
How can you build an AI system that continues to learn new information over time without forgetting what it previously learned or having to retrain from scratch? Google researchers introduced nested learning, a machine learning approach that treats a model as a collection of smaller nested optimization problems instead of a single network trained by one outer loop. The goal is to attack catastrophic forgetting and move large-scale models toward continuous learning, closer to how the biological brain manages memory and adaptation over time.

What is nested learning??
Google research paper “Nested learning, the illusion of deep learning architecture” Model complex neural networks as a set of nested or coherent optimization problems that are optimized together or run in parallel. Each internal problem has its own context flow, its own sequence of inputs, gradients, or states that this component observes, and its own update frequency.
Rather than thinking of training as a flat stack of layers and a single optimizer, nested learning imposes an ordering by update frequency. Parameters that are updated are often at the internal level, while parameters that are updated slowly form the external level. This hierarchy defines neural learning modules, with each level compressing its own context flow into parameters. The researchers show that this view covers standard backpropagation on MLP, linear attention, and general optimizers, all as instances of associative memory.
In this framework, associative memories are operators that map keys to values, and are trained for internal purposes. The researchers formalized associative memory and showed that backpropagation itself can be described as a one-step gradient descent update that learns the mapping from input to local surprise signals, the gradient of the loss on the output.
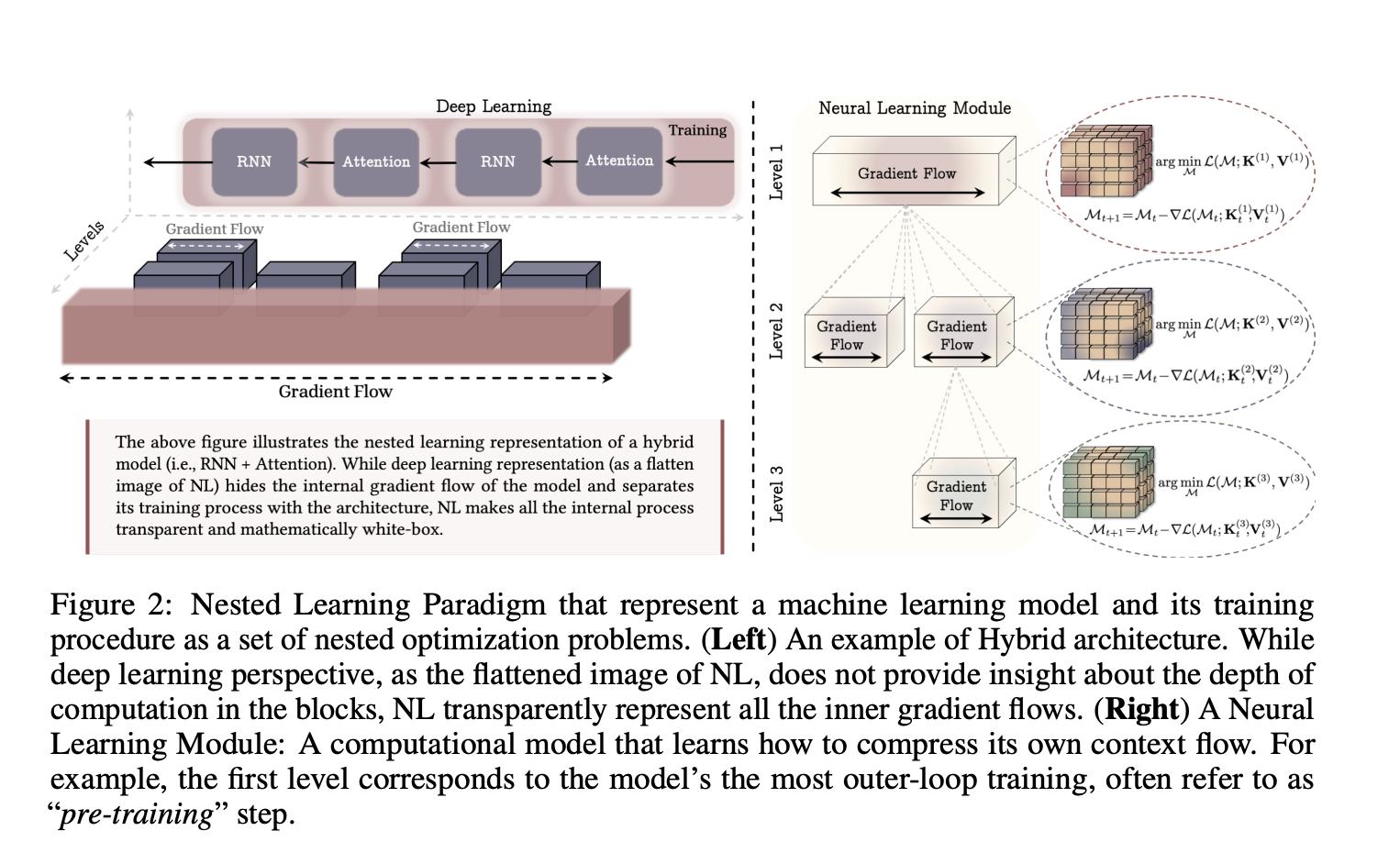
Deep optimizer as associative memory
When you treat the optimizer as a learning module, Nested Learning suggests redesigning the optimizer with richer internal goals. Standard momentum can be written as a linear associative memory over past gradients, trained using a dot product similarity objective. This internal goal generates Hevian-like update rules that do not model dependencies between data samples.
