

Google Research announced A groundbreaking way to fine-tune large language models (LLMS) that reduce the amount of training data required by up to 10,000 timeswhilst maintaining or improving the quality of the model. This approach focuses on the most useful examples: expert labelling efforts to actively learn and focus on “boundary cases” where model uncertainty is at peak.
Traditional bottleneck
Large, high-quality labeled datasets are typically required to fine-tune LLMS for tasks that require deep contextual and cultural understanding, such as advertising content safety and moderation. Most of the data is benign. In other words, when it comes to policy violation detection, only a small fraction of the examples are important, increasing the cost and complexity of data curation. Also, standard methods struggle to keep up with changing policies and problematic patterns and require expensive retraining.
Google's Active Learning Breakthrough
How it works:
- llm-as-scout: LLM is used to scan a vast number of corpus (thousands of billions of examples) and identify the least certain cases.
- Targeted expert labeling: Instead of labeling thousands of random examples, human experts only annotate items that cause confusion in those boundaries.
- Iterative curation: This process is repeated in each batch of new “problematic” examples that are notified by the confusion points of the latest model.
- Rapid convergence: The model is fine-tuned in multiple rounds and continues through iteration until the output of the model is closely matched with expert judgment. This is measured by Cohen's kappa, which accidentally compares matches between annotators.
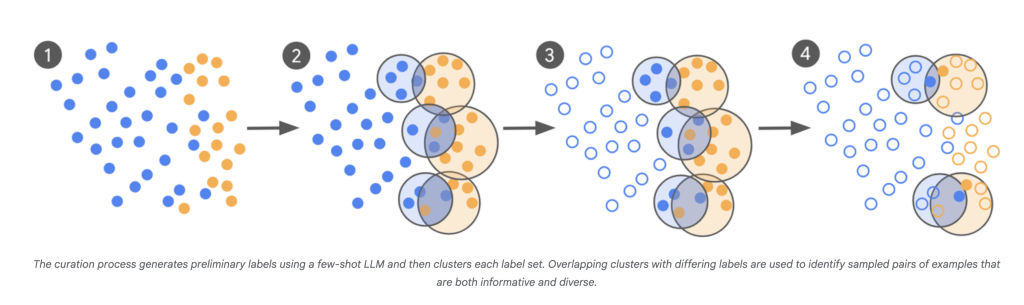
Impact:
- Data should plummet: Experiments using Gemini Nano-1 and Nano-2 models reached more than parity in consistency with human experts. 250-450 properly selected examples It's a 3-4 digit reduction, not a random crowdsourcing label of ~100,000.
- Model quality improvement: For more complex tasks and larger models, performance improvements reached 55-65% over baseline, indicating more reliable consistency with policy experts.
- Label efficiency: A reliable profit using small datasets consistently required high label quality (Cohen's Kappa>0.8).
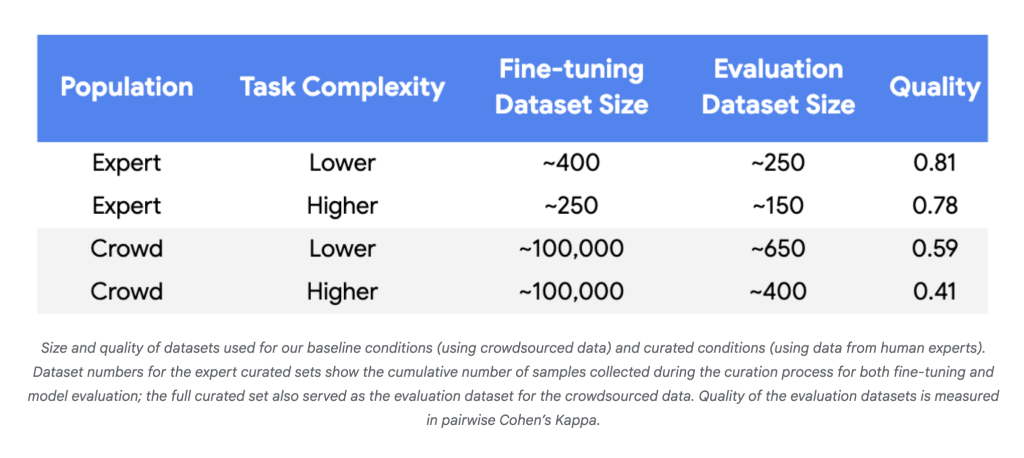
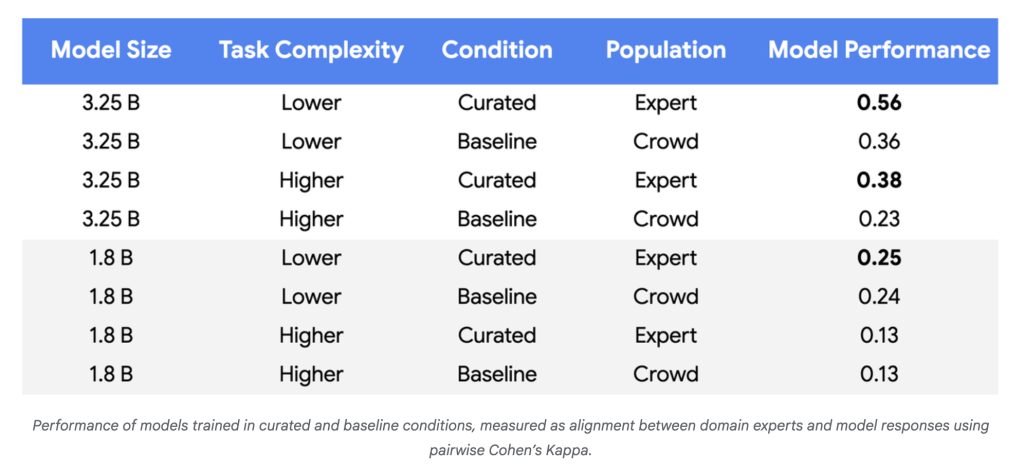
Why is it important?
This approach reverses the traditional paradigm. Rather than a model owned by a vast pool of noisy redundant data, it leverages both the ability of LLM to identify ambiguous cases and the domain expertise of the human annotator whose inputs are most valuable. The advantage is profound:
- Cost reduction: There are significantly fewer examples of dramatically lowered labor and capital expenditures.
- Faster updates: The ability to retrain models with just a handful of examples makes adapting to new abuse patterns, policy changes, or domain shifts quick and feasible.
- Social impact: Improved capabilities for context and cultural understanding will improve the safety and reliability of automated systems that handle sensitive content.
In summary
Google's new methodology allows LLM to be tweaked with complex and evolving tasks with hundreds of thousands of targeted (hundreds of thousands) of high fidelity labels.

Mikal Sutter is a data science expert with a Master's degree in Data Science from Padova University. With its solid foundations of statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.


