


Iteration-first optimization techniques have shown effectiveness in general instruction coordination tasks, but provide limited improvements in inference tasks. These methods leverage configuration optimization to enhance the consistency of language models with human requirements compared to supervised fine-tuning alone. Offline technologies such as DPO are gaining popularity due to their simplicity and efficiency. Recent advances recommend iterative application of offline procedures such as iterative DPO, self-rewarding LLM, and SPIN to build new preference relationships and further improve model performance. However, despite the successful application of other iterative training techniques such as STaR and RestEM to inference tasks, preference optimization remains unexplored in this area.
Iterative adjustment methods include both human-involved and automated strategies. Some rely on human feedback for reinforcement learning (RLHF), while others, like iterative DPO, autonomously optimize preferred pairs and use updated models to create new pairs for subsequent iterations. Some generate. SPIN, a type of Iterative DPO, uses human labels and model generation to build preferences, but faces limitations when model performance matches human standards. Self-rewarding LLM also employs an iterative DPO that uses the model itself as a reward evaluator, resulting in modest improvements in inference but improved subsequent instructions. Conversely, Expert Iteration and STaR focus on sample curation and training data refinement, as opposed to pairwise priority optimization.
Researchers at Meta's FAIR and New York University are introducing an approach targeting iterative-first optimization of inference tasks, specifically chain of thought (CoT) reasoning. At each iteration, we sample multiple her CoT inference steps and the final answer and construct preference pairs where the winner holds the correct answer and the loser holds the wrong answer. Training requires her DPO variant, which incorporates a negative log-likelihood (NLL) loss term on the pairwise winner, which is essential for improved performance. The iterative process iterates by generating new pairs and retraining the model from previously trained iterations, incrementally improving the model's performance.

