
It’s becoming something of a theme that machine-generated content, whether it’s code, text, or graphics, continues to push people to their limits. The main reason for this is that such “AI slop” is generally of prohibitively low quality. [Vincent Driessen] There is clearly a copyright infringement aspect involved as well. He recently discovered that Microsoft had made the Git instructional graphic he painstakingly handcrafted in 2010 so bad that someone at Microsoft had slapped it on a Microsoft Learn instructional article about GitHub.
As stated in pc gamer After the article about this apparent error, Microsoft quietly removed the graphic and replaced it with something potentially less AI-influenced, but there was no comment, and so far there have been no responses to requests for comment. pc gamer. Of course, the Internet Archive always remembers.
Perhaps most frustratingly, this rip-off isn’t even particularly good. It has all the hallmarks of AI slop graphics, from pointless arrows that are added or changed to heavily disconnected text, such as “Time” changed to “Tim” and “continuously combined” to “continuously combined.” This makes it clear that whoever placed the graphic on the Microsoft Learn page didn’t bother to check it, or that there were no humans involved in the creation of the page.
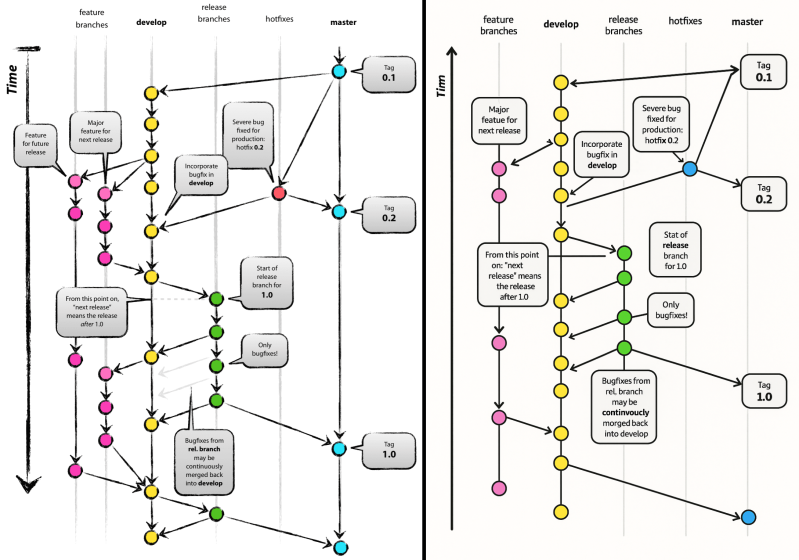
It definitely gives a dystopian “dead internet” feel, with the fruits of past labor cynically regurgitated and spat out in the form of AI slop that bears little resemblance to the original, making any living human beings flee in abject terror or collapse with uncontrollable laughter.
Even if this output were the result of: [Vincent]’s original graphic is scuffed, shoved, and squirming and screaming into the diffusion model’s training dataset, but there’s a lot of junk to indicate that it’s based on this original, from the text blurb to the use of the label “feature branch” that’s retained on the duplicate even though the second feature branch has been cropped.
All of this raises a number of uncomfortable questions about copyright, both in the context of large-scale language models and dissemination models, where it becomes clear that important elements of copyrighted works can sometimes be reproduced almost verbatim. Depending on the copyright licenses involved, this can lead to very expensive copyright infringement lawsuits, some of which have already been litigated or are being litigated through various courts primarily related to stock images and books.
And what Microsoft had to do here was [Vincent] If you want to use a graphic, please license it. as [Vincent] It shows that he would have been happy to do so if a backlink and credit were provided. This is clearly a human practice, where humans contact fellow humans to ask their thoughts on a topic, or peruse their fellow humans’ work to find something they like before asking about usage.
In this age of “just asking the machine” by mashing queries into prompts, this particular case seems far from the last. The irony here is that the value of human output is being reduced to mere training data for a content machine, but perhaps Microsoft will surprise us here with a tearful apology and real action to prevent such an event from happening again.


