Linear codes underpin nearly all modern digital communication and data storage, but significant mathematical hurdles exist to discovering the most effective codes, known as champion codes. Yang-Hui He, Alexander M Kasprzyk, Q Le, and Dmitrii Riabchenko have developed a new approach that leverages the power of machine learning to overcome this challenge. The team trained a transformation model to accurately predict the minimum Hamming distance, an important property of linear codes, and combined this with a genetic algorithm to efficiently search for optimal solutions. This innovative method significantly reduces the amount of computation required to identify champion codes, opening new avenues for the advancement of error-correcting codes used in a wide range of applications, from secure communications to reliable data storage systems.
Coding theory underpins all modern communications, and error-correcting codes are essential for reliable data transmission over networks and space. Researchers continually seek to find champion codes with optimal performance characteristics, but this poses significant computational challenges. This study details a new method to discover these codes, effectively reducing the search space required to achieve them, and improving the efficiency of code construction. The results demonstrate the application of this method to the study and construction of error-correcting codes, potentially including quantum codes and generalized toric codes.
Machine learning discovers champion linear code
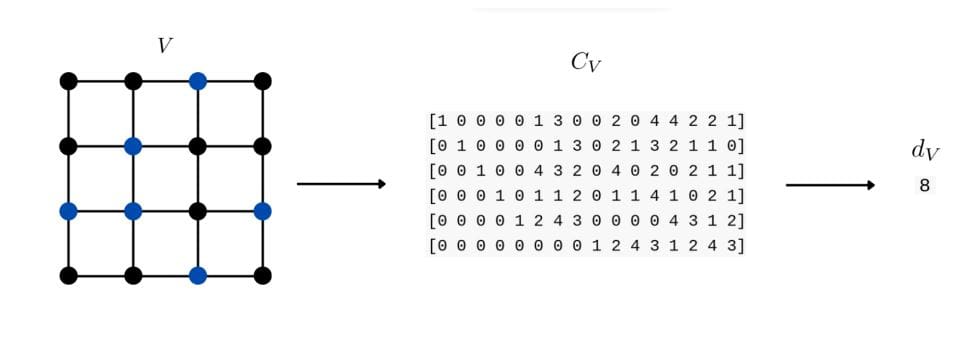
Scientists have developed a new method to discover champion linear codes by combining machine learning and genetic algorithms. This addresses a computationally difficult problem, as identifying such codes is known to be very difficult. The team trained a transformation model to predict the minimum Hamming distance for a specific class of linear codes, which are generalized toric codes over the finite field F7, and achieved an accuracy of about 91.6% with a small error bound and low mean absolute error on the test dataset. By combining this predictive model with genetic algorithms, the researchers were able to rediscover champion codes previously identified in existing literature.
Extending this approach to the finite field F8, the team discovered over 500 champion codes, at least six of which were entirely new discoveries. Comparisons with random search techniques show that this new technique improves computational efficiency by up to 2 times, as measured by the number of evaluations required to identify champion codes. These advances build on previous work classifying generalized toric codes and overcome the limitations encountered when extending these methods to F8 due to computational cost. The team's method is designed to be broadly applicable to any family of linear codes with evolvable parameter spaces, providing powerful new tools for code construction and optimization. This breakthrough represents a significant advance in coding theory and has potential applications in digital communications and data storage systems.
Transformer-Genetic algorithm finds champion linear code
This study presents a new method for discovering high-performance linear codes that are essential components of modern digital communication and data storage systems. By combining a genetic algorithm with a transformer model trained to predict the minimum Hamming distance of a code, scientists have developed a system that efficiently narrows the search space for champion codes. The team successfully applied this method to the study and construction of codes, with potential implications for a variety of code types, including generalized toric codes, Reed-Mallah codes, and Bose Chaudhry-Hockenghem codes. The results demonstrate the effectiveness of this approach in identifying codes with good properties.
The team generated and analyzed a large dataset of codes, revealing patterns in the predictability of minimum Hamming distances and highlighting specific codes that pose significant challenges to accurate predictions. The researchers were able to train a model to extract useful features and generalize knowledge across different code subsets, while recognizing data collection limitations and runtime constraints. Future research will focus on addressing these limitations and extending the application of this method to a wider range of code types, which may lead to further advances in the field of error-correcting codes.


