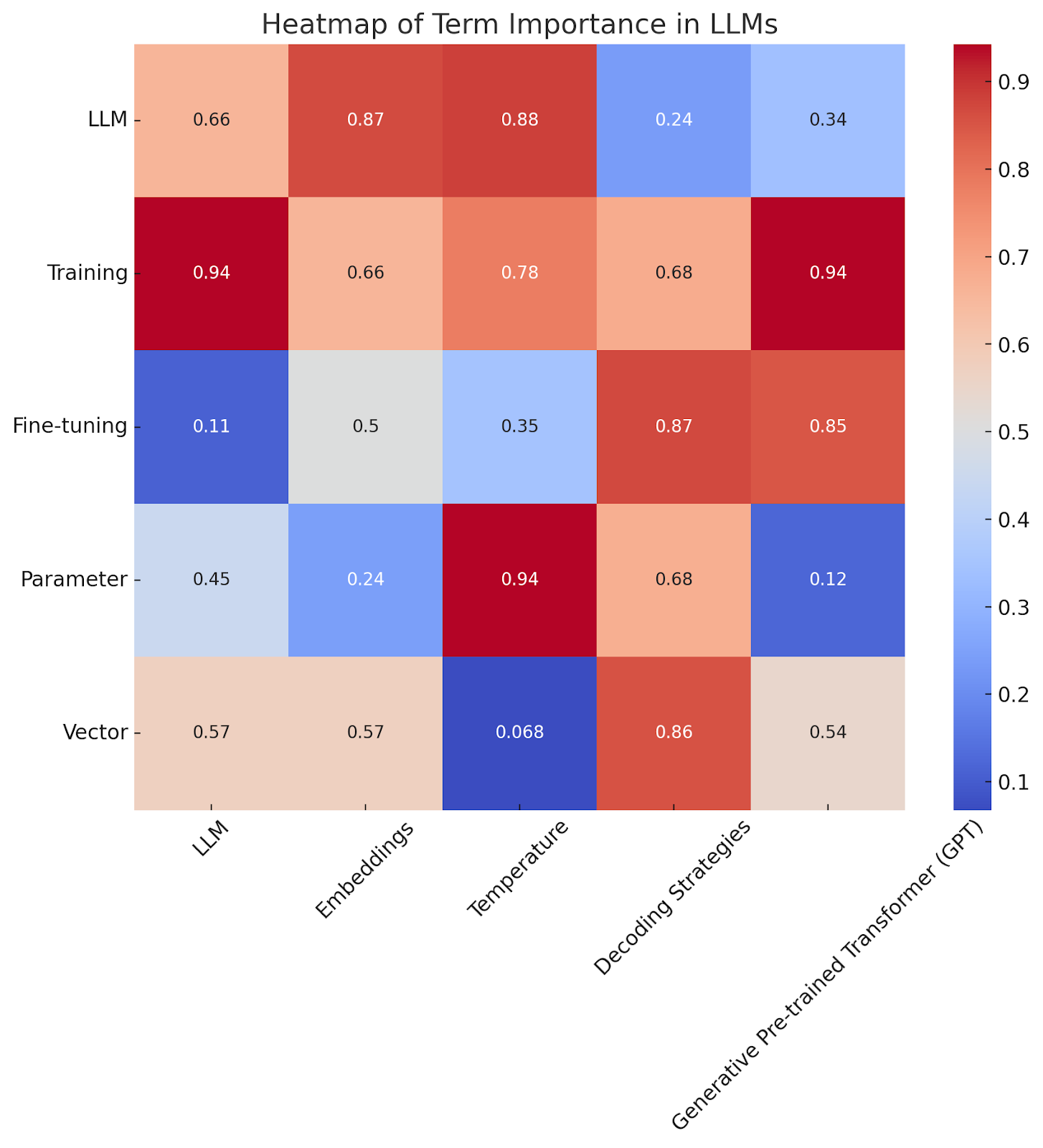
Heatmap representing the relative importance of terms in the context of LLM

1. LLM (Large-Scale Language Model)
Large Language Model (LLM) is an advanced AI system trained on extensive text datasets to understand and generate human-like text. They use deep learning techniques to process and generate language in a context-sensitive manner. The development of LLMs such as OpenAI's GPT series, Google's Gemini, Anthropic AI's Claude, and Meta's Llama models represent significant advances in natural language processing.
2. training
Training refers to exposing a language model to large datasets to teach it to understand and produce text. The model learns to predict the next word in the sequence and improves its accuracy over time by tuning internal parameters. This process is the basis for developing AI to handle language tasks.
3. Tweak
Fine-tuning is the process of further training (or tuning) a pre-trained language model on a smaller, specific dataset to specialize in a particular domain or task. This improves the model's performance on tasks that are not extensively covered by the original training data.