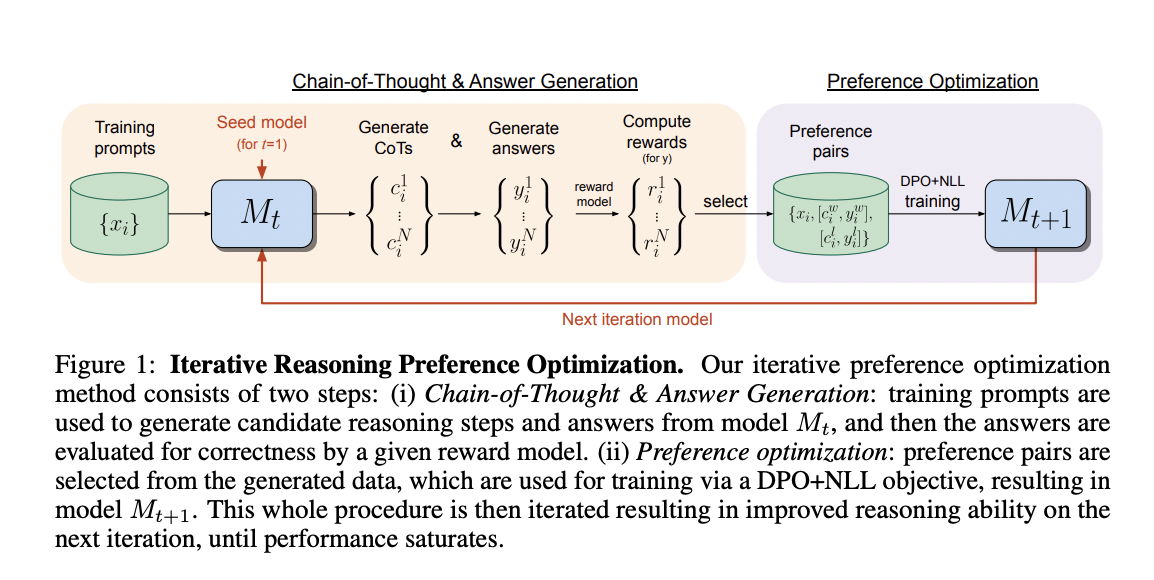
Their approaches rely on a base language model, typically pre-trained or instruction-tuned, and a dataset of training inputs with the ability to evaluate the accuracy of the final output. Given training input, the model generates (i) a series of inference steps (thought chains) and (ii) a final answer. The correctness of the final answer can be evaluated, but the accuracy of the inference step is not considered. In our experiments, we utilize a dataset with gold labels as training inputs and derive a binary reward from the exact match between the label and the final answer. This method consists of two steps in each iteration: (i) thought chain and answer generation, and (ii) preference optimization.
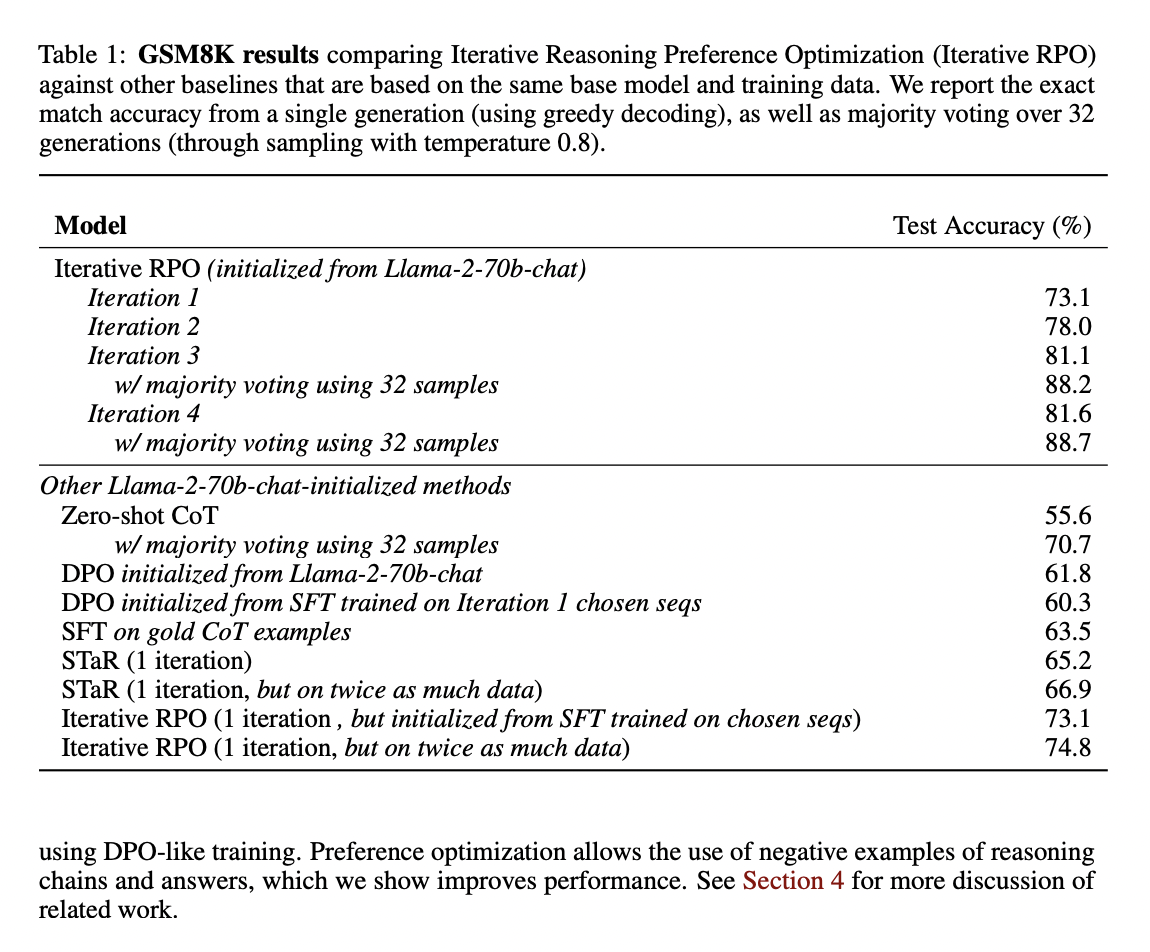
In the experiment, the researchers were trained to utilize a modified DPO loss with the addition of a negative log-likelihood term, which is considered essential. Repeating this method over and over again will improve your reasoning ability. This approach, based only on training set examples, increases the accuracy of Llama-2-70B-Chat from 55.6% to 81.6% (and 88.7% with a majority vote of 32 samples) and 12.5% to 20.8% on GSM8K. improved. It increased from 77.8% in MATH to 86.7% in ARC-Challenge. These improvements outperform other his Llama-2-based models that do not use additional datasets.

In conclusion, this study introduces iterative inference-first optimization, an iterative training algorithm aimed at improving the performance of thought chain-based inference tasks in LLM. Each iteration generates multiple responses, builds preference pairs based on the correctness of the final response, and uses her DPO loss modified with an additional her NLL term for training. Masu. This method requires no human intervention or additional training data, maintaining simplicity and efficiency. Experimental results show significant enhancements on GMS8K, MATH, and ARC-Challenge compared to different baselines using the same base model and training data. These findings highlight the effectiveness of iterative training approaches to enhance the reasoning ability of LLMs.
Please check paper. All credit for this study goes to the researchers of this project.Don't forget to follow us twitter.Please join us telegram channel, Discord channeland linkedin groupsHmm.
If you like what we do, you'll love Newsletter..
Don't forget to join us 40,000+ ML subreddits


Asjad is an intern consultant at Marktechpost. He is pursuing a degree in mechanical engineering from the Indian Institute of Technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast and is constantly researching applications of machine learning in healthcare.


