In this study, we investigated the predictive performance of five models and the predictive contribution of 196 features across four categories, based on the hypothesis that machine learning models with comprehensive feature sets are beneficial for PA subtype prediction. Decision tree models (RF, GBDT) and deep learning models (MLP) outperformed regression models (LR, SVM), with RF showing the best performance. Category B (challenge testing and circadian hormone sampling) was the category that contributed the most to predicting PA subtypes in the RF model, whereas category C (general biochemistry) was found to lack predictive value and could negatively impact model performance. Category D (steroid profile) played an important role in the MLP model. Although the contribution of individual features varies by model, CCT90-PAC was a useful feature in RF. The academic significance of this study lies in (1) the evaluation of the predictive performance of multiple machine learning models, (2) the collection of a comprehensive set of 196 clinical features to explore unknown predictive features, and (3) the systematic classification of features to understand the predictive contributions at the category and subcategory levels.
To our knowledge, this is the first study to evaluate a machine learning model using an extensive feature set including categories B, C, and D. It has general PA-related functions (Category A). Previous studies have built models to distinguish between PA subtypes, with reported sensitivities of 32–95% and specificities of 46–100%.24, 25, 26, 27, 28, 29including studies using machine learning-based prediction of PA subtypes.30,31. Kaneko et al. applied four machine learning methods (LR, SVM, RF, and GBDT) to 229 PA cases, using 80% for training and 20% for testing. reported that RF achieved the best prediction performance (ROC-AUC 0.990, accuracy 95.7%). When it comes to predictive features, the usefulness of CCT and SIT has been documented.32. Eisenhofer et al. reported a model using urinary steroid profiles. This model achieved 100% sensitivity and 98% specificity for the diagnosis of uPA with KCNJ5 variants, while the ROC-AUC for wild-type patients was 0.716.19.
This study initially aimed to explore features useful in predicting PA subtypes through a comprehensive feature collection approach. Machine learning-based models were introduced because they can effectively handle a wide range of feature sets. The primary objective of this study was not to maximize prediction accuracy, but to systematically evaluate the relative utility of a wide range of clinical features and predefined feature categories for predicting subtypes of primary hyperaldosteronism using multiple machine learning-based models. To address multicollinearity resulting from a large number of features, we organized potentially overlapping features into categories and subcategories and assessed the relative contribution of each category. Machine learning models were trained using the complete feature set unless otherwise stated. Feature categories were introduced not to reduce multicollinearity during model training, but to support post-interpretation by evaluating contributions at the category and subcategory level. As a result, correlated features were retained in the model.
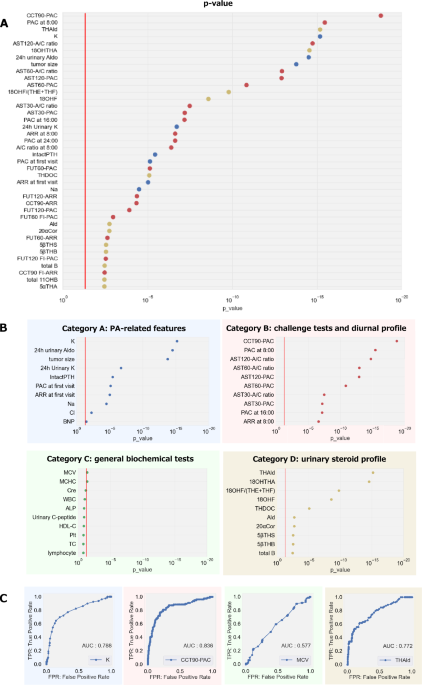
Category A features, including tumor size, K, PAC, and ARR, have traditionally been identified as essential for subtyping.33,34,35,36,37,38This is because uPA is usually more severe than bPA, with higher PAC and lower serum K.39, 40, 41. These findings highlight the importance of category A features in subtype prediction. Among other biochemical markers, Na, Ca, intact PTH, and BNP also reflect the influence of aldosterone on electrolyte or circulating volume balance and contribute to subtype prediction in the RF model, which is consistent with previous reports.
In category B, we evaluated CCT, AST, and FUT. However, SIT was not routinely performed at our institution and therefore was not included. In this study, CCT and AST emerged as major predictors. This is consistent with previously reported results regarding subtype prediction.42,43. In particular, CCT90-PAC contributes the most in the RF model and outperforms all Category A features. The superiority of CCT90-PAC over baseline PAC is consistent with the well-known fact that PAC is often poorly suppressed by captopril in APA patients. For CCT, absolute PAC values were more predictive than ARR or PAC doubling. Additionally, the AST120 A/C ratio ranked higher than AST120-PAC.
Category C included common clinical parameters such as liver and kidney function, blood cell counts, and markers of glucose and lipid metabolism, excluding electrolytes in category A. Features in category C had limited predictive utility in the RF model, and adding them to category A degraded performance. This indicates that category C introduced noise and attenuated the contribution of category A to the prediction. However, lowering of cholesterol and triglycerides in uPA has been reported.44only urinary C-peptide emerged as a notable contributing factor in the current RF model. Subcategory analysis showed minimal added value from blood cell counts, liver function, and metabolic markers.
