
A research team from Meta FAIR and New York University systematically investigated how to train multimodal AI models from scratch. Their findings challenge some widely held beliefs about how these models should be constructed.
Language models defined the era of foundational models. However, in their paper “Beyond Language Modeling,” the researchers argue that text is ultimately a lossy compression of reality. They suggest that, based on Plato’s allegory of the cave, the language model learned to describe the shadow on the wall without seeing the object casting the shadow. There are also practical issues. High-quality text data is finite and quickly depleted.

This research was joined by Yann LeCun before he retired and trained a single model completely from scratch. It combines standard word-by-word prediction for the language with a diffusion technique called flow matching on visual data, training on text, video, image-text pairs, and action-related videos. By not building on top of existing language models, researchers avoid contaminating their results with previously learned knowledge.
A single visual encoder can handle both comprehension and production
Previous approaches such as Janus and BAGEL used separate visual encoders for image understanding and image generation. Meta researchers found that this separation was unnecessary.
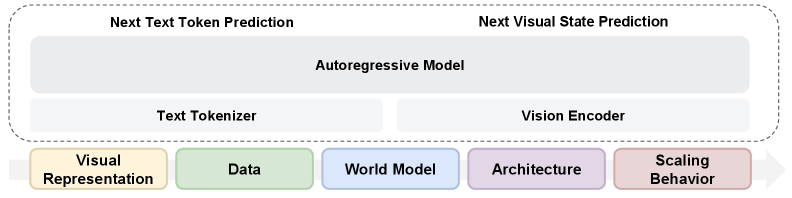
Research shows that a representational autoencoder (RAE) built on the SigLIP 2 image model performs better than a traditional VAE encoder in both image generation and visual understanding. Language performance is comparable to text-only models.
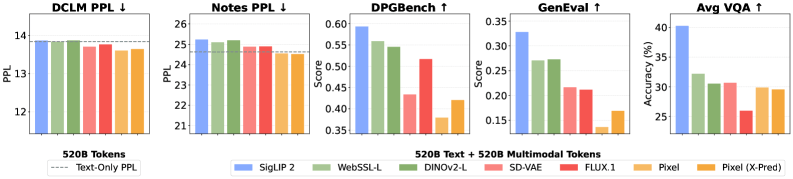
Rather than maintaining two separate paths, one encoder handles both tasks, greatly simplifying the architecture. This challenges the common assumption that vision and language necessarily compete within the model. Research shows that raw videos without text annotations have no effect on language ability. On the validation dataset, the model trained on both text and video actually outperforms the text-only baseline.
The researchers trace the slight degradation seen in the image-text pairs to a distribution gap between the regular training text and the image caption, rather than the visual modality itself.
The synergy is significant. Adding 20 billion VQA tokens (visual question answering data) with 80 billion tokens from videos, image-text pairs (MetaCLIP), or plain text each outperforms a model trained on 100 billion pure VQA tokens.
World modeling appears without explicit training
The researchers also tested whether the model could learn to predict visual states. Given the current image and navigation instructions, the model must predict the next visual state. No architectural changes are required because the actions are encoded directly as text.

According to the researchers, world modeling ability arises primarily from general multimodal training rather than from task-specific navigation data. This model achieves competitive performance with only 1% task-specific data. It can even follow natural language commands like “Come out of the shadows!” It produces matching image sequences even though it never encountered such input during training.
Uniquely determine capacity allocation with a mix of experts
For architecture, the researchers considered a Mixture-of-Experts (MoE). This is an approach where each input token is routed to only a specialized subset of network modules, rather than activating the entire model. This saves computing while increasing overall capacity.
Research shows that the model has a total of 13.5 billion parameters, but only 1.5 billion active parameters per token, so MoE outperforms both dense models and manually designed separation strategies. This model automatically captures expertise and assigns far more expertise to language than to vision. Early layers are dominated by text-specific experts, while deeper layers are increasingly populated by visual and multimodal experts.
