


Two-level optimization (BO) is a growing research field that has attracted attention due to its success in various machine learning tasks such as hyperparameter optimization, meta-learning, and reinforcement learning. BO is a two-level structure in which the solution of an outer problem depends on the solution of an inner problem. However, despite its flexibility and applicability to many problems, BO has not been widely used for large-scale problems. The main challenge is the interdependence between the upper and lower levels of the problem, which hinders the scalability of BO. This interdependence poses significant computational challenges, especially when dealing with large-scale problems.
This paper discusses two main areas of related research. The first is two-level optimization, which can be divided into two types: (a) approximate implicit differentiation (AID) and (b) iterative differentiation (ITD). Both approaches follow a two-loop scheme and require a lot of computational cost for large problems. The second is data reweighting, where the proportion of training data sources significantly affects the performance of large-scale language models (LLMs). This paper discusses different methods to reweight data sources for optimal training data mixture. However, none of these methods guarantee optimal data weights, and no scalable experiments on models with more than 30 billion parameters have been conducted.
Researchers from the Hong Kong University of Science and Technology and the University of Illinois at Urbana-Champaign present ScaleBiO, a novel two-level optimization method that can scale to 34 billion LLMs for data reweighting tasks. By incorporating a memory-efficient training method called LISA, ScaleBiO is able to run these large-scale models on eight A40 GPUs. This is the first time that BO has been applied to such large-scale LLMs, demonstrating its potential in real-world applications. ScaleBiO effectively optimizes the learned data weights and provides similar convergence guarantees as traditional first-order BO methods for smooth and strongly convex objective functions.
Experiments on data reweighting show that ScaleBiO works well on models of different sizes, including GPT-2, LLaMA-3-8B, GPT-NeoX-20B, and Yi-34B. BO effectively filters out irrelevant data and selects only informative samples. Two experiments were conducted: (a) a small-scale experiment to better understand ScaleBiO, and (b) a real-world application experiment to verify its effectiveness and scalability. To test the effectiveness of ScaleBiO on small-scale language models, experiments were conducted on three synthetic data tasks using GPT-2 (124M): data denoising, multilingual training, and instruction-following fine-tuning.
To evaluate ScaleBiO, 3,000 data are sampled from each source and reweighted, then 10,000 data are sampled based on the final weights from BO to train the model. To demonstrate the effectiveness of ScaleBiO, we apply the learned sampling weights to fine-tune the LLaMA-3-8B and LLaMA-3-70B models. LLMs' ability to follow instructions is assessed using single-answer scored MT-Bench, which poses complex, multi-turn, open-ended questions to the chat assistant and uses “LLMs as judges” for the evaluation. This benchmark is well-known for its suitability to human preferences and contains 80 questions evenly distributed across eight categories: writing, role-play, elicitation, reasoning, mathematics, coding, knowledge I (STEM), and knowledge II (humanities/social sciences).

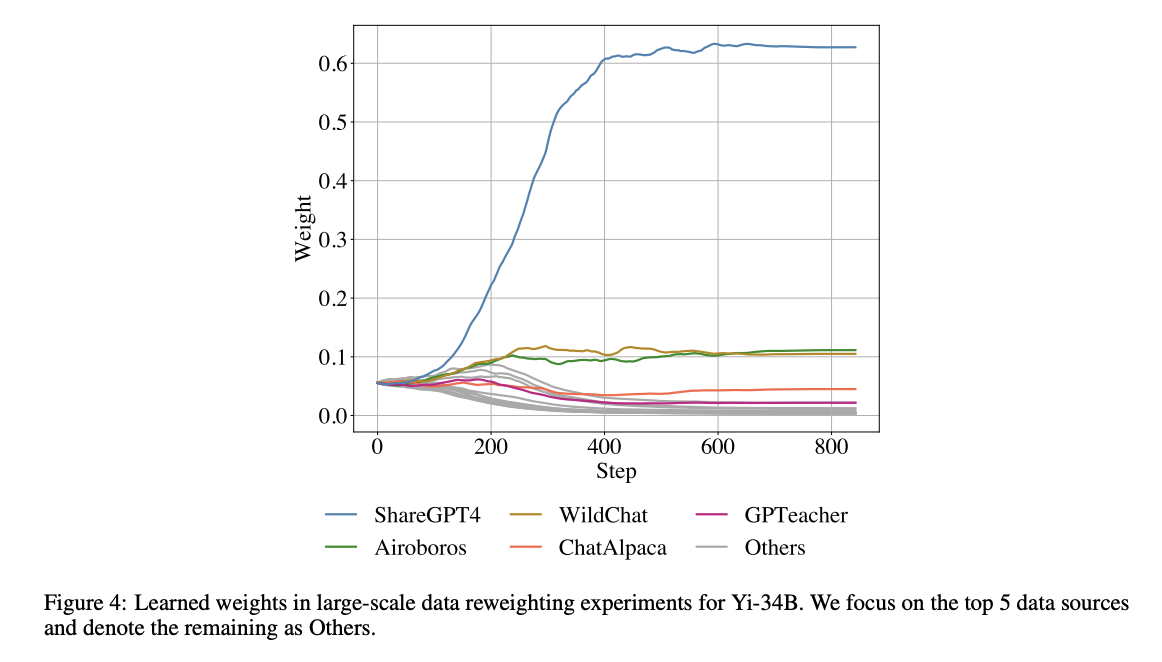
In summary, the researchers proposed ScaleBiO, a two-level optimization instance that can scale to 34 billion LLMs on data reweighting tasks. ScaleBiO enables data reweighting in models with at least 7 billion parameters, creating an efficient way to filter and select pipelines to improve model performance on various tasks. Furthermore, the sampling weights learned on LLaMA-3-8B can be applied to larger models such as LLaMA-3-70B, resulting in significant performance improvements. However, the effectiveness of ScaleBiO on large-scale pretraining has yet to be tested, which requires significant computational resources. Thus, demonstrating success in a large-scale fine-tuning setting could be an important first step.
Please check Paper and GitHubAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 45,000+ ML subreddits


Sajjad Ansari is a final year undergraduate student at Indian Institute of Technology Kharagpur. As a technology enthusiast, he delves into practical applications of AI with a focus on understanding the impact of AI technology and its impact on the real world. He aims to express complex AI concepts in a clear and understandable manner.


