


Large-scale language models (LLMs) face a significant challenge in the training process: the scarcity of high-quality internet data. Predictions suggest that by 2026, the available data pool will be exhausted, forcing researchers to rely on model-generated or synthetic data for training. This shift brings both opportunities and risks. While some studies have shown that scaling up synthetic data can improve performance on complex inference tasks, other studies have shown worrying trends. Training on synthetic data can lead to poor model performance, amplification of biases, propagation of misinformation, and reinforcement of undesirable stylistic traits. A key challenge lies in designing synthetic data that effectively addresses data scarcity without compromising the quality and integrity of the resulting models. This task is particularly challenging due to the current lack of understanding of how synthetic data affects the behavior of LLMs.
Researchers have explored various approaches to address the challenges of LLM training with synthetic data. Standard methods such as teacher forcing on expert data have proven to be limited, especially in mathematical reasoning. Efforts to generate positive synthetic data aim to mimic high-quality training data using sources such as stronger teacher models or self-generated content. While this approach has shown promise, challenges remain in validating the quality of synthetic mathematical data. Concerns remain about bias amplification, model collapse, and overfitting to erroneous steps. To mitigate these issues, researchers are investigating the use of negative model-generated responses to identify and unlearn problematic patterns in the training data.
Researchers from Carnegie Mellon University, Google DeepMind, and MultiOn have published a study investigating the impact of synthetic data on LLM's mathematical reasoning capabilities. The study looked at both positive and negative synthetic data and found that while positive data improves performance, it does so at a slower rate than pre-training. Notably, self-generated positive responses often match the effectiveness of twice the amount of data from a large model. The researchers introduce a robust approach that uses negative synthetic data and compares it to positive data at critical steps. The technique amounts to step-by-step advantage-weighted reinforcement learning and shows the potential to scale efficiency up to 8x compared to using only positive data. The study develops scaling laws for both data types on a popular inference benchmark, providing valuable insights for optimizing the use of synthetic data to improve LLM performance on mathematical reasoning tasks.

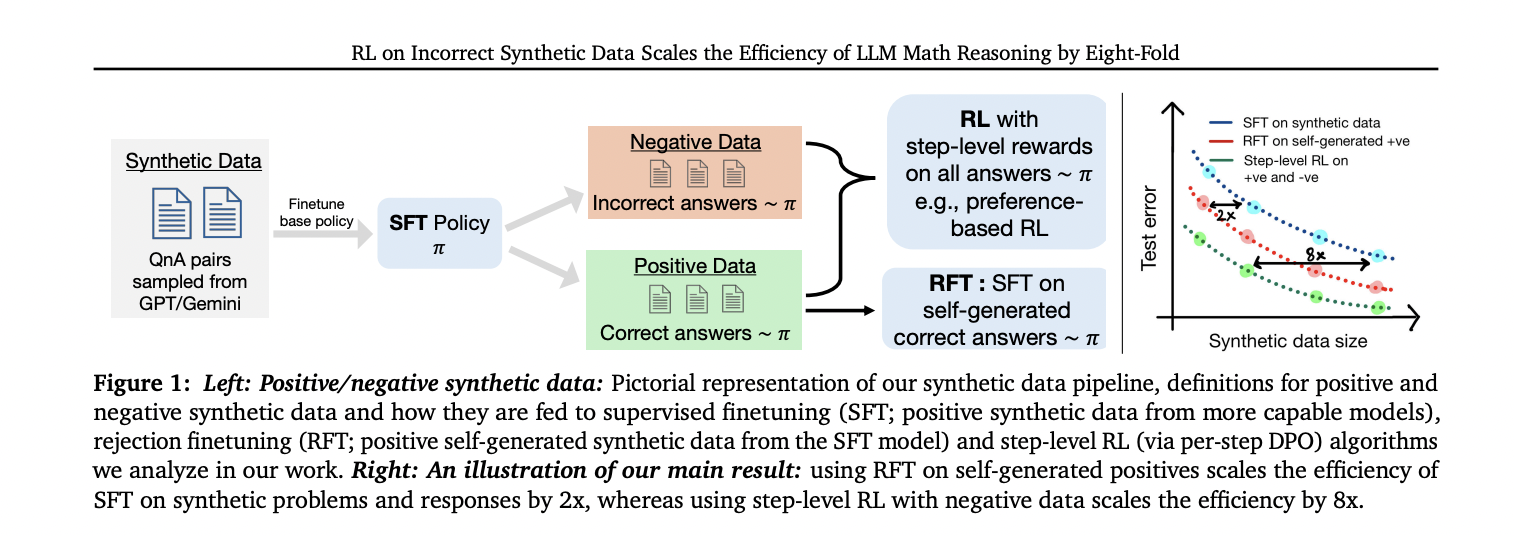
The detailed architecture of the proposed method includes several main components.
- Synthetic Data Pipeline:
- It prompts capable models like GPT-4 and Gemini 1.5 Pro to generate new problems that resemble real-world problems.
- You get a resolution trace with step-by-step reasoning for these problems.
- Solution Implement a binary reward function to validate the accuracy of the trace.
- Build the dataset:
- We create a positive synthetic dataset from correct problem-solution pairs.
- Using the solution produced by the model, we generate positive and negative datasets.
- Learning algorithm:
- Supervised Fine Tuning (SFT):
- We train 𝒟syn using the following token predictions:
- Supervised Fine Tuning (SFT):
- Rejection Fine Tuning (RFT):
- We use the SFT policy to generate a positive response to the 𝒟syn problem.
- We apply the next token prediction loss to these self-generated positive responses.
- Optimize your settings:
- It uses Direct Preference Optimization (DPO) to learn from both positive and negative data.
- We implement two variants: standard DPO and stepwise DPO.
- Step-by-step DPO identifies the “first pitfalls” in solution tracing and focuses on the critical steps.
This architecture allows for a comprehensive analysis of different synthetic data types and learning approaches, allowing us to study their impact on LLM mathematical reasoning capabilities.
This study reveals important insights into scaling synthetic data for LLM mathematical reasoning. Scaling positive data shows improvement, but at a slower rate than pre-training. Remarkably, self-generated positive data (RFT) outperforms data from more capable models, becoming twice as efficient. The most striking results are obtained by strategically using negative data in a step-by-step direct preference optimization, resulting in eight times more data-efficient compared to positive data alone. This approach consistently outperforms other methods, highlighting the critical importance of carefully constructing and using both positive and negative synthetic data in LLM training for mathematical reasoning tasks.

