Spatial reasoning remains a major challenge for visual language models, hindering their ability to perform accurately in real-world applications that require precise measurements and understanding of the environment. Siyi Chen, Mikaela Angelina Uy, and Chan Hee Song, along with colleagues, are addressing this limitation by introducing SpaceTools, a new framework that allows models to effectively leverage a set of tools to enhance spatial understanding. Through a two-step training process called double-interactive reinforcement learning, the researchers demonstrated that the model learns to adjust tools such as depth and pose estimators, moving beyond reliance on predefined tool sequences. This approach achieves state-of-the-art results on established spatial understanding benchmarks, enables reliable object manipulation by robotic arms, represents a significant advance over existing methods, and paves the way for more capable and adaptive embodied artificial intelligence.
LLM enhances spatial reasoning by robots
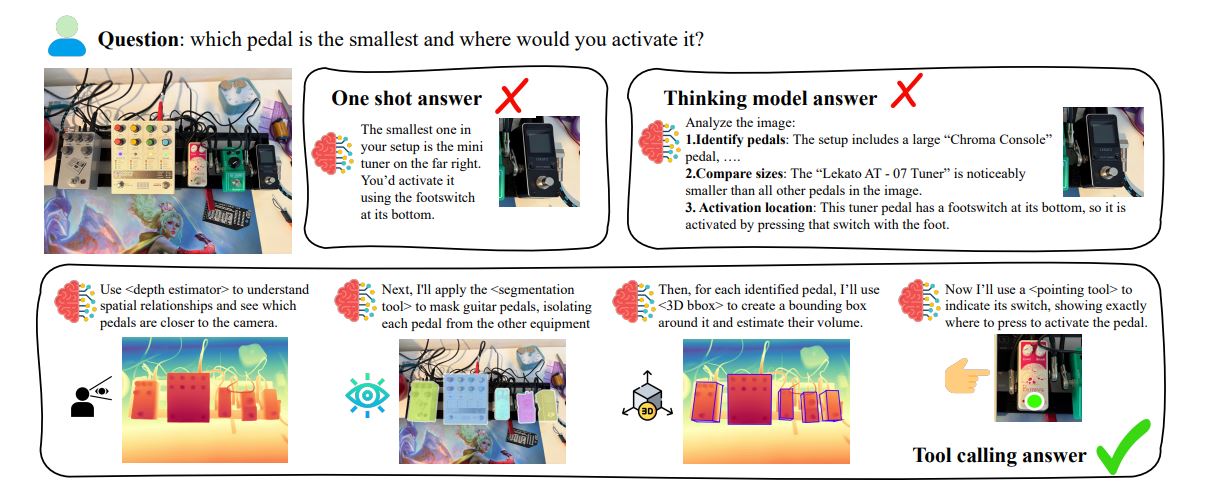
In this study, we present a system that combines large-scale language models (LLMs) with specialized visual tools to perform complex spatial reasoning specifically for robot manipulation. This system effectively integrates object detection, depth estimation, and grasp planning functions and represents a significant advancement in robot intelligence. The team identified areas for improvement, including enhancing the accuracy and robustness of the tool and integrating real-time robot feedback into the training process. The system overcomes the limitations of relying solely on LLM or traditional computer vision by leveraging a set of visual tools to extract relevant information from images. It properly infers spatial relationships, estimates grasp positions, and controls the robot to grasp and place objects. Recognizing the limitations of existing models in precise spatial tasks important to robotics, researchers designed DIRL to allow for the coordination of multiple tools through interactive exploration and feedback. This approach allows the model to autonomously discover optimal tool usage patterns and overcome the challenges of relying on fixed tool pipelines and manual prompts. DIRL works in two phases. It begins with an educational phase that combines a specialist demonstration of a single tool with tracing from the system utilizing all available tools.
The second phase, Exploration, further refines the multitool's tuning through continuous reinforcement learning. To address the computational demands of interactive training, the team developed Toolsshed, a platform that hosts compute-intensive computer vision tools as fast, on-demand services. DIRL incorporates actual probabilistic tool outputs into the learning loop to facilitate inferences about tool reliability and discover improved query strategies. This effort addresses the challenge of equipping VLM with the ability to utilize tools without relying on predefined pipelines or extensive manual prompting. The team achieved significant improvements in spatial understanding benchmarks and demonstrated reliable real-world manipulation using the robotic arm. DIRL works in two phases, combining demonstrations by one tool specialist trained through interactive reinforcement learning with traces from all tool-based systems.
This allows VLM to improve multitool tuning through continuous reinforcement learning. Experiments reveal that SpaceTools, a VLM trained using this method, achieves significant performance improvements on the RoboSpatial benchmark compared to standard fine-tuning and baseline reinforcement learning approaches. The team also introduced Toolsshed, an interactive platform designed to host a variety of computer vision tools, facilitating seamless communication between VLM and external resources for both data collection and training. This method allows VLM to effectively tune multiple visual tools, such as depth estimation and segmentation tools, through a two-phase training process that includes both demonstration and continuous reinforcement learning. The resulting system, SpaceTools, achieved state-of-the-art performance on established spatial understanding benchmarks and successfully controlled a robotic arm. This study shows that VLM can acquire complex spatial reasoning skills through adjustments to learned tools, rather than requiring architectural changes or large-scale data fine-tuning.
Experimental results show that DIRL outperforms standard fine-tuning and single-tool reinforcement learning approaches, with significant improvements over existing methods. In particular, training with a single powerful tool unexpectedly improved performance on a variety of tasks, suggesting the ability to transfer skills and generalize outside of the domain. Researchers acknowledge that overuse of tools and misinterpretation of subtle outputs remain challenges for VLM, and future work will focus on addressing these limitations to further refine tool integration and improve the reliability of spatial inference in complex environments.


