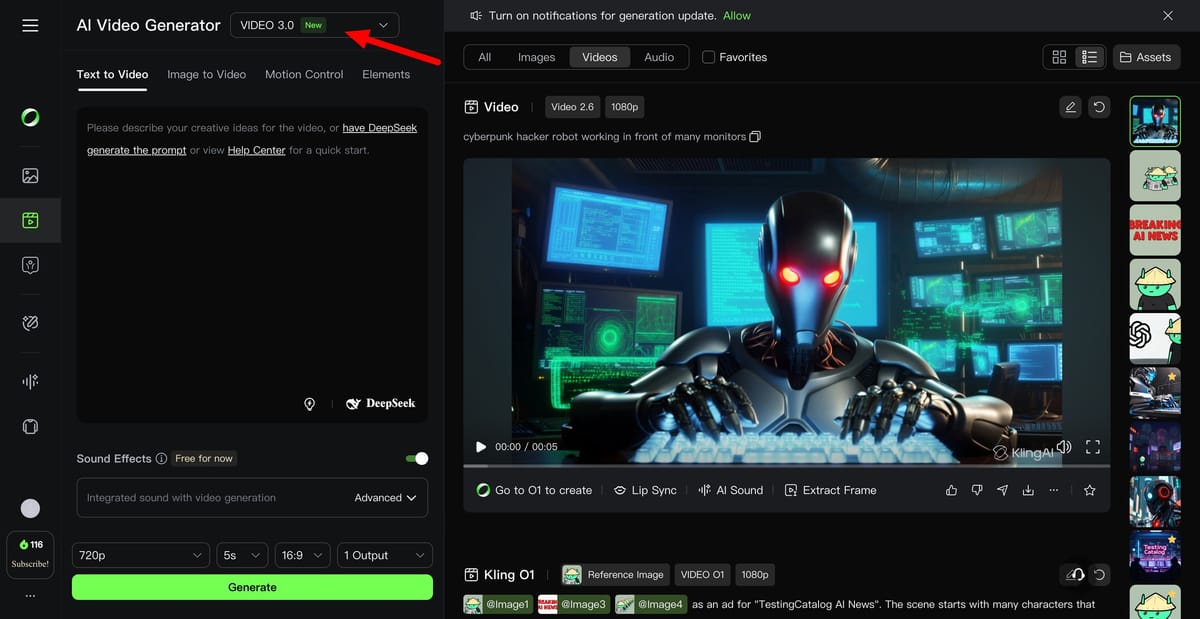
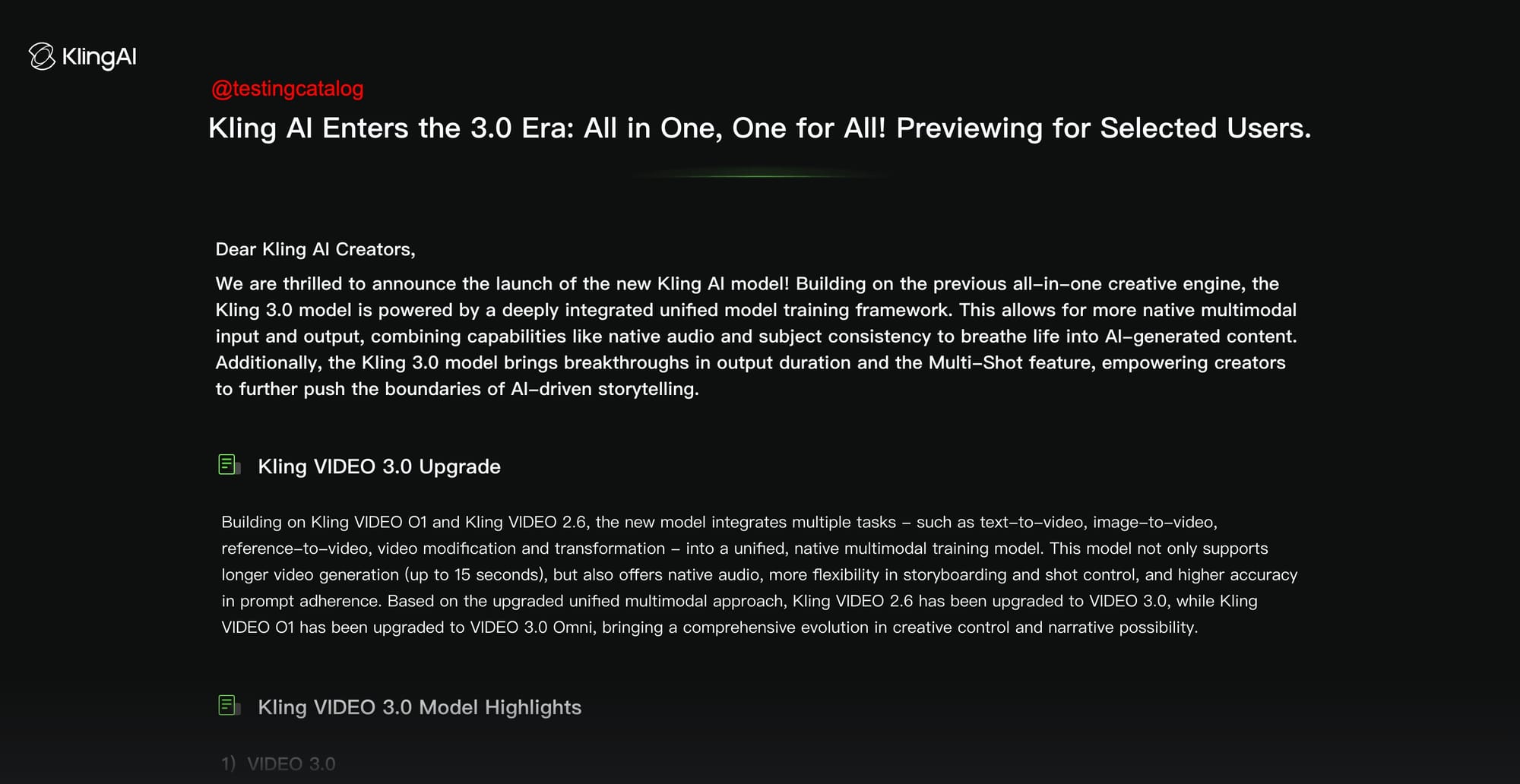
Kling AI is preparing to enter the “3.0 era” with a new integrated video model that is not yet publicly available and is being previewed to a limited number of users. Its position is clear. Rather than splitting workflows into separate tools or model lines, Kling aims to be an all-in-one creative engine that can handle text-to-video, image-to-video, reference-based generation, and video modification in one native multimodal training framework.
Kling 3.0 model now available!
Currently in exclusive early access. Please look forward to future developments. 🚀 pic.twitter.com/XcyZBRQPCz— Kling AI (@Kling_ai) January 31, 2026
On the product side, Kling VIDEO 3.0 is described as integrating the previous VIDEO 2.6 features and the previous VIDEO 01 line into a single “VIDEO 3.0” family. The main promise is that it gives creators more control without forcing them into complex editing pipelines. Kling emphasizes longer single generation clips with output durations reaching up to 15 seconds and flexible control from 3 seconds to 15 seconds. This is structured as something that allows for more complete story beats rather than short pieces pieced together externally.
A core feature teased in VIDEO 3.0 is multi-shot, delivered as an “AI Director” style storyboarding workflow. The idea is that the model can interpret scene coverage and shot patterns directly from prompts and automatically adjust camera angles and compositions, from basic shot and reverse shot dialog setups to more complex sequences. Kling also claims that this reduces the need for manual cutting and editing, as the output is intended to arrive in a single generation as a more “cinematic” sequence.
Kling also highlights thematic consistency as a significant upgrade, especially in image-to-video conversion and reference-driven work. Preview materials describe a system that allows you to freeze the “core elements” of a character or scene so that they don’t shift as the camera moves or the scene develops. This is combined with support for multi-image and video references as “elements”. This seems to be Kling’s term for a reusable character or asset anchor that can be brought into the new generation.
