


Automatic audio captioning (AAC) is an innovative field that converts audio streams into descriptive natural language text. The creation of AAC systems relies on the availability of vast amounts of accurately annotated audio-text data. However, traditional methods of manually combining audio segments and text captions are not only costly and labor-intensive, but also prone to inconsistencies and biases, limiting the scalability of AAC technology.
Existing research on AAC includes encoder-decoder architectures that utilize audio encoders such as PANN, AST, and HTSAT to extract audio features. These features are interpreted by language generation components such as BART and GPT-2. The CLAP model takes this forward by using contrastive learning to align audio and text data within a multimodal embedding. Techniques such as adversarial training and contrast loss improve his AAC system to increase caption diversity and accuracy while addressing vocabulary limitations inherent in previous models.

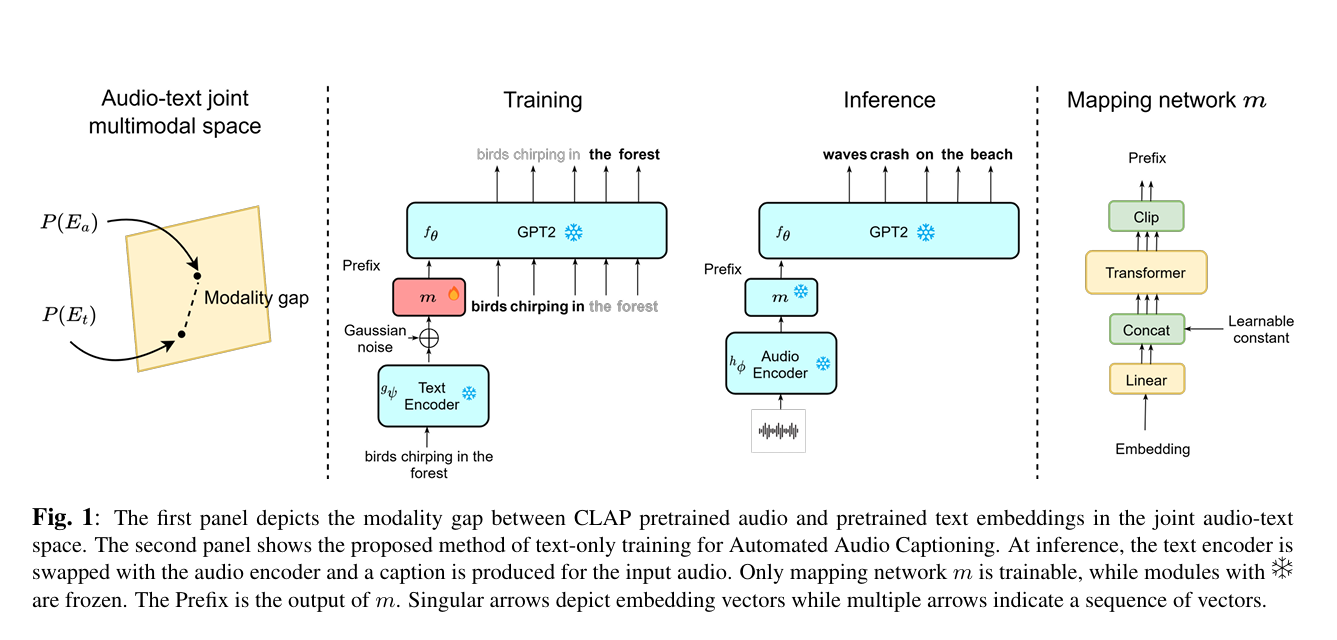
Researchers from Microsoft and Carnegie Mellon University have proposed an innovative text-only training method for AAC systems using the CLAP model. This new approach fundamentally changes the traditional AAC training process by utilizing only text data, avoiding the need for audio data during training. This represents a major change in AAC technology as it allows the system to generate audio captions without having to learn directly from audio input.
The researchers adopted the CLAP framework and trained only the AAC system using text data as their methodology. During training, captions are generated by the decoder conditional on embeddings from the CLAP text encoder. During inference, the text encoder is replaced by a CLAP audio encoder to adapt the system to the actual audio input. The model is evaluated on two of his prominent datasets, AudioCaps and Clotho, and combines Gaussian noise injection with a lightweight learnable adapter to effectively bridge the modality gap between text and audio embeddings, making the system ensures that performance remains robust.


Evaluation of the text-only AAC method demonstrated robust results. Specifically, the model achieved SPIDer scores of 0.456 on the AudioCaps dataset and 0.255 on the Clotho dataset, showing competitive performance with state-of-the-art His AAC systems trained on paired audio-text data. Ta. Additionally, using Gaussian noise injection and learnable adapters, the model effectively bridged the modality gap. This is evidenced by the fact that the variance of the embeddings was minimized to approximately 0.015. These quantitative results validate the effectiveness of the proposed text-only training approach in generating accurate and relevant audio captions.
In conclusion, this study demonstrates a text-only training method for AAC using the CLAP model that eliminates reliance on audio-text pairs. This methodology leverages text data to train his AAC system and is demonstrated by achieving competitive SPIDer scores on AudioCaps and Clotho datasets. This approach simplifies AAC system development, enhances scalability, and reduces reliance on costly data annotation processes. These innovations in AAC training greatly expand the application and accessibility of audio captioning technology.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits
Want to get in front of an AI audience of 1.5 million people? work with us here


Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated double degree in materials from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast and is constantly researching applications in areas such as biomaterials and biomedicine. With a strong background in materials science, he explores new advances and creates opportunities to contribute.

