The fourth machine learning advent calendar.
During the first three days, we looked at: distance-based model For supervised learning:
In all these models, the idea was the same. Measure distance and determine output based on nearest point or nearest center.
Today we remain in this same mindset. However, distance is used unsupervised. K-means.
Now, I have one question for those who already know this algorithm. Which model is k-means more similar to: a k-NN classifier or a nearest centroid classifier?
And if you remember, in all the models we’ve looked at so far, there wasn’t actually a “training” phase or hyperparameter tuning.
- For k-NN, there is no training at all.
- For LDA, QDA, or GNB, training simply computes the mean and variance. There are also no real hyperparameters.
Now we’ll use K-means to implement a training algorithm that ultimately looks like “real” machine learning.
Start with a small 1D example. Now let’s move on to 2D.
K-means goals
The training dataset includes No initial label.
The goal of K-means is create Create meaningful labels by grouping points that are close to each other.
Take a look at the diagram below. Two dot groups are clearly visible. Each centroid (red and green squares) is at the center of the cluster, and all points are assigned to the nearest point.
This makes it very intuitive to see how K-means detects structure using only distance.
Here, k means the number of centers we are trying to find.

Now let’s answer the following questions. Is the k-means algorithm closer to the k-NN classifier or the nearest centroid classifier?
don’t be fooled k with k-NN and K-means.
They do not mean the same thing.
- in k-NN, k It’s not the number of classes, it’s the number of neighborhoods.
- in K-means, k It is the number of centroids.
The K-means method is nearest centroid classifier.
Both models are expressed as: center of gravityAnd for a new observation, simply calculate the distance to each centroid to determine which centroid it belongs to.
Of course the difference is nearest centroid classifierwe already have know Because centroids are obtained from labeled classes.
in K-meansI don’t know the center of gravity. The overall goal of this algorithm is to discover Extract the right stuff directly from your data.
Business problems are completely different. Instead of predicting the label, create they.
K-means yields: k (number of centers of gravity) is unknown. Therefore, it is hyperparameter That it can be adjusted.
K-means with only one feature
Let’s start with a small 1D example so that everything is displayed on one axis. Then select the values in a simple way that will quickly reveal the two centroids.
1, 2, 3, 11, 12, 13
Yes, 2 and 12.
But how does a computer know that? Machines “learn” by making incremental guesses.
This is where an algorithm called . Lloyd’s algorithm.
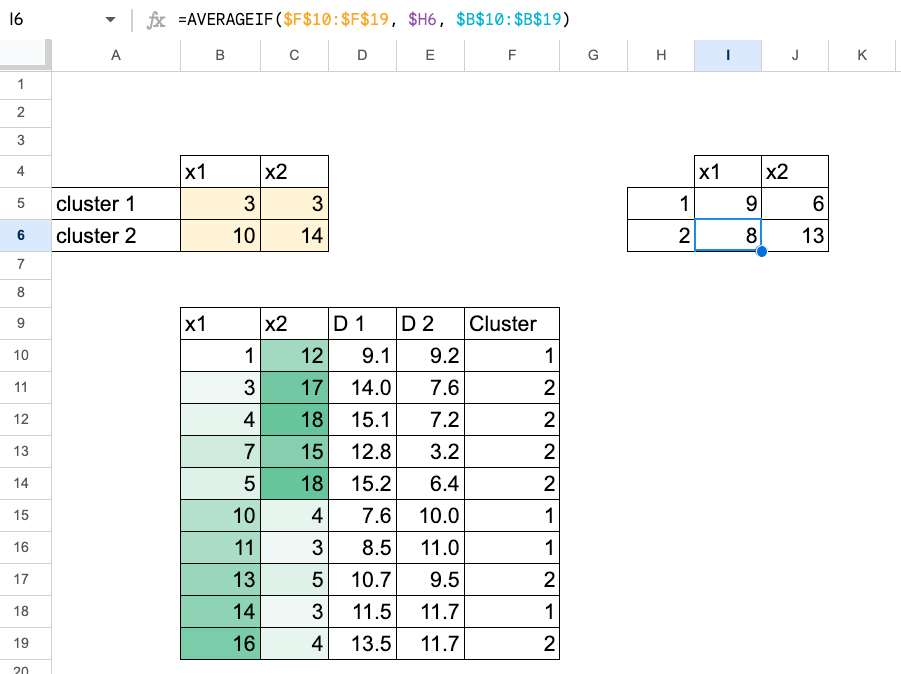
Implement it in Excel using the following loop.
- Please select the initial center of gravity
- Calculate the distance from each point to each centroid
- Assign each point to the nearest centroid
- Recalculate the centroid as the average of the points within each cluster.
- Repeat steps 2-4 until the center of gravity stops moving.
1. Select the initial centroid
For example, select the first two centers.
These must be within the data range (1-13).

2. Calculate distance
For each data point x:
- Calculate the distance to c_1.
- Calculate the distance to c_2.
Typically, 1D uses absolute distance.
You now have two distance values for each point.

3. Cluster assignment
For each point:
- Compare the two distances,
- Assign the smallest cluster (1 or 2).
In Excel, this is easy IF or MIN base logic.

4. Calculate the new centroid.
For each cluster:
- Get the points assigned to that cluster,
- calculate their average,
- This average becomes the new centroid.

5. Iterate until convergence
Formulas in Excel make it easy to: Paste the new centroid value to the initial centroid cell.
The update is instantaneous and after doing this a few times you will notice that the value stops changing. That’s when the algorithm converges.

You can also record each step in Excel so you can see how the centroids and clusters change over time.

K-means with two features
Now let’s use two functions. The process is exactly the same, simply using 2D Euclidean distance.
you can do either Copy and paste the new centroid value. (only a few cells to update),

or you can also view all intermediate steps See the complete evolution of the algorithm.

Visualizing the movement of the center of mass in Excel
To make the process more intuitive, it is useful to create a plot that shows how the center of mass moves.
Unfortunately, Excel and Google Sheets aren’t ideal for this kind of visualization, and organizing data tables can quickly become a bit complicated.
If you want to see a complete example with a detailed plot, you can read this article I wrote almost 3 years ago. In this article, each step of center of gravity shift is clearly illustrated.

As you can see from this image, the worksheet is very unorganized compared to the previous table, which was very simple.

Choosing the optimal k: Elbow method
So now you can try k = 2 and k = 3 In our case we calculate the inertia of each. Then simply compare the values.
You can also start with k=1.
For each value of k:
- Run K-Means until convergence.
- calculate inertiais the sum of the squared distances between each point and its assigned centroid.
For Excel:
- For each point, find the distance to its center of gravity and square it.
- Add up all these squared distances.
- This gives us the inertia of this k.
for example:
- If k = 1, the centroid is just the global average of x1 and x2.
- For k = 2 and k = 3, we obtain the converged centroids from the sheet on which we ran the algorithm.
You can then plot the inertia as a function of k, for example (k = 1, 2, 3).
For this dataset
- Going from 1 to 2 will significantly reduce inertia.
- From 2 to 3, the improvement is much smaller.
The “elbow” is the value of k at which the inertia decreases to a limit. This example suggests that k = 2 is sufficient.

conclusion
K-means is a very intuitive algorithm when you step through it in Excel.
Starting with a simple centroid, calculate distances, assign points, update centroids, and repeat. Now you understand how machines learn.
This is just the beginning. It turns out that different models actually “learn” in different ways.
And this is the transition for tomorrow’s article. unsupervised version nearest centroid classifier surely K-means.
So what would be the unsupervised version? LDA or QDA?We will answer this in the next article.



