


Reinforcement learning (RL) excels at tackling individual tasks but struggles with multitasking, especially across different robot morphologies. World models that simulate the environment offer scalable solutions but often rely on inefficient, high-variance optimization methods. Large-scale models trained on huge datasets can generalize highly in robotics, but they typically require near-expert data and cannot adapt to diverse morphologies. RL is promising for multitasking settings because it can learn from suboptimal data. However, methods such as world model zero-order programming face scalability issues and become less effective as model size grows, especially for large models such as GAIA-1 and UniSim.
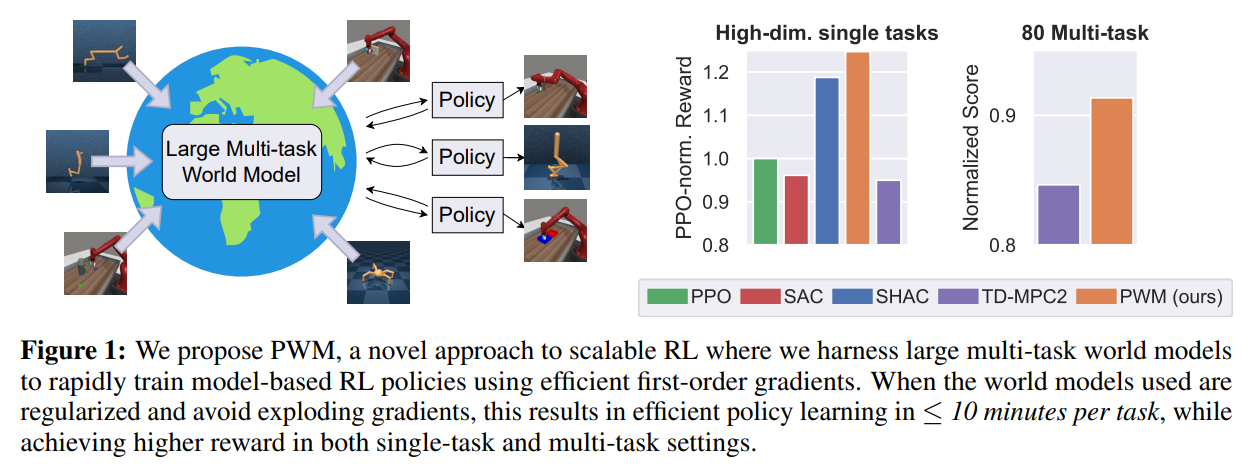
Researchers from Georgia Institute of Technology and University of California, San Diego present an innovative model-based reinforcement learning (MBRL) algorithm, Policy Learning with Large World Models (PWM). PWM pre-trains a world model on offline data and uses it for first-order gradient policy learning, allowing it to solve tasks with up to 152 action dimensions. The approach outperforms existing methods by achieving up to 27% higher rewards without costly online planning. PWM emphasizes the availability of smooth and stable gradients over time, rather than just accuracy. It demonstrates that efficient first-order optimization leads to better policies and faster training than traditional zero-order methods.

RL is divided into model-based and model-free approaches. Model-free methods such as PPO and SAC are mainstream in real-world applications and employ actor-critic architectures. SAC uses first-order gradients (FoG) for policy learning, which has low variance but faces problems with objective discontinuities. Conversely, PPO relies on zero-order gradients, which are robust to discontinuities but tend to have high variance and slow optimization. Recently, the focus in robotics has shifted to large multitask models trained by behavior cloning. Examples include RT-1 and RT-2 for object manipulation. However, the potential of large models in RL has yet to be explored. MBRL methods such as DreamerV3 and TD-MPC2 leverage large-world models, but their scalability may improve as the size of models increases, especially for GAIA-1 and UniSim.
This work focuses on discrete-time, infinite-time RL scenarios represented by Markov decision processes (MDPs) that contain states, actions, dynamics, and rewards. RL aims to maximize the cumulative discounted reward through a policy. Typically, this is addressed using an actor-critic architecture that approximates state values and optimizes the policy. In MBRL, additional components such as learned dynamics and reward models (often called world models) are used. These models can encode the true state into a latent representation. Leveraging these world models, PWM efficiently optimizes policies using FoG, reducing variance and improving sample efficiency even in complex environments.
In evaluating the proposed method, we used the Flex Simulator to tackle complex environmentally focused control tasks including hopper, ant, animal, humanoid, and muscle-driven humanoid. Comparisons were made with SHAC, which uses a ground truth model, and TD-MPC2, a model-free method that actively plans during inference. Results showed that PWM achieved higher rewards and smoother optimization landscapes than SHAC and TD-MPC2. Further tests on 30 and 80 multitask environments showed that PWM achieved better reward performance and faster inference times than TD-MPC2. Ablation studies highlighted the robustness of PWM against stiff contact models and high sample efficiency, especially when using a well-trained world model.
In this study, we introduced PWM as an approach for MBRL. PWM utilizes a large multitask world model as a differentiable physics simulator and leverages first-order gradients for efficient policy training. Evaluation highlighted PWM's ability to outperform existing methods, including those with access to ground truth simulation models such as TD-MPC2. Despite its strengths, PWM relies heavily on extensive existing data to train the world model, limiting its applicability in data-sparse scenarios. Furthermore, while PWM provides efficient policy training, it requires retraining for each new task, making rapid adaptation a challenge. Future work may explore enhancements to world model training and extend PWM to image-based environments and real-world applications.
Please check Papers and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 46k+ ML Subreddit


Sana Hassan, a Consulting Intern at Marktechpost and a dual degree student at Indian Institute of Technology Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, she brings a fresh perspective to the intersection of AI and real-world solutions.