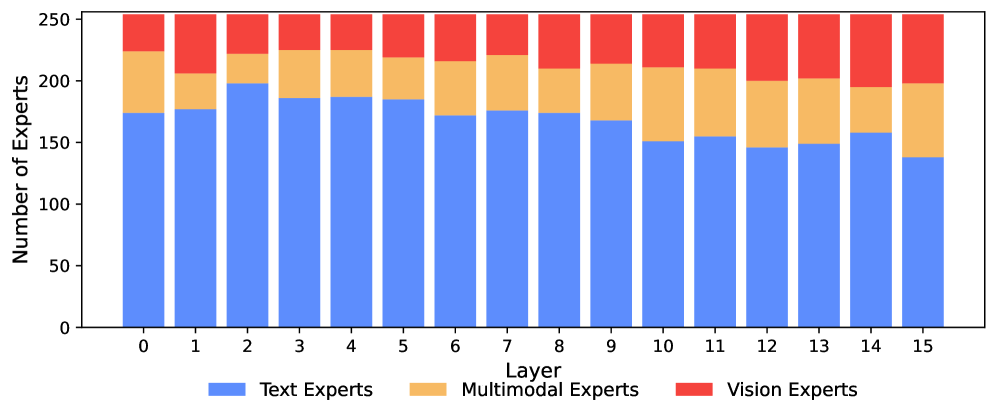
One notable finding is that image understanding and image generation activate the same experts, with a correlation of at least 0.90 across all layers. Researchers see this as confirmation of Richard Sutton’s “bitter lesson” that learning from data usually beats hand-designed solutions.
Properly scaling your vision requires much more data than language
Training AI models always involves fundamental trade-offs in how to divide a fixed computing budget. You can build larger models with less data, or smaller models with more data. Chinchilla’s scaling laws showed that for a pure language model, both should grow at about the same rate.
Meta researchers calculated these scaling laws for a collaborative visual language model for the first time and found large asymmetries. When it comes to language, there is a familiar balance. When it comes to vision, optimization has largely shifted to data. Visual features benefit disproportionately from more training data, but increasing the model size provides relatively little improvement.
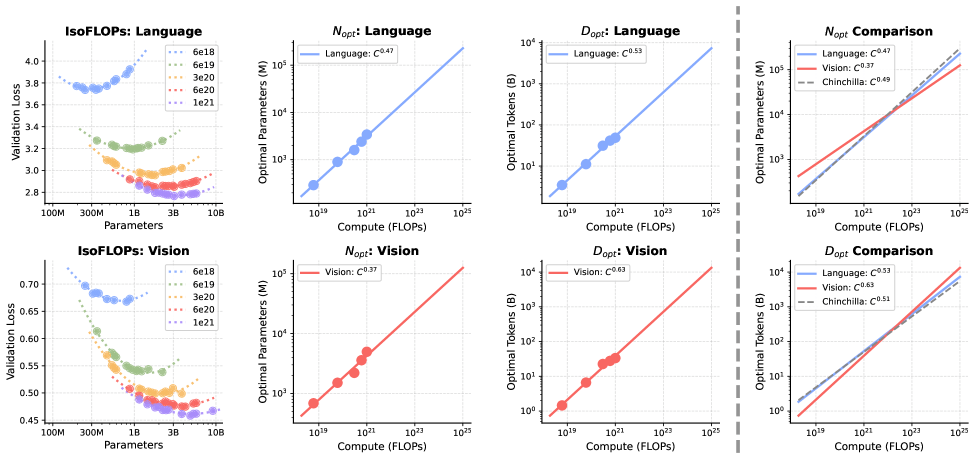
The larger the model, the larger the gap in data requirements. Research shows that starting with a billion parameter base, the relative need for visual data compared to verbal data increases by a factor of 14 for 100 billion parameters and by a factor of 51 for 1 trillion parameters. The language expands much more modestly in this range. In traditional dense models, all parameters are active at every step, making it nearly impossible to resolve this imbalance.
Expert mixed architecture helps bridge the gap. Because there is only a fraction of experts firing for each token, the model can carry a huge total number of parameters without a proportional increase in computational cost. Languages obtain the required high parameter capacity, whereas visuals benefit from the large amounts of data required. Research shows that MoE reduces the scaling asymmetry between two modalities by half.
The researchers note that their study only covers pre-training and does not look into fine-tuning or reinforcement learning. Still, they consider the results to be evidence that the boundaries between multimodal and world models are becoming blurred by the day. Studies have shown that large amounts of unlabeled videos remain largely untapped, and that they can be folded without compromising language performance.
AI News Without the Hype – Curated by Humans
as The Decoder Subscriberyou can read without ads. Weekly AI Newsletterexclusive “AI Radar” Frontier Report 6 times a yearaccess comments, and Complete archive.
Subscribe now