The team of researchers replaced this similarity objective with an L2 regression loss on gradient features. This results in update rules that better manage limited memory capacity and better remember gradient sequences. We then generalize momentum memory from linear maps to MLPs and define a deep momentum gradient descent method where momentum states are generated by neural memory and can pass through nonlinear functions such as Newton-Schulz. From this point of view, the Muon optimizer is also recovered as a special case.

continuous storage system
In the general sequence model, attention acts as working memory on the current context window, whereas feedforward blocks store pre-training knowledge as long-term memory that is rarely updated after training. Nested learning researchers extend this binary view to continuous memory systems (CMS).
A CMS is defined as a chain of MLP blocks from MLP(f₁) to MLP(fₖ), with each block having its own update frequency and chunk size. Given an input sequence, applying these blocks sequentially yields the output. Each block’s parameters are only updated every C^(ℓ) steps, so each block compresses a different time scale of context into its parameters. The standard Transformer with one feedforward block is recovered as a special case with k equal to 1.
This structure turns long-term memory into a spectrum of levels across frequencies rather than a single static feedforward layer. This study directly links this to multi-timescale synaptic and system integration processes in the brain, where different parts of the system share a common architecture but learn at different rates.
HOPE, a self-modifying architecture built on Titans
To demonstrate the practicality of nested learning, the research team designed HOPE, a self-referential sequence model that applies the paradigm to recursive architectures. HOPE is built as a variant of Titans, a long-term memory architecture where neural memory modules learn to remember surprising events during testing and help focus attention on tokens from the distant past.
Titans has only two levels of parameter updates, the first order being generated by context learning. HOPE extends Titans in two ways. First, it is self-correcting, capable of optimizing its own memory through self-referential processes, and can in principle support unlimited levels of contextual learning. Second, integrating the Continuum Memory System block allows memory updates to occur at multiple frequencies and scale to longer context windows.