Category D includes urinary steroid profiles of hospitalized patients. Previous reports have reported that hybrid steroids with both glucocorticoid-like and mineralocorticoid-like structures (17α-hydroxyl and 18-hydroxyl or oxo groups, 18OHF, etc.) may associate with uPA and contribute to subtype classification.45,46,47,48,49. In this study, 18OHTHA, a urinary metabolite of aldosterone biosynthetic intermediates, was the most contributing category D feature in the RF model, exceeding other metabolites such as urinary aldosterone and 18OHF. Elevated 18OHTHA may indicate increased CYP11B2 (aldosterone synthase) activity in the adrenal cortex. In addition to individual metabolites, we also included sums and ratios of metabolites that reflect enzyme activity. Among these ratios, the 18OHF/(THE + THF) ratio had the highest predictive contribution. These findings support the usefulness of urinary steroid metabolites, especially 18OHTHA and 18OHF, as predictors of PA subtypes.
The contribution of feature categories and subcategory levels to subtype prediction was assessed. In the RF model, category B contributed the most, followed by categories A, D, and C. Adding category B to category A improved prediction performance, and including all categories provided further benefits. Category C showed limited predictive contribution. Subcategory analysis within category A showed that tumor size was the largest factor. The usefulness of challenge test features within category B in subtype classification has been reported in previous studies. However, it remains unclear which test (CCT, FUT, or AST) is useful. In this study, the parameters of each test were subcategorized to facilitate comparison. In the RF model, CCT and AST showed larger predictive contributions than FUT. Within category D, some individual metabolites showed high contributions, but the total and ratio contributions of metabolites were low, probably reflecting the inclusion of non-beneficial components.
In terms of effective machine learning models, the prediction accuracy on the test dataset ranges from 0.797 to 0.913, indicating relatively high performance. Decision tree models (RF, GBDT) and MLP outperformed regression-based models (LR, SVM). The LR model was limited by its linear nature and could not capture feature interactions. However, important features such as serum K, CCT90-PAC, and tumor size were highlighted and provided high interpretability. Lasso regularization reduced the LR model to nine features, most of which overlapped with variables showing low p-values in Supplementary Table 3. The relative poor performance of LR may partially reflect its overreliance on limited features. The nonlinear regression model SVM outperformed LR and achieved 100% specificity for uPA prediction, although sensitivity was low. Decision tree models effectively capture feature interactions and increase accuracy. The accuracy of the RF model was over 90% and effectively integrated steroid-related features to enhance prediction. Although GBDT often achieves better performance than RF, overfitting may have occurred due to the limited data in this study.
Although the deep learning model MLP achieved high prediction accuracy, the contributing features were significantly different from those of other algorithms. Several features that had limited contribution in other models (such as MCHC) were more effectively exploited in MLP. This may be due to the ability to exploit complex interactions between variables. Nevertheless, the permutation importance value of MLP can be configuration dependent under multicollinearity. Interpretation should focus on broader functional categories rather than individual features. As a result, the predictive contributions of MLP features were relatively uniform, the individual feature-level contributions were small, and the category-level contributions were proportional to the number of features in each category. Characteristics of the urinary steroid profile (category D) were effectively exploited in MLP, with several individual metabolites showing higher contributions. Notably, despite the high accuracy achieved by MLP, both bPA and uPA predictions showed clear outliers (dot plots in Figure 2A), indicating a tendency for high-confidence misclassification. False-positive predictions in MLP may reflect clinically meaningful uPA-like features, as observed in bilateral APA. Moreover, the sensitivity of uPA remained below 0.765 across models, suggesting that some cases of uPA identified in AVS may exhibit bPA-like features. In contrast, specificity was high: 0.904 (LR), 0.923 (MLP), 0.962 (RF), 0.962 (GBDT), and 1.000 (SVM). Therefore, despite similar overall accuracy, the sensitivity and specificity profiles of the models differ, suggesting model-specific clinical implications.
Some limitations should be noted. First, the sample size (n = 274) may be insufficient for reliable development of machine learning models, despite being one of the largest single-center AVS cohorts in Japan. Second, multicollinearity exists between redundant features, which can distort estimates of predictive contribution. Third, the contribution of features varies between models, complicating the identification of consistently useful predictors. Fourth, a saline infusion test (SIT) was not performed, limiting direct comparisons between loading tests. Finally, urinary steroid profiles are not widely available and AVS criteria for subtype classification are not fully standardized.50; therefore, results may vary with other settings. The purpose of this study was not to present a single best model or a fixed ranking of predictors, but to compare the performance of five machine learning algorithms and assess the relative usefulness of features and predefined feature categories. Despite these limitations, this study has notable strengths. (1) Five different machine learning models were examined to demonstrate the potential utility of RF for predicting PA subtypes. (2) A wide range of 196 clinical features, including urinary steroid metabolites, were collected and CCT90-PAC was identified as a useful predictor for the RF model. (3) Feature categories and subcategories were defined to improve interpretability under the influence of multicollinearity between features.
In summary, a machine learning-based model using 196 features can effectively predict PA subtypes. Realize RF model ≧The prediction accuracy on the test dataset is 90%, and category B, which includes challenge tests, contributes the most to the prediction. These findings suggest that a predictive model based primarily on stress test-related features can achieve good predictive performance with a small feature set and reduce dependence on AVS to support clinically viable treatment selection. External validation and misclassification analysis remain essential to improve models and achieve reliable PA subtype prediction.