Audio is another pillar of our release schedule. According to Kling, VIDEO 3.0 aims to reduce ambiguity in multi-character scenes by upgrading native audio output with character-specific voice references to help creators identify who is speaking. It also argues for broader language support, listing languages such as English, Chinese, Japanese, Korean, and Spanish, which it positions as enabling more natural-looking bilingual or multilingual scenes with consistent dialogue and lip movements.
Beyond motion and audio, the preview highlights “native-level text output” capabilities with an emphasis on accurate lettering. Kling believes this will help with the layout of signage, captions, and advertising styles. There, easily readable text is often a point of failure for generated videos. If it works as described, Kling will become more of a production-oriented tool for commercial and marketing assets than just a stylized clip.
The VIDEO 3.0 Omni variant is positioned as a more reference-oriented branch. Kling claims that it improves subject consistency, immediate compliance, and output stability compared to previous reference models. It also extends Elements 3.0 to include video character references with both visual and audio capture. In fact, Kling proposes a workflow where users can upload short clips of their characters to extract visual features, optionally provide audio clips to extract vocal features, and reuse those elements across scenes for continuity.
Kling also emphasizes more granular shot control in the storyboard flow, including duration, shot size, perspective, narrative content, and shot-by-shot camera movement, with the goal of smoother transitions and more structured multi-shot sequences. This shows that Kling is trying to compete not only on model quality, but also on creative direction tools that fall between pure prompts and full NLE editing.
On the enterprise side, Kling presents this as an architectural advancement. It is a native framework for multitasking, versatile video generation, as well as cross-modal audio modeling and a reference system aimed at separating and recombining subjects across scenes. The broader view is that creators want longer, more consistent sequences with consistent character and integrated sound, and they want to achieve that with fewer external steps.
The key point at this point is availability. Kling AI has framed this as an upcoming release, previewing it for select users and planning broader access later. Details shared so far appear to be a roadmap for a unified “video OS” within Kling’s products, centered around longer generations, multi-shot storyboards, stable character references, and integrated audio.


