
Machine learning models are powerful tools that help companies make more informed decisions and optimize operations. However, as these models are deployed and run in production, they can experience a phenomenon known as model drift.
Model drift occurs when machine learning model performance degrades over time due to changes in the underlying data, resulting in inaccurate predictions, which can have serious consequences for your business. To meet this challenge, the organization is turning to his MLOps. MLOps are a set of practices and tools that help manage the machine learning lifecycle in production.
This article describes model drift, its different types, methods of detection, and most importantly, how to use MLOps to handle model drift in production. By understanding and managing model drift, businesses can ensure their machine learning models are accurate and effective over time, delivering the insights and results they need to thrive.

Photo by Nicolas Peyrol on Unsplash
Model drift, also known as model decay, is a machine learning phenomenon in which model performance degrades over time. This means that the model will start making worse predictions over time and become less accurate over time.
There are many reasons for model shifts, including changes in data collection and underlying relationships between variables. So the model can’t catch these changes and performance degrades as the number of changes increases.
Detecting and addressing model drift is one of the key tasks that MLOps solves. Detect the presence of model drift using techniques such as model monitoring. Model retraining is one of the main techniques used to overcome model drift.
Understanding the types of model drift is essential to updating the model based on changes that occur in the data. There are three main types of drift.
concept drift
Concept drift occurs when the relationship between targets and inputs changes. Therefore, machine learning algorithms do not provide accurate predictions. There are four main types of concept drift.
- sudden drift: Sudden conceptual drift occurs when the relationship between the independent and dependent variables occurs suddenly. A very famous example is the sudden outbreak of the covid 19 pandemic. The outbreak of the pandemic abruptly changed the relationship between the target variables and the features of various domains, so that the predictive model trained on the pre-trained data will not be able to accurately predict the timing of the pandemic.
- gentle drift: In gradual conceptual drift, the relationship between inputs and targets may change slowly and subtly. This can slowly degrade the performance of your machine learning model as the accuracy of the model degrades over time. An example of gradual concept drift is cheating. Fraudsters understand how fraud detection systems work and tend to change their behavior over time to evade them. Therefore, machine learning models trained on historical fraudulent transaction data cannot accurately predict gradual changes in fraudster behavior. For example, consider a machine learning model used for stock price prediction where the model is trained on data from the last five years and its performance is evaluated on new data for the current year. However, over time, market dynamics can change, gradually changing the relationships between variables that affect stock prices. This can lead to gradual drift, which reduces the effectiveness of capturing changing relationships between variables, so the accuracy of the model gradually decreases over time.
- Incremental drift: Incremental drift occurs when the relationship between the target variable and the input changes gradually over time. This is usually caused by changes in the data generation process.
- repeated drift: This is also called seasonality. A classic example is increased sales on Christmas and Black Friday. Machine learning models that incorrectly do not account for these seasonal changes will provide incorrect predictions of these seasonal changes.
These four types of concept drift are shown in the figure below.
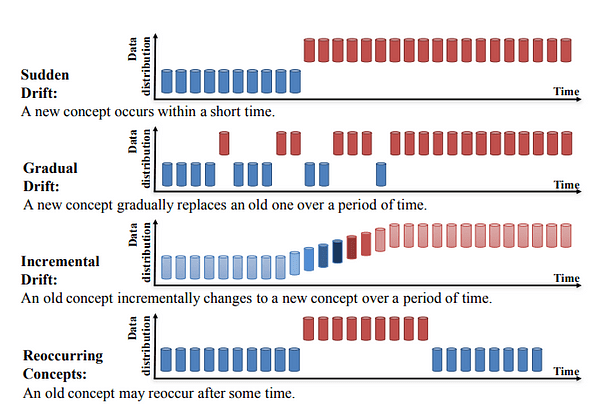
Types of Concept Drift | Image of Learning Under Concept Drift: Review.
data drift
Data drift occurs when the statistical properties of the input data change. An example of this is the age distribution of users for a particular application over time. Therefore, models trained on specific age distributions used for marketing strategies should be modified as age changes have an impact. marketing strategy.
Modifying upstream data
A third type of drift is changes in upstream data. This refers to operational data changes in the data pipeline. A typical example of this is when certain features are no longer generated and have missing values. Another example is changing units of measure. For example, if a particular sensor measures quantity in Celsius and then changes to Fahrenheit.
Detecting model drift is not easy and there is no universal way to detect it. However, we will discuss some of the common methods for detecting it.
- Kolmogorov-Smirnov test (KS test): The KS test is a nonparametric test for detecting changes in data distribution. It is used to compare training and post-training data and find changes in distribution between them. The null hypothesis for this test set indicates that the distributions from the two datasets are the same, so if the null hypothesis is rejected, a model shift occurs.
- Population Stability Index (PSI): PSI is a statistical measure used to measure the similarity of distributions of categorical variables in two different data sets. Therefore, it can be used to measure changes in the characteristics of categorical variables in training and post-training datasets.
- page-hinckley method: Page-Hinkely is also a statistical technique used to observe changes in the mean of data over time. It is typically used to detect small changes in mean values that are not apparent when looking at the data.
- Performance monitoring: One of the most important ways to detect conceptual changes is to monitor the performance of machine learning models in production and observe their changes. If it crosses a certain threshold, certain actions can be triggered to correct this concept change.

Handling Drift in Production | Image by ijeab on Freepik.
Finally, let’s see how to handle detected model drift in production. There are different strategies used to handle model drift, depending on the type of drift, the data you are working with, and the project in production. Here is an overview of common methods used to handle model drift in production.
- online learning: Online learning is one of the popular methods used to deal with drift, since most real-world applications run on streaming data. With online learning, the model processes one sample at a time, so the model updates on-the-fly.
- Retrain the model periodically. You can set triggers to retrain the model on recent data when the model’s performance drops below a certain threshold or when data shifts are observed.
- Retrain periodically on representative subsamples: A more effective way to handle concept drift is to select a representative subsample of the population, label them using a human expert, and retrain the model on them.
- Removed features: This is a simple but effective method you can use to handle concept drift. Using this method, we train multiple models with one feature each and monitor her AUC-ROC response for each model. If the AUC-ROC value exceeds a certain threshold using a certain feature, you can drop it as follows: This can participate in drift.
References
In this article, we discussed model drift. This is a machine learning phenomenon where model performance degrades over time due to changes in the underlying data. To overcome these challenges, companies are turning to MLOps, a set of practices and tools that manage the lifecycle of machine learning models in production.
Detect different types of drift that can occur, such as concept drift, data drift, changes in upstream data, and model drift using methods such as the Kolmogorov-Smirnov test, population stability index, and Page-Hinkley method I outlined how. Finally, we discussed common techniques for handling model drift in production, including online learning, periodic model retraining, periodic retraining on representative subsamples, and feature removal. bottom.
Youssef Rafat Computer vision researcher and data scientist. His research focuses on the development of real-time his computer vision his algorithms for healthcare applications. He also worked as a data scientist for over 3 years in marketing, finance and healthcare.


