Los Angeles, December 11, 2025 — Marktechpost releases the ML Global Impact Report 2025 (AIResearchTrends.com). This education report analysis includes more than 5,000 papers from more than 125 countries published in the Nature family of journals between January 1 and September 30, 2025. The scope of this report is strictly limited to this specific research topic and is not a comprehensive assessment of research worldwide. This report focuses only on the specific studies presented and does not represent a complete assessment of research worldwide.
of ML Global Impact Report 2025 Focus on three key questions:
- In which fields has ML become part of the standard methodological toolkit, and in which areas has adoption remained sparse?
- Which types of problems are most likely to rely on ML, such as high-dimensional imaging, sequence data, or complex physics simulations?
- Based on the global footprint of these selected 5,000 papers, how ML usage patterns vary by geography and research ecosystem.
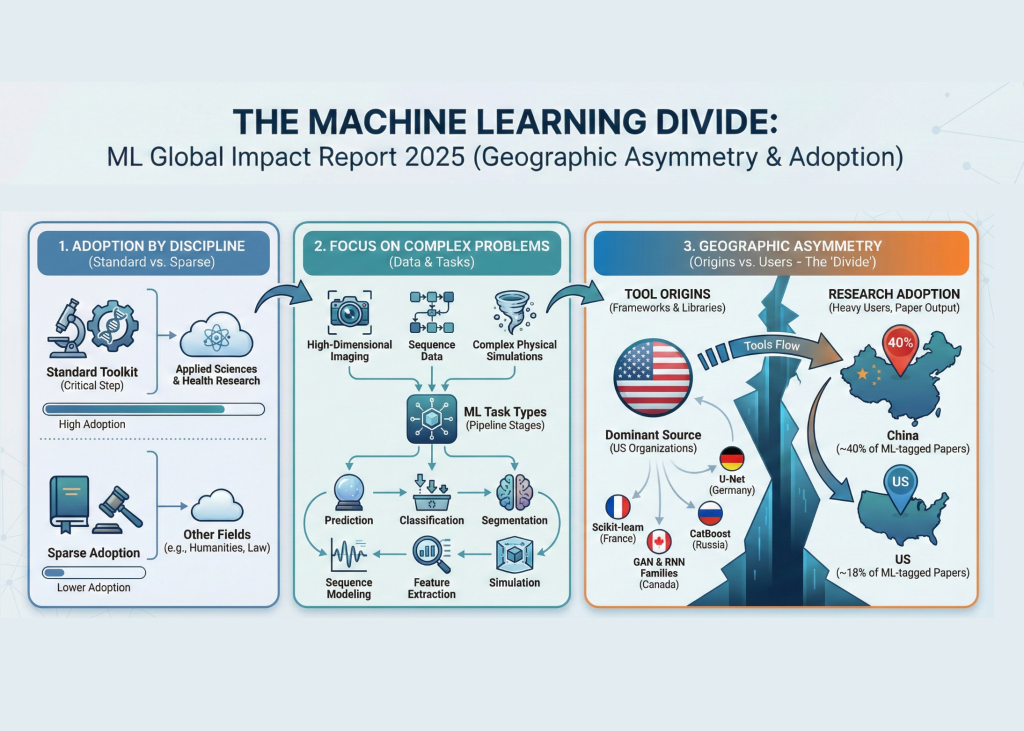
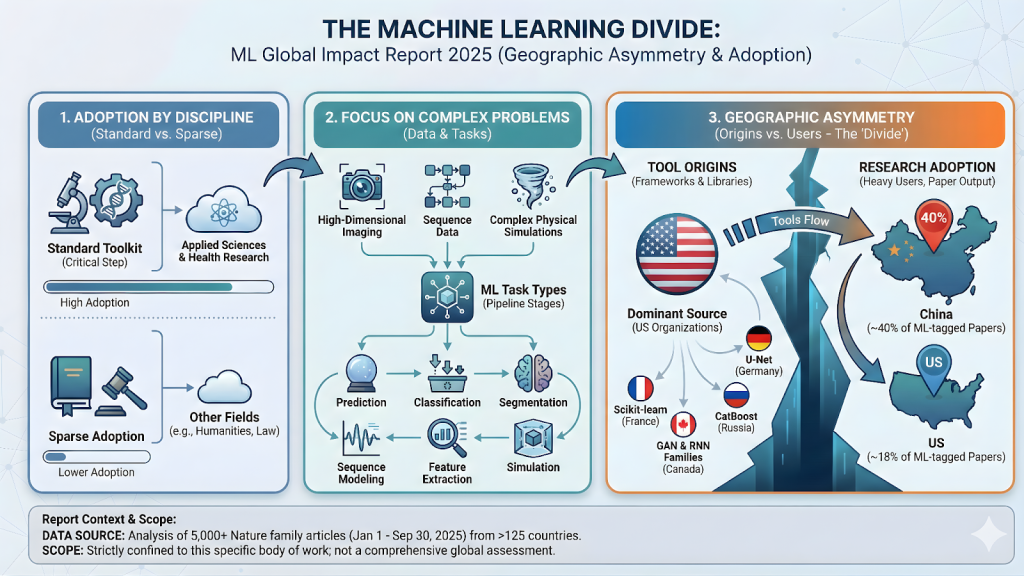
ML is most often part of a standard methodological toolkit in the field of applied science and health research, where it is often used as a key step within a larger experimental workflow rather than the primary subject of the research itself. Analysis of the literature shows that ML adoption is focused on these areas, with tools serving to enhance existing research pipelines. This report aims to distinguish these commonly used areas from other areas where machine learning integration is still less frequent.
The types of problems most likely to rely on machine learning are those that involve complex data analysis tasks, such as high-dimensional imaging, sequence data analysis, and complex physics simulations. This report tracks specific task types such as prediction, classification, segmentation, sequence modeling, feature extraction, and simulation to understand where ML is being applied. This classification highlights the usefulness of machine learning across different stages of the research process, from initial data processing to final output generation.
ML usage patterns show a clear geographic separation between the origins of the tool and heavy users of the technology. The majority of machine learning tools cited in the corpus come from US-based organizations that maintain many widely used frameworks and libraries. In contrast, China is recognized as the largest contributor to research papers, accounting for approximately 40% of all ML-tagged papers, significantly higher than the United States' approximately 18%. The report also highlights the global ecosystem, citing frequently used non-US tools such as Scikit-learn (France), U-Net (Germany), and CatBoost (Russia), as well as Canadian-originated tools such as the GAN and RNN families. ML Global Impact Report 2025 provides deep insights into the global research ecosystem and highlights how machine learning has become a standard methodological tool, primarily in the fields of applied science and health research. This analysis reveals that the use of ML is focused on complex data challenges such as high-dimensional imaging and physics simulation. A key finding is a clear geographic separation between the origins of ML tools (many of which are maintained by organizations in the United States) and the most frequent users of the technology, with China significantly overrepresented in the number of ML-tagged research papers in the analyzed corpus. These patterns are unique to the more than 5,000 Nature family papers analyzed and highlight this report's focused view of current research workflows.

Michal Sutter is a data science expert with a master's degree in data science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.



