
- Meta’s Ranking Engineer Agent (REA) autonomously executes key steps throughout the end-to-end machine learning (ML) lifecycle of an ad ranking model.
- This post describes REA’s ML experimentation capabilities: autonomous generation of hypotheses, starting training jobs, debugging failures, and iterating results. In future posts, we will discuss additional REA features.
- REA reduces the need for manual intervention. Manage asynchronous workflows over days or weeks through hibernation and wakeup mechanisms, with human oversight of key strategic decision points.
- In its first operational deployment, REA achieved the following:
- Twice the model accuracy: REA-driven iterations doubled the average model accuracy over the baseline over six models.
- 5x engineering output: Through REA-driven iterations, three engineers submitted proposals to begin improving the eight models. This is a task that previously required two engineers per model.
Bottlenecks of traditional ML experiments
Meta’s advertising system delivers personalized experiences to billions of people across Facebook, Instagram, Messenger, and WhatsApp. Powering these interactions are highly sophisticated, complex, and massively distributed machine learning (ML) models that are continually evolving to serve both advertisers and the people using the platform.
Optimizing these ML models has traditionally been time-consuming. Engineers create hypotheses, design experiments, initiate training runs, debug failures across complex codebases, analyze results, and iterate. Each complete cycle can span from several days to several weeks. As Meta’s model has matured over the years, meaningful improvements have become increasingly difficult to find. The manual, sequential nature of traditional ML experiments is a bottleneck to innovation.
To address this, Meta built the Ranking Engineer Agent, an autonomous AI agent designed to drive the end-to-end ML lifecycle and iteratively evolve Meta’s ad ranking models at scale.
Introducing REA: A new kind of autonomous agent
Many of the AI tools used in ML workflows today function as assistants. They are reactive, task-scoped, and session-limited. Although they can assist with individual steps (such as creating hypotheses, creating configuration files, and interpreting logs), they typically cannot run experiments end-to-end. Engineers still need to decide what to do next, reestablish context, drive progress across long-running jobs, and debug inevitable failures.
REA is different. An autonomous agent built to drive the end-to-end ML lifecycle, orchestrating and driving ML experiments across multi-day workflows with minimal human intervention.
REA addresses three major challenges in autonomous ML experimentation.
- Long-term asynchronous workflow autonomy: ML training jobs run for hours or days, far beyond what a session-bound assistant can manage. REA maintains persistent state and memory across multi-round workflows spanning days or weeks and maintains coordination without continuous human supervision.
- High-quality and diverse hypothesis generation: The quality of an experiment is determined by the hypothesis driving it. REA integrates results from historical experiments and cutting-edge ML research into surface configurations that are unlikely to be obtained from a single approach, improving with each iteration.
- Resilient operations within real-world constraints: Autonomous agents cannot be stopped due to infrastructure failures, unexpected errors, or compute budgets. REA adapts within predefined guardrails and continues the workflow without escalating routine failures to humans.
REA addresses these challenges through the following methods: Hibernation and wakeup mechanism For continuous operations over several weeks, Dual source hypothesis engine It combines a historical insights database with a deep ML research agent. 3-step planning framework Work within engineer-approved computing budgets (validate → mix → leverage).
How REA autonomously manages multi-day ML workflows
REA is built on the core insight that optimizing complex ML is not a single task. This is a multi-step process that unfolds over days to weeks. Agents must reason, plan, adapt, and persist across this horizon.
Long-term workflow autonomy
Traditional AI assistants work quickly, responding to a prompt and then waiting for the next query. ML experiments don’t work that way. Training jobs run over hours or days, and agents must continue to make adjustments over these extended timelines.
REA uses a hibernation and wakeup mechanism. When the agent starts a training job, it delegates the wait to a background system, shuts down to conserve resources, and automatically picks up where it left off when the job completes. This enables efficient, continuous operation over long periods of time without the need for continuous human monitoring.
To support this, Meta built REA on top of Confucius, an internal AI agent framework designed for complex multi-step inference tasks. It provides powerful code generation capabilities and a flexible SDK for integration with Meta’s internal tool system, including a job scheduler, experiment tracking infrastructure, and codebase navigation tools.
