![]()
summary
YouTube Fail videos reveal major blind spots for major AI models. They fight surprises and rarely rethink their first impressions. Even advanced systems like the GPT-4o stumble upon simple plot twists.
Researchers from the University of British Columbia, the Vector Institute of AI, and Nanyang University of Technology have put their top AI models at a pace into top AI models using OOPS's over 1,600 YouTube Fail videos! Dataset.
The team created a new benchmark called BlackSwansuite to test how well these systems handle unexpected events. Like people, AI models are fooled at amazing moments, but unlike people, they refuse to change their minds, even after seeing what actually happened.
Example: A man waving a pillow near a Christmas tree. AI assumes he is aiming for someone nearby. In reality, the pillow knocks on the ornament from the wood, which is attacked by the woman. Even after watching the entire video, AI sticks to the original false guess.
advertisement
Videos span a variety of categories and most often feature traffic accidents (24%), child accidents (24%), or pool accidents (16%). What brings them all together is an unpredictable twist that even people often overlook.
https://www.youtube.com/watch?v=2mvikghwv1k
Three types of tasks
Each video is split into three segments: Setup, Surprise and Aftermath. The benchmark challenges LLM with different tasks for each stage. In the “prediction” task, the AI will only look at the beginning of the video and try to predict what will come next. The “Detective” task only shows the beginning and end, and asks the AI to explain what happened during that time. The “Reporter” task provides the AI with the full video and checks if it can update the assumptions after seeing the full story.

The test covers both closed models such as the GPT-4O and Gemini 1.5 Pro, as well as open source systems such as Llava-Video, Vila, VideoChat2 and Videollama 2. The results highlight obvious weaknesses. On the Detective Task, the GPT-4o answered correctly with just 65% of the time. In comparison, humans have correctly won 90%.
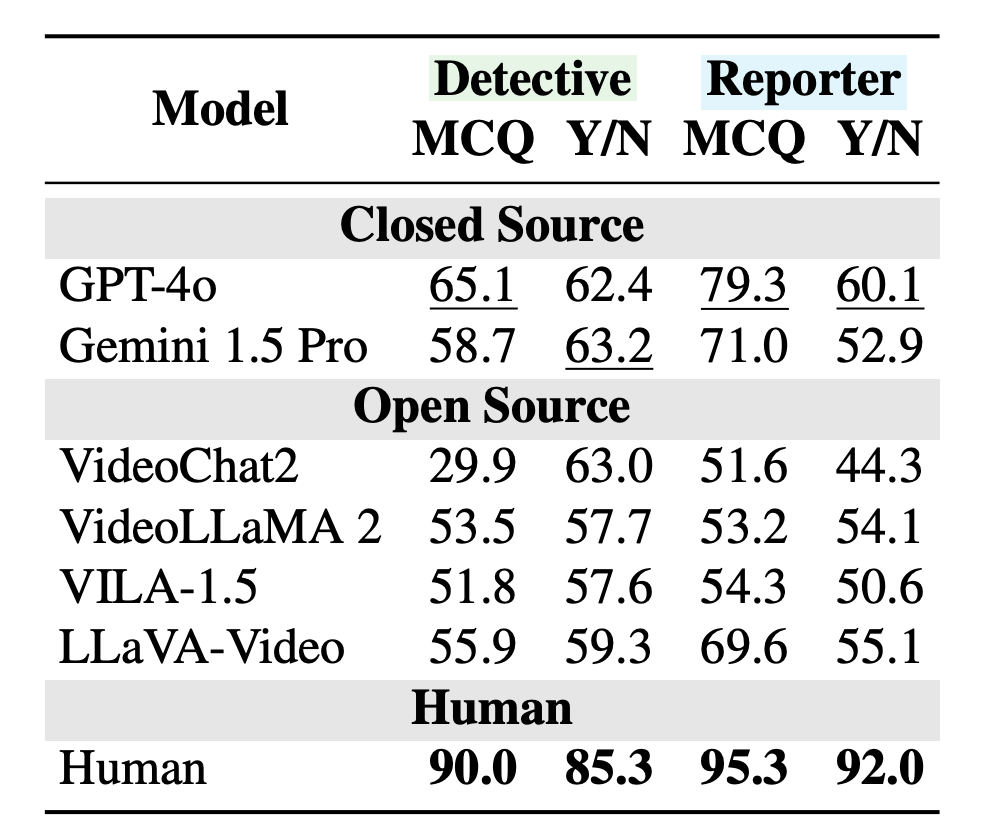
The gap widened further when the model had to reconsider the initial guess. When asked to reconsider the prediction after watching the entire video, GPT-4o only managed 60% accuracy (32% points for humans (92%)). The system tended to double the first impression, ignoring new evidence.
Other models like the Gemini 1.5 Pro and Llava-Video showed the same pattern. Researchers said performance fell sharply on video. This was the first time that even people felt was tricky.
recommendation
Do garbage trucks not drop trees?
The route in question lies in how these AI models train. They find and learn patterns in millions of videos and hope that those patterns will be repeated. So, when the trash can drop trees instead of picking up trash, the AI becomes confused. There is no pattern for that.

To identify the problem, the team tried to exchange AI video recognition for detailed human-written explanations of the scene. This has resulted in a 6.4% increase in Llava-Video performance. Adding more explanations gave us an additional 3.6% increase.
Ironically, this merely highlights the weaknesses of the model. If AI only works well when it does a heavy perceptual lift, it fails to “see” and “understand” before actual inference begins.
In contrast, humans are to immediately rethink their assumptions when new information is displayed. Current AI models do not have this mental flexibility.
This flaw can have serious consequences for real applications such as self-driving cars and autonomous systems. Life is full of surprises. The kids dash into the street, objects falling off the truck, and other drivers do unexpected things.
The researchers have made the benchmark available on Github and Hugging Face. They hope others will use it to test and improve their own AI models. As long as major systems are stumbled by simple failure videos, they are not prepared for real-world unpredictability.