
Today I’m sharing a snapshot of Slonk (Slurm on Kubernetes), the system we use internally to run our GPU research cluster. character.ai.
Although it is not a fully supported open source project, it is exposing the architecture and tools behind it to solve one of the most vexing problems in machine learning infrastructure. Give researchers the productivity of a traditional high performance computing (HPC) environment while leveraging the operational benefits of Kubernetes..
Problem: Bridging two worlds
When we started expanding our training infrastructure, we faced a common dilemma. Recruiting researchers slam – Reliable scheduler with fair queue and gang scheduling. We needed an infrastructure team. Kubernetes For orchestration, health checks, and autoscaling. Essentially, researchers needed simplicity and speed. Operation required stability and efficient GPU sharing. Slonk offers both:
- familiar slam UX for users (
sbatch,squeuepartition, preemption, FIFO + backfill) - Kubernetes As a control plane for resiliency, automated surgery, and integration with other services
- A unified way to manage heterogeneous clusters and clouds allows you to seamlessly move capacity between research and service.
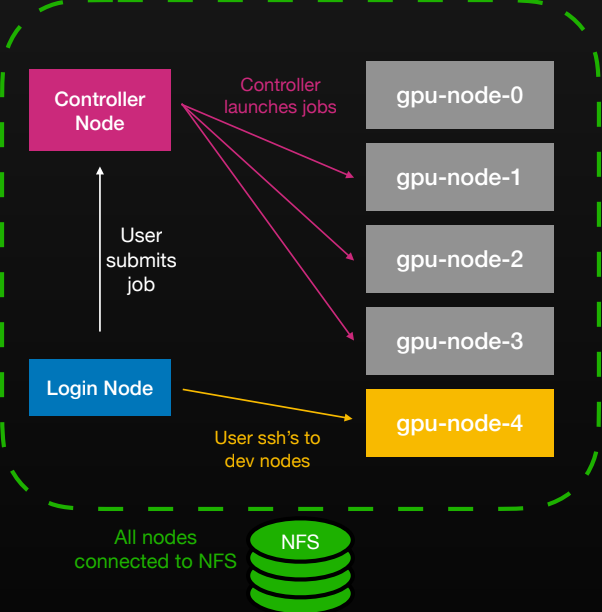
A researcher’s daily workflow is classic HPC. Connect to the network with SSH. login nodeedit the code above Shared NFS Homesubmit jobs and track logs. Thronx controller Schedule and allocate resources and the results will return to the same volume.
Architecture: Containers built from the ground up
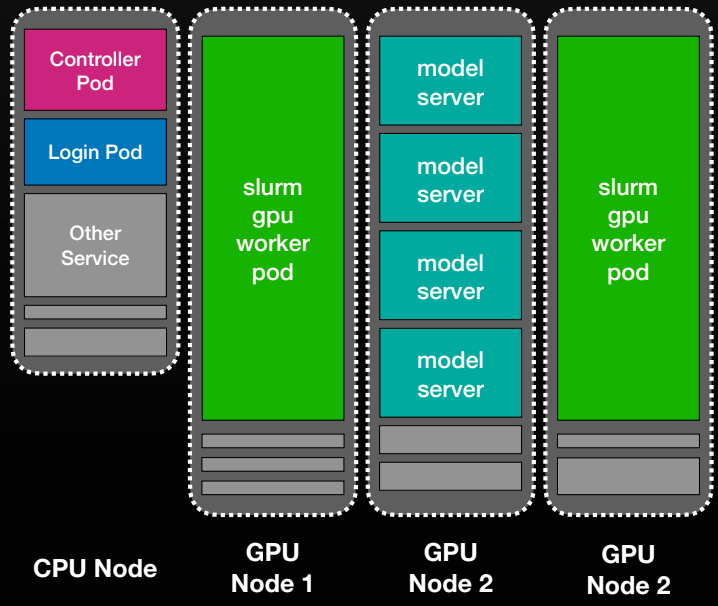
At its core, Slonk treats SLURM nodes as long-running Kubernetes pods. do three stateful set – Controllers, Workers, Logins – Therefore each SLURM “node” maps directly to a pod (gpu-node-0, gpu-node-1,…).
controller pod is running slurmctld;worker pod is executed slurmd;Login pod provides SSH access and a familiar research environment. Other workloads can coexist on the same physical machine.