High-quality and diverse hypothesis generation
The quality of your hypothesis directly determines the quality of your ML experiments. REA leverages two specialized systems to generate diverse, high-quality ideas.
- Historical Insights Database: A curated repository of past experiments enables in-context learning and pattern recognition across previous successes and failures.
- ML Research Agent: A deep exploration component that uses Meta’s historical insights database to explore baseline model configurations and suggest new optimization strategies.
By synthesizing insights from both sources, REA reveals constructs that are unlikely to emerge from any single approach alone. The most impactful improvements to REA combine architectural optimization and training efficiency techniques, which are the result of this cross-system approach.
Resilient execution within real-world constraints
Real-world experiments are conducted under computing constraints and inevitable failure. REA addresses both through structured planning and autonomous adaptation.
REA suggests a detailed exploration strategy, estimates total GPU computing costs, and reviews the approach with engineers before executing the plan. A typical multi-stage plan proceeds through three stages:
- verification: Individual hypotheses from different sources are tested in parallel to establish a quality baseline.
- combination: Combine promising hypotheses to explore synergistic improvements.
- Exploitation (intensive optimization): The most promising candidates are actively explored to maximize results within the approved computing budget.
When REA encounters obstacles such as infrastructure issues, unexpected errors, or suboptimal results, it adjusts the plan within predefined guardrails rather than waiting for human intervention. Consult runbooks for common failure patterns, make prioritization decisions (such as excluding jobs with obvious out-of-memory errors or training on instability signals such as loss explosions), and debug preliminary infrastructure failures based on first principles. This resiliency is important for engineers to maintain long-term task autonomy with periodic rather than continuous monitoring.
REA operates with strict safeguards in place. This only works with Meta’s ad ranking model codebase. Engineers allow explicit access control through preflight checklist reviews, and REA proactively checks compute budgets and stops or pauses execution if thresholds are reached.
REA system architecture
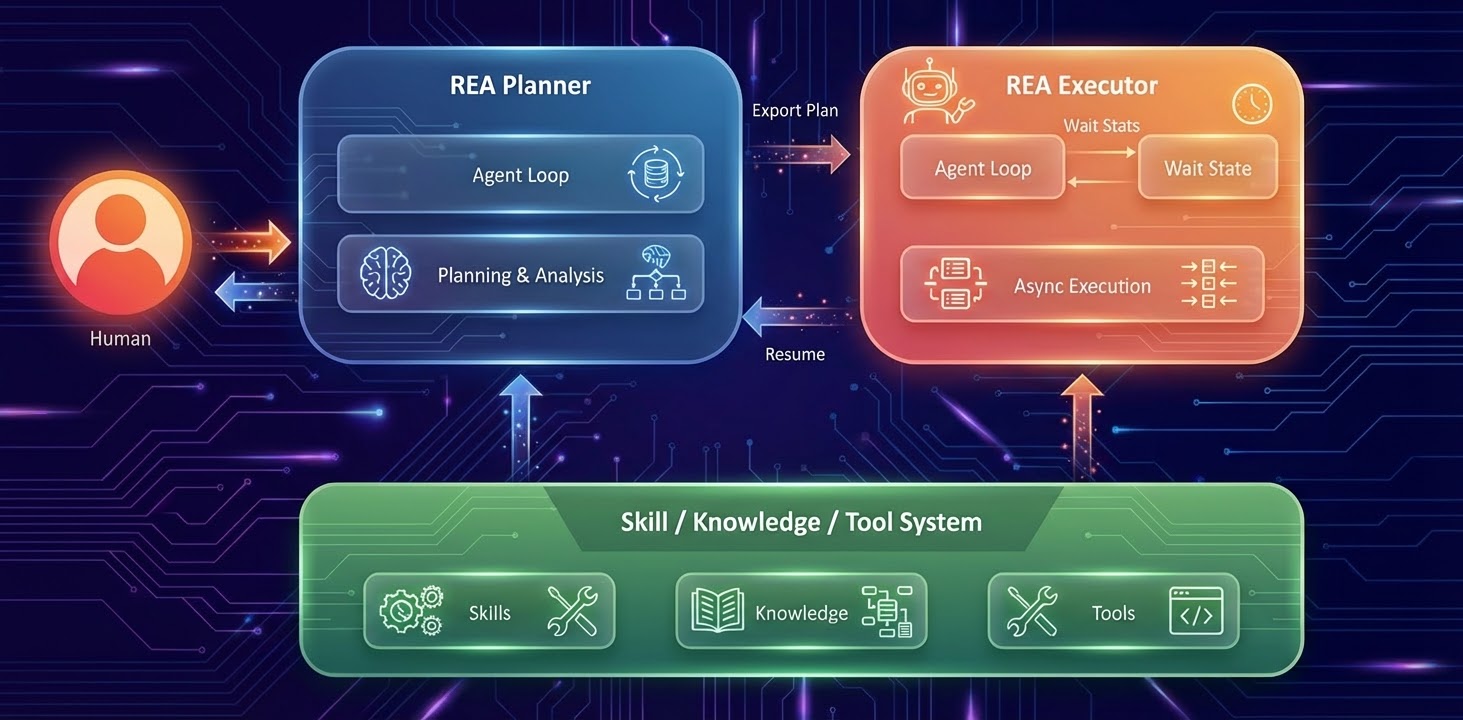
The Ranking Engineer agent is built on two interconnected components. REA planner and REA Executorsupported by Share A system of skills, knowledge and tools It provides ML capabilities, historical experiment data, and integration with Meta’s internal infrastructure. Together, they directly enable the agent’s three core capabilities:
long-term autonomy is powered by execution flow. Engineers work with hypothesis generators to create detailed experimental plans through REA Planner. The plan is exported to the REA Executor. REA Executor manages asynchronous job execution through agent loops and wait states. It enters a standby state while the training is running and resumes with the results when it completes. No continuous human monitoring is required over multi-week workflows.