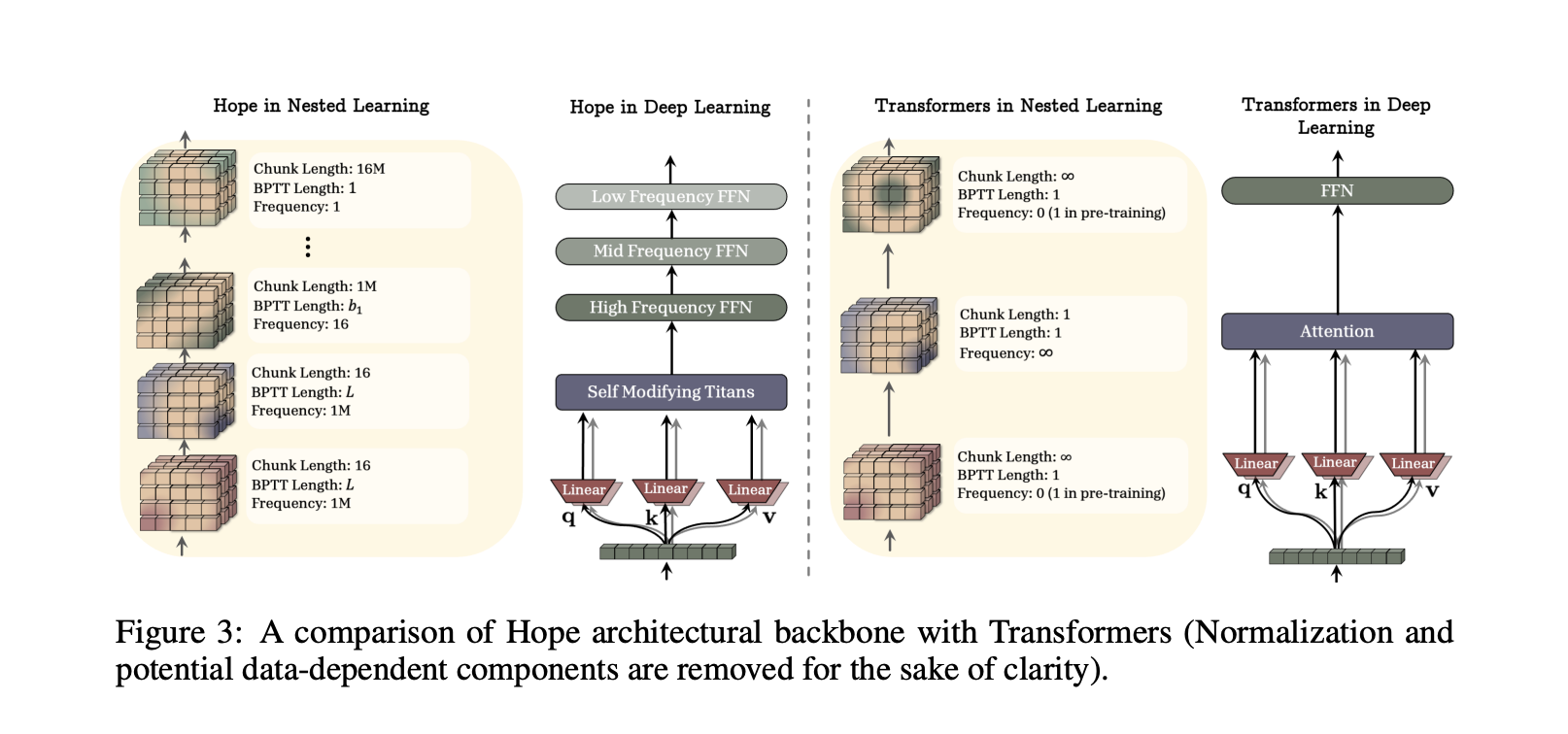
understand the results
The research team evaluates HOPE and baseline for language modeling and common sense reasoning tasks on three parameter scales (340M, 760M, and 1.3B parameters). Benchmarks include Wiki and LMB complexity for language modeling, and PIQA, HellaSwag, WinoGrande, ARC Easy, ARC Challenge, Social IQa, and BoolQ accuracy for inference. Table 1 below shows the results for HOPE, Transformer++, RetNet, Gated DeltaNet, TTT, Samba, and Titans.