The key details that make this seamless are:
- Base image as mini‑VM: Each pod contains a lightweight init layer with the SLURM daemon, SSH, and system services. The configuration is injected via configuration mapand
/homePersistent NFS volume. we git‑sync Shared prolog, epilog, and authentication helper scripts to keep nodes consistent. - Authentication and networking: SSO is mapped to Unix accounts through LDAP, and each node gets its own Kubernetes service to avoid large-scale DNS fanout issues.
- Observability and soundness: Logs and metrics flow through open source monitoring tools. custom goal state operator Manage node health, perform GPU and network checks, and automatically repair failures.
- Topology awareness: SLURM’s network-aware scheduler ensures that large jobs get nearby GPUs in the same fabric segment.
The result is a system that feels like a traditional supercomputing cluster. Researchers still use it. sbatch and shared /home Manage your directories while leveraging the resiliency, automation, and portability of Kubernetes. For TPU and slice-based hardware, allocations are co-located by leveraging SLURM’s network topology awareness. With preconfigured capacity in your cluster, jobs start in seconds instead of minutes.
technical challenges
- Adjusting two (+1 hidden) schedulers: The most difficult part is not containerizing SLURM, but syncing its resource views with Kubernetes. We built a tuning utility that continually adjusts the state of the pods to ensure that SLURM and Kubernetes agree on what is alive, drained, and preempted.
- Massive health check: Large training runs fail for subtle reasons such as bad GPUs, unstable NICs, and misconfigured NVLinks. Slonk includes a set of health checks (GPU, network, storage) that run before, during, and after jobs. Bad nodes are automatically ejected and recycled.
- topology awareness: For large multi-node jobs, network proximity becomes important. SLURM’s topology-aware scheduler co-locates GPUs within the same fabric segment.
- Machine lifecycle management: We built a Kubernetes operator that enforces a goal state on all nodes using a CRD that stores node events and state. If a node fails a check, it can automatically repair or alert engineers.
- DNS and network size: Thousands of SSH-enabled pods burden service discovery. Assign each node its own Kubernetes service for predictable latency and stable connectivity.
Given these challenges, our technical goal is simple. When a researcher or an automated system marks a SLURM node as failed, Slonk automatically drains the corresponding Kubernetes node and restarts the VM on the cloud provider to recover from the failure.
If a node repeatedly fails health checks, it is removed from the SLURM pool to maintain job stability. Meanwhile, our observability system tracks all faulty nodes for investigation and long-term reliability improvement.
Why this approach works
Slonk simplifies cluster management across clouds. Managed SLURM setups often vary by OS, drivers, and monitoring tools, but Slonk provides a consistent environment with the same CUDA stack and observability everywhere. By adjusting StatefulSet replicas and Kubernetes, you can dynamically migrate GPU resources between training and inference. PriorityClass Allow production workloads to prioritize training as needed.
Researchers work in a way that sends work all the time. sbatch my_job.sh – Kubernetes, on the other hand, silently handles node restarts, container health, and logging. SLURM manages job schedules and quotas, and Kubernetes ensures operational stability. Together, these keep the system simple, reliable, and flexible.
what we are releasing
Open source snapshots include:
- Helm chart and container specifications for controller, Loginand worker stateful set.
- Health check scripts, prologue/epilogue, and cluster utilities are distributed in the following ways: git-sync
- Kubernetes operator for machine lifecycle management and observability (goal state + CRD).
- Example configuration for an NFS-based shared home directory.
this Reference implementation. Fork and build and adapt to your environment.
Repository: https://github.com/character-ai/slonk
would you like to join
We’re looking for an ML Infrastructure Engineer who loves the intersection of HPC and cloud. If you want to scale model training and inference, accelerate researcher productivity, and design systems that power distributed systems. Work with us. The best infrastructure is one that researchers never have to think about.