High-quality and diverse hypothesis generation is driven by knowledge flows. Once a performer completes an experiment, a dedicated experiment logger logs results, key metrics, and configurations into a centralized hypothesis experiment insights database. This persistent memory stores knowledge spanning the entire history of the agent’s operations. Hypothesis generators use these insights to identify patterns, learn from previous successes and failures, and propose increasingly sophisticated hypotheses in each subsequent round, closing the loop and compounding the system’s intelligence over time.
Resilient execution persisted across both flows. When an executor encounters a failure, infrastructure error, out-of-memory signal, or training instability, it consults a runbook of common failure patterns and applies prioritization logic to autonomously adapt within predefined guardrails. Then restart the planner with actionable results rather than causing routine interruptions for engineers.
Impact: Model accuracy and engineering productivity
Twice the model accuracy compared to the baseline approach
In the first production validation across a set of six models, REA-driven iterations doubled the average model accuracy compared to the baseline approach. This directly translates into stronger outcomes for advertisers and a better experience on the Meta Platform.
5x more engineering productivity
REA amplifies the impact of ML experimentation by automating its mechanics, allowing engineers to focus on creative problem solving and strategic thinking. Complex architectural improvements that previously required multiple engineers and weeks can now be completed by small teams in days.
Early adopters using REA increased their model improvement suggestions from one to five in the same time period. What once required two engineers per model now requires three engineers across eight models.
The future of human-AI collaboration in ML engineering
REA represents a change in the way Meta approaches ML engineering. By building agents that can autonomously manage the entire experiment lifecycle, the team is changing the structure of ML development, moving engineers from hands-on experiment execution to strategic monitoring, hypothesis direction, and architectural decision-making.
This new paradigm, where humans make strategic decisions and final approvals while agents handle iterative mechanisms, is just the beginning. Privacy, security, and governance remain key priorities for agents. Meta continues to enhance REA’s capabilities by fine-tuning specialized models for hypothesis generation, expanding analytical tools, and expanding approaches into new areas.
Acknowledgment
Ashwin Kumar, Chaorong Chen, Deepak Chandra, Fan Yang, Hangjun Xu, Harpal Bassali, Jakob Moberg, Jags Somadder, Jingyi Guan, Jp Owed, Junhua Gu, Liquan Huang, Matt Steiner, Peter Chu, Qinjin Jia, Ritwik Tewari, Sandeep Pandey, Santanu Kolay, Shweta Memane, Vitor Cid, Wenlin Chen, Xiaoyu Deng, Xin Zhao, Zach Freeman, Zhaodong Wang, Zoe Zhu.