Four. parameters
In the context of neural networks, including LLMs, parameters are variable parts of the model's architecture learned from training data. Parameters (such as neural network weights) are adjusted during training to reduce the difference between the predicted and actual outputs.
Five. vector
In machine learning, a vector is an array of numbers that represents data in a format that an algorithm can process. Language models transform words and phrases into vectors (often called embeddings) that capture semantic meaning that the model can understand and manipulate.
6. embedded
An embedding is a dense vector representation of text, where well-known words have similar representations in vector space. This technology helps understand the context and semantic similarities between words, which is essential for tasks such as machine translation and text summarization.
7. tokenization
Tokenization is the division of text into parts called tokens, such as words, subwords, and characters. This is a preliminary step before using language models to process text, as it helps to handle different text structures and languages.
8. transformers
Transformers are neural network architectures that rely on a mechanism called self-attention to evaluate the influence of different parts of input data differently. This architecture is highly effective for many natural language processing tasks and is the core of most modern LLMs.
9. Note
The neural network's attention mechanism allows the model to focus on different segments of the input sequence while generating a response, mirroring how human attention works during activities such as reading and listening. This capability is essential for understanding context and generating consistent responses.
Ten. inference
Inference refers to using a trained model to make predictions. In the context of LLM, inference is when a model uses the knowledge it learned during training to generate text based on input data. This is the phase in which the practical application of LLM is realized.
11. temperature
In language model sampling, temperature is a hyperparameter that controls the randomness of the predictions by scaling the logit before applying the softmax. Higher temperatures produce more random output, while lower temperatures make the model's output more deterministic.
12. frequency parameters
The language model's frequency parameter adjusts the likelihood of a token based on how often it occurs. This parameter helps balance the generation of common and rare words, and affects the model's diversity and accuracy in text generation.
13. sampling
Sampling in the context of language models refers to generating text by randomly selecting the next word based on a probability distribution. This approach allows the model to generate diverse and more creative text output.
14. Top-k sampling
Top-k sampling is a technique in which the model's selection of next words is restricted to the k words that are most likely to be next, according to the model's predictions. This method reduces the randomness of text generation while allowing for variation in the output.
15. RLHF (Reinforcement learning from human feedback)
Reinforcement learning from human feedback is a technique for fine-tuning models based on human feedback rather than just raw data. This approach tailors the model's output to human values and preferences, greatly increasing its real-world effectiveness.
16. decoding strategy
The decoding strategy determines how the language model chooses output sequences during generation. Strategies include greedy decoding, where the most likely next word is selected at each step, and beam search, which extends greedy decoding by considering multiple possibilities simultaneously. These strategies have a significant impact on the consistency and variety of output.
17. Language model prompts
Prompting a language model involves designing inputs (or prompts) that guide the model in producing a particular type of output. Effective prompts can improve performance on tasks such as question answering and content generation without additional training.
18. transformers xl
Transformer-XL extends existing transformer architectures to enable learning dependencies beyond a fixed length without compromising temporal consistency. This architecture is very important for tasks involving long documents or sequences.
19. Masked Language Modeling (MLM)
Masked language modeling masks certain input data segments during training, prompting the model to predict hidden words. This method forms the basis of models such as his BERT, which employs MLM to increase the effectiveness of pre-training.
20. Inter-sequence model (Seq2Seq)
Seq2Seq models are designed to transform sequences from one domain to another, such as translating text from one language or transforming questions into answers. These models typically include an encoder and a decoder.
twenty one. Generate Pre-Trained Transformer (GPT)
Generative Pre-trained Transformer refers to a set of language processing AI models designed by OpenAI. GPT models are trained using unsupervised learning to generate human-like text based on input.
twenty two. perplexed
Perplexity evaluates the predictive accuracy of a probabilistic model for a given sample. Within a language model, reduced confusion suggests better prediction of test data and is typically associated with smoother and more accurate text production.
twenty three. multi head attention
Multihead attention, a component of the transformer model, allows the model to simultaneously focus on different representational subspaces at different locations. This enhances the model's ability to dynamically focus on relevant information.
twenty four. Context embedding
A contextual embedding is a representation of a word that takes into account the context in which the word appears. Unlike traditional embeddings, these are dynamic and change based on the surrounding text, providing a richer understanding of meaning.
twenty five. autoregressive model
Autoregressive models in language modeling predict subsequent words based on previous words in a sequence. This approach is the basis of models like GPT, where each output word becomes the input for the next, making it easier to generate consistent long texts.


Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at Indian Institute of Technology Kharagpur. I'm passionate about technology and want to create new products that make a difference.