


The introduction of audio descriptions (AD) is a big step toward making video content more accessible. AD provides audio narrative for important visual elements in the video that are not available in the original video track. However, creating accurate AD requires many resources, including special expertise, equipment, and significant time investment. Automating AD production also improves video accessibility for people with visual impairments. Still, a major challenge in automating AD is generating appropriately sized sentences that fit the various temporal gaps within an actor's interaction.
Recently, large-scale multimodal models (LMMs) have become popular in artificial intelligence, mainly focusing on integrating various data types such as text, images, audio, and video to make them more reliable and intelligent. It is placed. For example, GPT-4V is his LLM model that extends the large-scale language model GPT-4 with visual possibilities. Additionally, a method called MM-VID pioneered the use of his GPT-4V model for AD generation utilizing a two-step method. This process includes compositing compressed frame captions and adjusting the final AD output using GPT-4. Unfortunately, these methods do not have an explicit process for character recognition.
The team at Microsoft introduced an automated pipeline that leverages GPT-4V(ision) to generate accurate AD for video. This method uses movie clips and their title information to generate AD content, and leverages the multimodal capabilities of GPT-4V by integrating visual signals from video frames with text context. Masu. This method helps you size your AD to match audio gaps and adapt it to different types of videos by filling out AD production guidelines that indicate sentence length in a simple and natural way.
The proposed method is tested using the MAD dataset, which contains a rich collection of over 264,000 audio descriptions from 488 movies. During the development of this method to generate person tracklets, a simplified version of the multi-person tracker is utilized to capture all the characters that appear in the input movie his clips. Further processes utilize TransNetV2 to detect and segment clips containing multiple shots, and after tracklet generation, square patches are extracted around each person from the frame. Within the face patch, face detection is performed using the YOLOv7 model, which facilitates cropping and alignment of the face patch to a standard size of 112 × 112 pixels.
GPT-4V was instructed to generate all ADs with word counts such as 6, 10, and 20 words, along with performance results. In the AudioVault dataset, 80% of ADs contain 10 words or less, 99% of ADs have a limit of 20 words, and the selection of 6 words matches the average word count of the dataset. Results show that 10-word prompts have the highest ROUGE-L and CIDEr scores compared to fixed word counts of 6, 10, and 20. The proposed method outperformed AutoAD-II and established a new state-of-the-art method. CIDEr and ROUGE-L scores were 20.5 (vs. 19.5) and 13.5 (vs. 13.4), respectively.

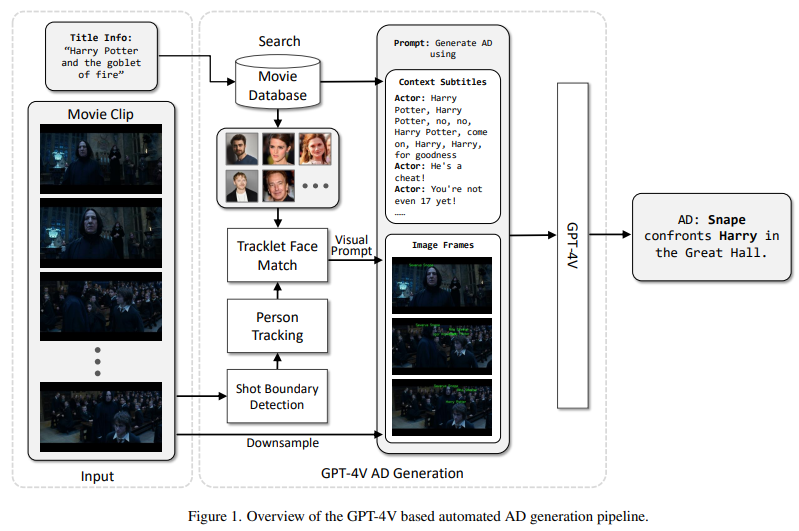
In conclusion, the Microsoft team proposed an automated pipeline that leverages GPT-4V(ision) to generate accurate video AD. This method outperformed various methods in this paper, such as AutoAD-II, with a CIDEr score of 20.5 (vs. 19.5) and a ROUGE-L score of 13.5 (vs. 13.4). However, the proposed method lacks a mechanism to determine the appropriate moment to insert an AD in a movie and estimate the number of words associated with that AD. Therefore, in the future, it is necessary to improve the quality of the generated AD. For example, you can customize a lightweight language rewriting model using available AD data to enhance the output from LLM.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland LinkedIn groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 41,000+ ML subreddits


Sajjad Ansari is a final year undergraduate student at IIT Kharagpur. As a technology enthusiast, he focuses on understanding the impact of his AI technology and its impact on the real world, delving into practical applications of AI. He aims to explain complex AI concepts in a clear and accessible way.