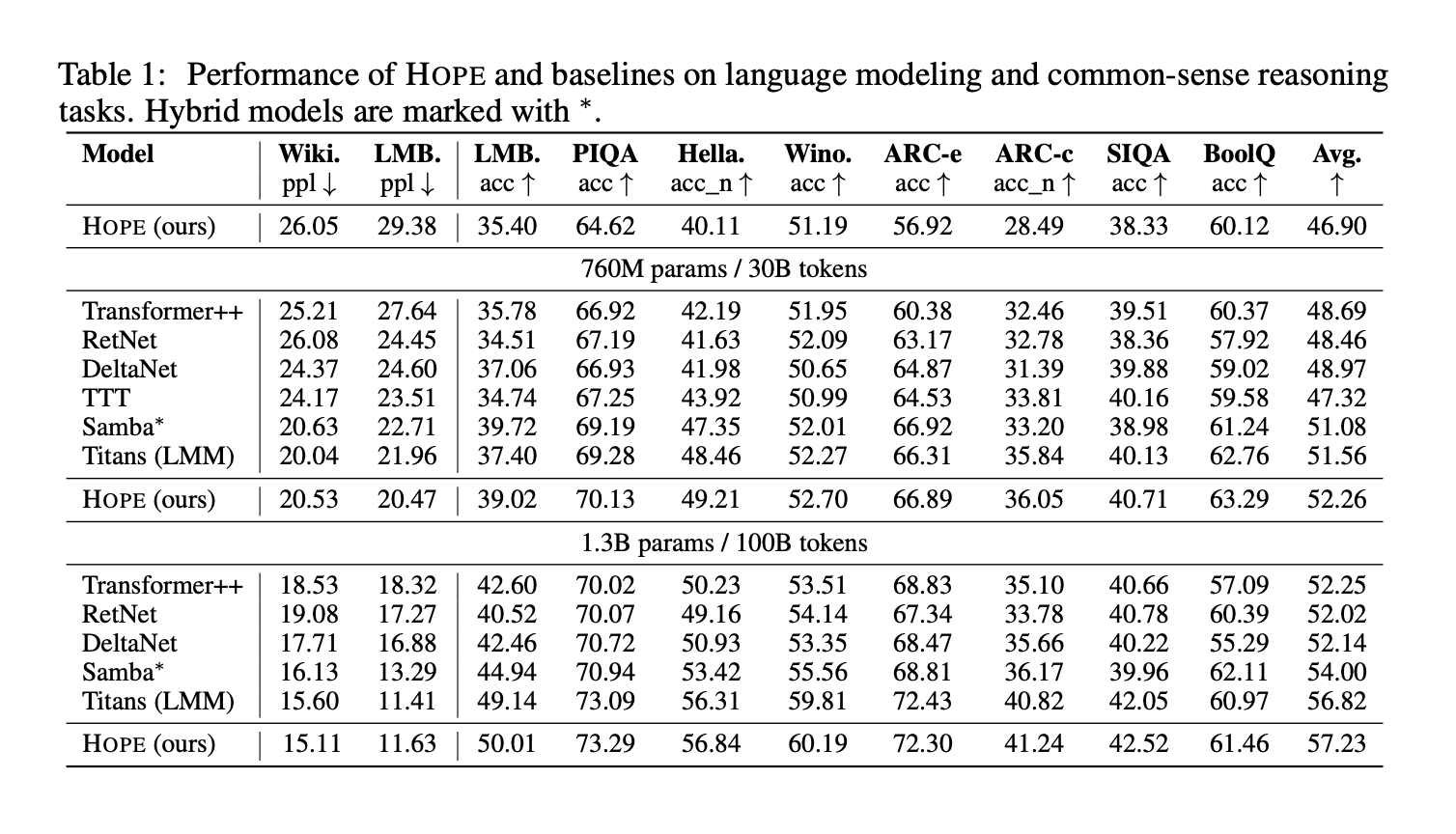
Important points
- Nested learning directly targets catastrophic forgetting in continuous learning by treating the model as multiple nested optimization problems with different update frequencies.
- This framework reinterprets backpropagation, attention, and optimizers as associative memory modules that compress their own context flows, providing a unified view of architecture and optimization.
- Nested learning deep optimizers replace simple dot product similarity with richer objectives such as L2 regression and use neural memory. This allows for more expressive and context-aware update rules.
- The Continuum Memory System models memory as a spectrum of MLP blocks that are updated at different rates, creating memory with short, medium, and long range ranges rather than one static feedforward layer.
- The HOPE architecture is a self-modifying variant of Titans built using nested learning principles and provides improved language modeling, long context inference, and continuous learning performance compared to powerful Transformer and recurrent baselines.
Nested learning is a useful reconfiguration of deep networks as neural learning modules that integrate architecture and optimization into one system. The introduction of deep momentum gradient descent, sequential memory systems, and the HOPE architecture provides a concrete path to richer associative memory and better continuous learning. Overall, this work turns retrofit continuous learning into a primary design axis.
Please check paper and technical details. Please feel free to check it out GitHub page for tutorials, code, and notebooks. Please feel free to follow us too Twitter Don’t forget to join us 100,000+ ML subreddits and subscribe our newsletter. hang on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His latest endeavor is the launch of Marktechpost, an artificial intelligence media platform. It stands out for its thorough coverage of machine learning and deep learning news, which is technically sound and easily understood by a wide audience. The platform boasts over 2 million views per month, which shows its popularity among viewers.
🙌 Follow MARKTECHPOST: Add us as your preferred source on Google.


