


Multilayer perceptrons (MLPs), or fully connected feedforward neural networks, are the basis of deep learning and serve as the default model for approximating nonlinear functions. Despite their importance being confirmed by the universal approximation theorem, they also have drawbacks. In applications such as transformers, MLPs often dominate parameters and are less interpretable than attention layers. While exploring alternatives such as the Kolmogorov-Arnold representation theorem, research has mainly focused on traditional depth-2-width (2n+1) architectures, neglecting modern training techniques such as backpropagation. I'm here. Therefore, while MLP remains important, the search for more effective nonlinear regressors in neural network design is ongoing.
Developed by researchers at MIT, Caltech, Northeastern, and the NSF AI and Fundamental Interactions Laboratory Kolmogorov Arnold Network (KAN) As an alternative to MLP. Unlike MLP with fixed node activation functions, KAN employs learnable activation functions on edges and replaces linear weights with parameterized splines. This modification allows KAN to surpass MLP in both accuracy and interpretability. Through mathematical and empirical analysis, KAN exhibits better performance, especially in processing high-dimensional data and solving scientific problems. In this study, we introduce the KAN architecture, present comparative experiments with MLP, and introduce the interpretability and applicability of his KAN in scientific discovery.

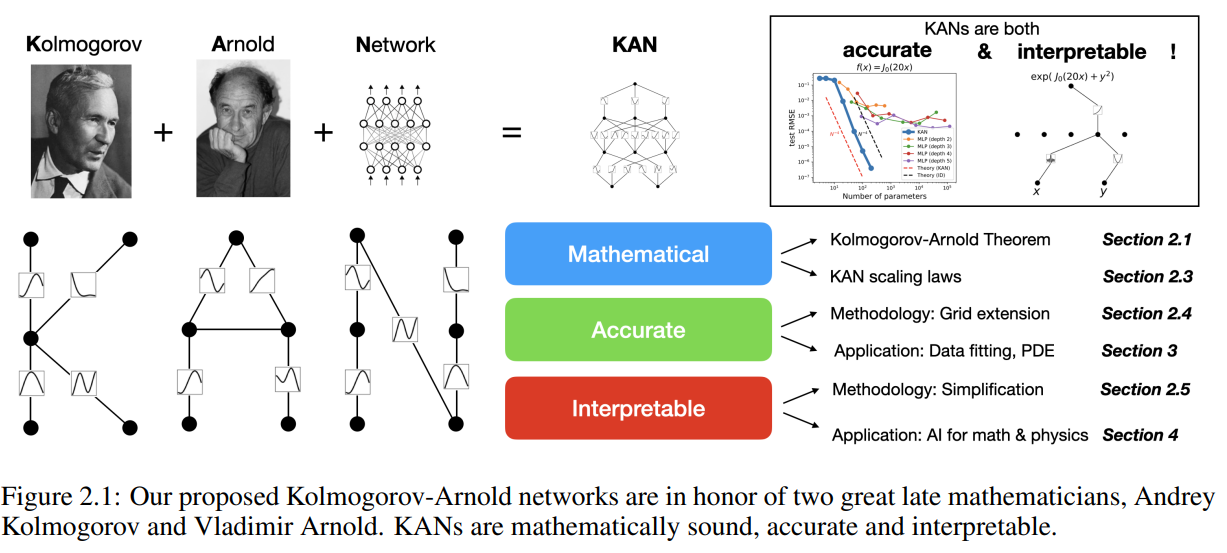
Existing literature has investigated the relationship between the Kolmogorov-Arnold Theorem (KAT) and neural networks, and previous studies have mainly focused on limited network architectures and toy experiments. This work contributes by extending networks to arbitrary size and depth, making them relevant for modern deep learning. We also cover neural scaling laws (NSLs) and show how Kolmogorov-Arnold representations enable fast scaling. This work also delves into mechanical interpretability (MI) by designing an architecture that is inherently interpretable. Learnable activation and symbolic regression techniques are considered, highlighting the continuously learned activation function approach in KAN. Furthermore, KAN has shown potential to replace MLP in physically informed neural networks (PINNs) and AI applications in mathematics, especially knot theory.