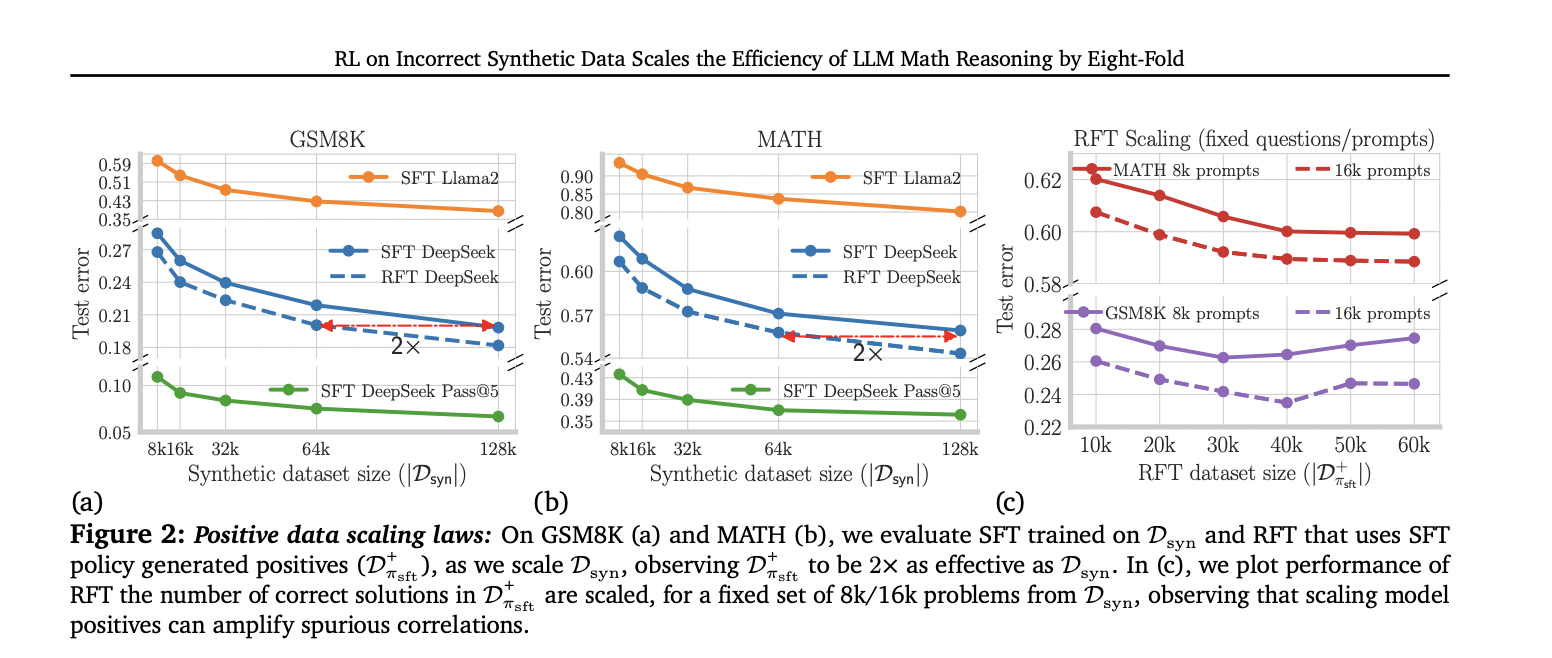
This study investigates the impact of synthetic data on improving the mathematical reasoning ability of LLMs. It reveals that traditional methods using positive solutions from advanced models have limited efficiency. Self-generated positive data from a fine-tuned 7B model improves efficiency by a factor of two, but can amplify the dependency on erroneous steps. Remarkably, incorporating negative (erroneous) traces addresses these limitations. By using negative data to estimate step-by-step benefits and applying reinforcement learning techniques, this study demonstrates an 8x improvement in efficiency on synthetic data. The approach significantly improves the mathematical reasoning ability of LLMs by effectively balancing positive and negative synthetic data, utilizing a preference optimization objective.
Please check paperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 45,000+ ML subreddits


Asjad is an Intern Consultant at Marktechpost. He is pursuing a B.Tech in Mechanical Engineering from Indian Institute of Technology Kharagpur. Asjad is an avid advocate of Machine Learning and Deep Learning and is constantly exploring the application of Machine Learning in Healthcare.

