Swiggy detailed the architecture of the company’s real-time machine learning ranking system for autocomplete search suggestions and explained how the platform combines OpenSearch’s search, feature store, and ranking learning models while operating under strict latency requirements. The system replaced a manually tuned heuristic ranking approach with a learned ranking model run directly within OpenSearch, improving the relevancy of autocomplete while avoiding additional services and network hops.
The company says autocomplete requests are particularly sensitive to latency, as each keystroke can trigger a new search query. Therefore, traditional autocomplete systems tend to rely on lexical matching and static ranking rules that are optimized for speed. Swiggy’s new approach divides the workflow into two stages: candidate generation and ranking.
When a user begins typing, the system first uses a combination of OpenSearch’s lexical search and embedding-based similarity search to obtain a wide range of possible candidates. This search layer is optimized for recall and fast response times. The candidate suggestions are then passed to a ranking layer, where a machine learning model sorts the results based on predicted relevance.
The ranking system incorporates real-time signals such as user interaction history, click behavior, query context, and item popularity. These features are combined with offline-trained models that are deployed for online inference. The feature store is used to provide both precomputation and streaming capabilities, allowing the system to react to recent user behavior while avoiding expensive real-time computations. The ranking layer is built using a ranking learning approach integrated with OpenSearch. It is typically implemented using a framework such as OpenSearch LTR, and uses model families such as RankLib and gradient-boosting tree methods such as XGBoost, which are used for ranking and reranking tasks.
The autocomplete platform also includes a continuous feedback loop that uses live user interaction data to retrain the ranking model. Click-through rates, conversions, and order behavior are streamed to an offline training pipeline, where updated ranking models are generated and stored in a model registry before being deployed to online ranking services.

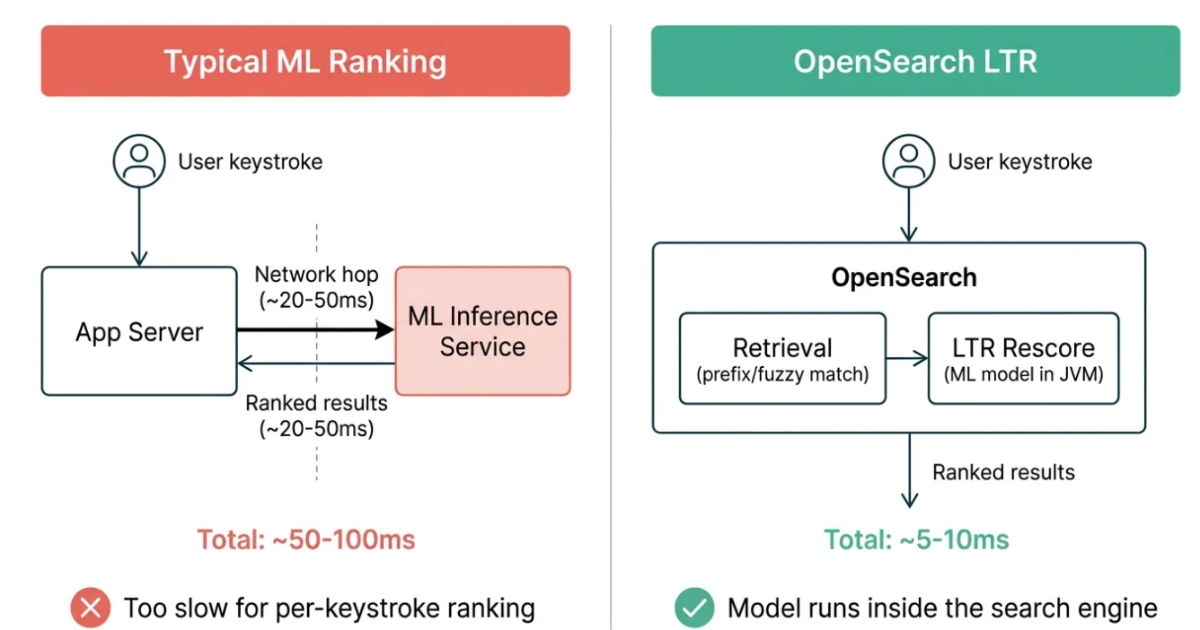
Popular ML Ranking Services and OpenSearch LTR Latency (Source: Swiggy Blog Post)
This architecture is designed to operate under strict performance requirements. Autocomplete requests are highly interactive and require low-latency responses, leading to design choices that favor lightweight models and optimized inference paths. Rather than relying on complex and deep models of online paths, the system balances model complexity and service efficiency to maintain responsiveness at scale.

Setting up training and deployment of Autocomplete ML models using Opensearch LTR (Source: Swiggy blog post)
The system also includes a feedback loop where user interactions are continuously collected and used to improve the ranking model. Click-through rates and conversion signals are fed into an offline training pipeline, allowing the model to adapt to evolving user behavior and new query patterns. This allows the autocomplete system to adapt to new trends without manually updating the rules.
According to Swiggy engineers, the design integrates machine learning with traditional rules and search-driven components without sacrificing latency. Separating candidate generation and ranking allows each stage to be optimized independently, while the use of feature stores and streaming pipelines ensures consistency between the training and serving environments.


