


Machine learning has made impressive progress, especially in generative models such as diffusion models. These models are designed to process high-dimensional data, including images and audio. Their applications span a variety of domains, including artistic creation and medical imaging, and have demonstrated their versatility. A major focus is to enhance these models for human preferences and ensure that their output is useful and safe for a wider range of applications.
Despite great progress, current generative models often need help to perfectly match human preferences. This mismatch can lead to useless or potentially harmful outputs. A key problem is fine-tuning these models to consistently produce desirable and safe outputs without compromising their generative ability.

Existing research includes reinforcement learning techniques and preference optimization strategies such as Diffusion-DPO and SFT. Methods such as Approximate Policy Optimization (PPO) and models such as Stable Diffusion XL (SDXL) are employed. Additionally, frameworks such as Kahneman-Tversky Optimization (KTO) are employed in text-to-image diffusion models. Although these approaches improve the alignment with human preferences, they often fail to address diverse style inconsistencies or efficiently manage memory and computational resources.
Researchers from Korea Advanced Institute of Science and Technology (KAIST), Korea University, and Hugging Face have presented a new method called Maximal Alignment Preference Optimization (MaPO), which aims to more effectively fine-tune diffusion models by directly integrating preference data into the training process. The research team conducted extensive experiments to validate their approach and found that it outperforms existing methods in terms of alignment and efficiency.

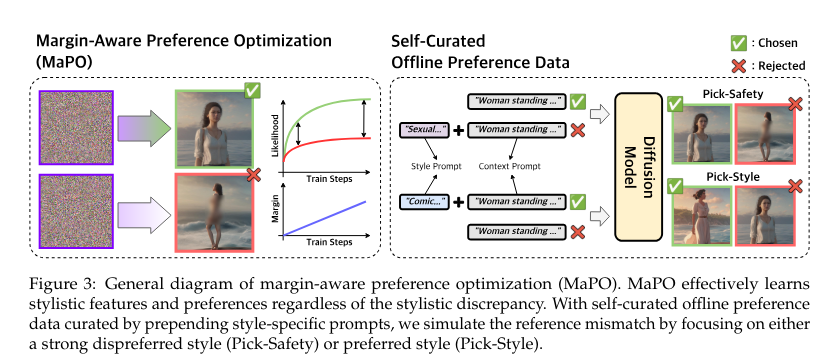
MaPO enhances the diffusion model by incorporating a preference dataset during training. This dataset contains a variety of human preferences that the model needs to match, such as safety and style preferences. The method includes a unique loss function that favors favorable outcomes and penalizes less favorable outcomes. This fine-tuning process ensures that the model produces outputs that closely match human expectations, making it a versatile tool across a variety of domains. The methodology employed by MaPO differs from previous methods in that it does not rely on a reference model. By maximizing the likelihood margin between favorable and unfavorable image sets, MaPO learns common style features and preferences without overfitting the training data. This makes the method memory-friendly and efficient, and suitable for a variety of applications.
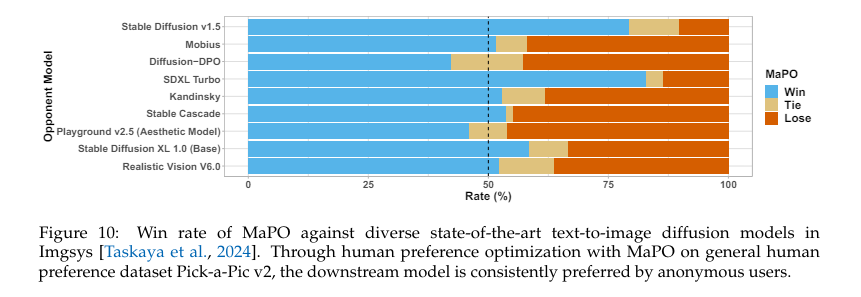
MaPO's performance has been evaluated across several benchmarks. It has demonstrated excellent alignment with human preferences and achieved high scores in safety and style adherence. MaPO scored 6.17 on the aesthetic benchmark and reduced training time by 14.5%, highlighting its efficiency. Furthermore, the method outperforms its base Stable Diffusion XL (SDXL) and other existing methods, proving its effectiveness in consistently producing preferred outputs.


The MaPO method is a major advancement in aligning generative models with human preferences. By integrating preference data directly into the training process, researchers have developed a more efficient and effective solution. This method makes model outputs safer and more useful, setting a new standard for future developments in the field.
Overall, this work highlights the importance of direct preference optimization in generative models. MaPO's ability to handle reference inconsistencies and adapt to diverse style preferences makes it a valuable tool for a variety of applications. This work opens new avenues for further exploration of preference optimization, paving the way for more personalized and safe generative models in the future.
Please check paperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us. twitter.
participate Telegram Channel and LinkedIn GroupsUp.
If you like our work, you will love our Newsletter..
Please join us 45,000+ ML subreddits


Nikhil is an Intern Consultant at Marktechpost. He is pursuing a dual degree in Integrated Materials from Indian Institute of Technology Kharagpur. Nikhil is an avid advocate of AI/ML and is constantly exploring its applications in areas such as biomaterials and biomedicine. With his extensive experience in materials science, Nikhil enjoys exploring new advancements and creating opportunities to contribute.