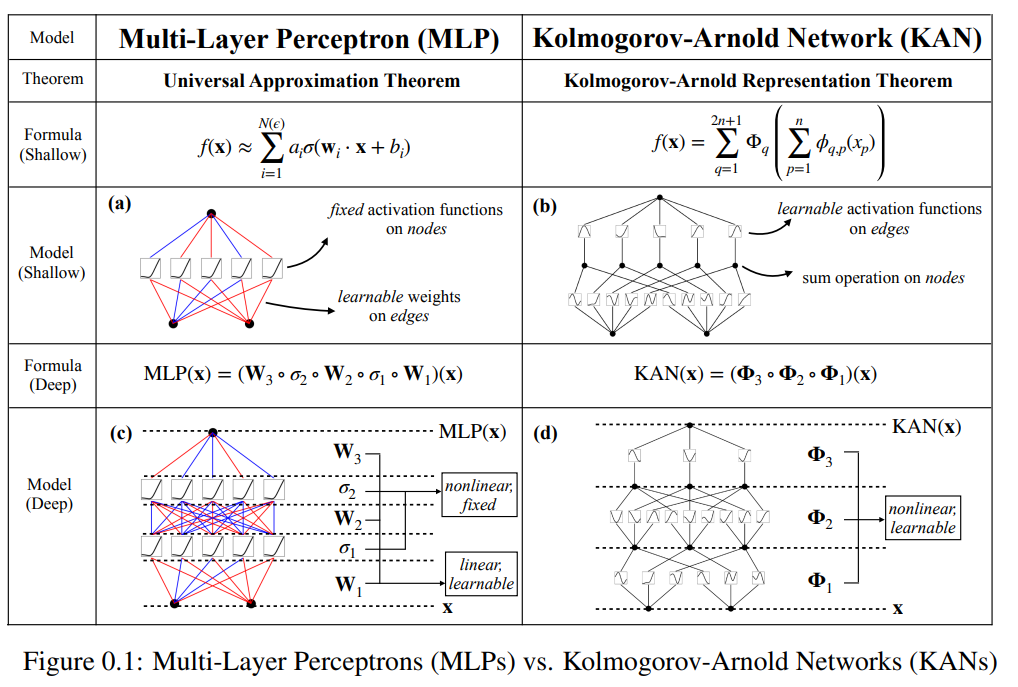
KAN takes inspiration from the Kolmogorov-Arnold representation theorem. This theorem asserts that any bounded multivariate continuous function can be represented by combining a univariate continuous function with an addition operation. KAN exploits this theorem by employing univariate B-spline curves with tunable coefficients to parameterize functions across multiple layers. By stacking these layers, KAN becomes deeper and aims to overcome the limitations of the original theorem and achieve smoother activations for better function approximations. Theoretical guarantees such as the KAN approximation theorem place limits on the accuracy of the approximation. Compared to other theories such as the universal approximation theorem (UAT), KAN provides a promising scaling law due to its low-dimensional functional representation.

In this study, KAN outperforms MLP in representing functions across a variety of tasks, including regression, solving partial differential equations, and continuous learning. KAN exhibits good accuracy and efficiency, especially in capturing special functions and complex structures in Feynman datasets. These demonstrate interpretability by revealing compositional structures and topological relationships, and the potential for scientific discovery in areas such as knot theory. KAN is also promising for solving unsupervised learning problems and provides insight into the structural relationships between variables. Overall, KAN emerges as a powerful and interpretable model for AI-driven scientific research.
KAN provides an approach to deep learning that leverages mathematical concepts to improve interpretability and accuracy. Even though it takes longer to train than a multilayer perceptron, KAN excels in tasks where interpretability and accuracy are paramount. Efficiency remains an engineering challenge, but research aimed at optimizing training speed is ongoing. If interpretability and accuracy are key priorities and time constraints are manageable, his KAN is a better choice than MLP. However, for tasks where speed is a priority, MLP is still a more practical option.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits


Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a new perspective to the intersection of AI and real-world solutions.


