


Machine learning focuses on creating algorithms that allow computers to learn from data and improve their performance over time. It has revolutionized areas such as image recognition, natural language processing, and personalized recommendations. This field of research leverages vast datasets and advanced computational power to push the boundaries of what is possible in artificial intelligence, opening new frontiers in automation, decision-making, and predictive analytics.
One of the big challenges facing machine learning is the lack of transparency in how models make decisions. These models are often highly accurate and act as “black boxes”, providing minimal insight into the internal logic. This lack of interpretability is particularly concerning in sensitive fields such as medicine, finance, and law, where understanding the rationale behind decisions is important. Stakeholders in these areas need transparent models, as the outcomes of automated decision-making can have significant ethical and practical implications.
Existing research includes popular benchmarks such as GSM8k, MATH, and MBPP for evaluating inference in large-scale language models (LLMs). These benchmarks include datasets that test models on elementary mathematical reasoning, coding tasks, and problem-solving skills. Additionally, recent studies on overfitting have measured the generalization ability of models using modified versions of existing datasets such as ImageNet and CIFAR-10. These frameworks evaluate LLM inference by comparing model performance on new and known data.

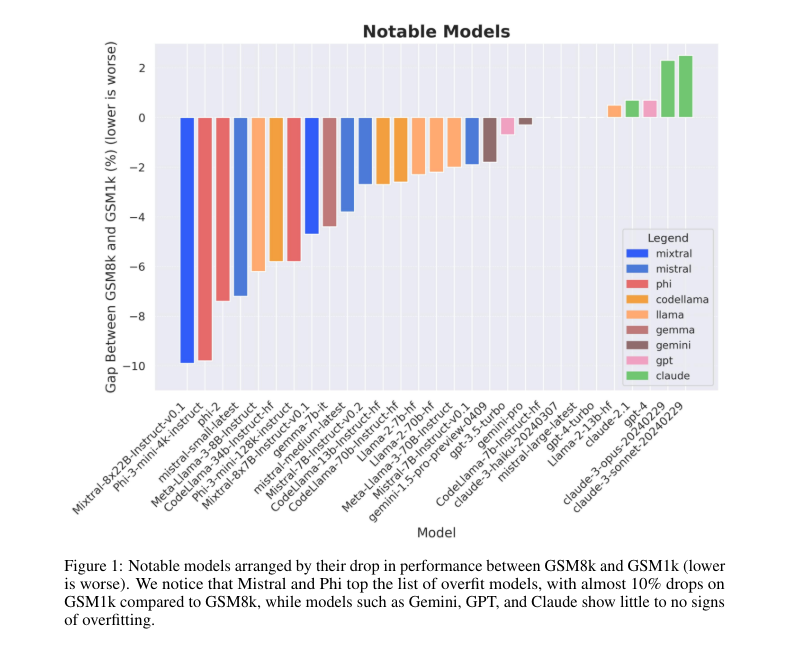
Researchers at Scale AI have introduced GSM1k, a new benchmark created to measure the overfitting and inference abilities of LLMs. Researchers developed this benchmark by creating 1,250 elementary math problems that mirror the complexity and content of existing benchmarks such as GSM8k. This benchmark aims to identify whether a model relies on memory or has true inference ability by comparing model performance across similar but different datasets. is.
The methodology behind GSM1k involves generating a new dataset of 1,250 elementary mathematics problems. These are designed to match the complexity of benchmarks such as GSM8k, ensuring comparable difficulty. The researchers employed human annotators to create questions that required basic arithmetic and reviewed the questions through multiple quality checks. They compared the results of the GSM1k and GSM8k models to measure the difference in performance, highlighting how the models solve problems rather than memorizing answers. This setup allows you to clearly understand the functionality of your model and identify systematic overfitting.

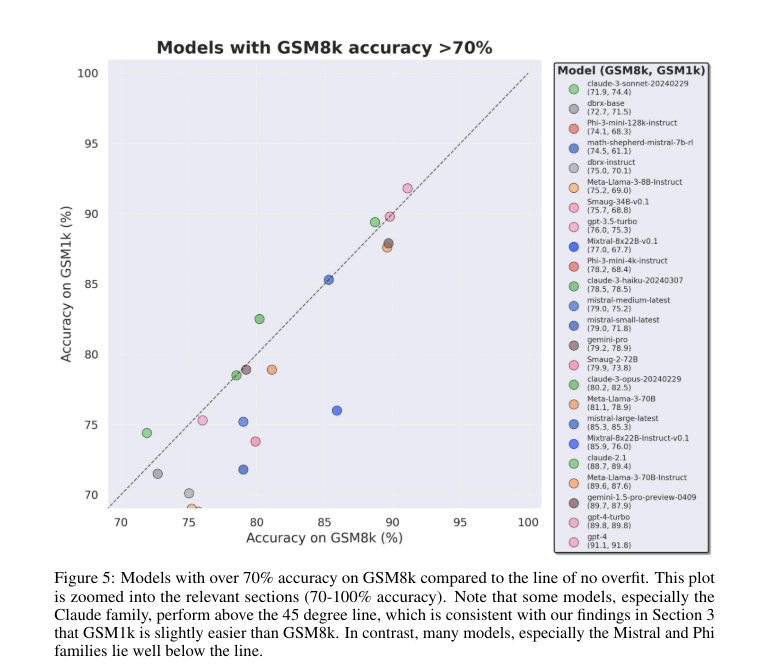
This study revealed significant differences in model performance between GSM8k and GSM1k, and identified systematic overfitting in certain models. For example, on Phi-3 he found that going from GSM8k to GSM1k reduced accuracy by 10% and depended on memorized data. However, other models such as Gemini and Claude had minimal differences, with less than 5% difference in accuracy. These findings suggest that some models have strong inference abilities, while others rely on memorization of the training data, which is a significant difference between his two datasets. evidenced by significant performance gaps.
In conclusion, this study provides a new approach to assess model interpretability and performance through GSM1k, a benchmark designed to measure the inference of machine learning models. By comparing their results to the existing GSM8k dataset, the researchers revealed different levels of overfitting and inference across different models. The importance of this study lies in its ability to distinguish between true inference and memorization in models, highlighting the need for methods to improve interpretability and guiding future advances in machine learning.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland LinkedIn groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 41,000+ ML subreddits


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated double degree in materials from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast and is constantly researching applications in areas such as biomaterials and biomedicine. With a strong background in materials science, he explores new advances and creates opportunities to contribute.


