
Most search agents are trained as a policy against transcript growth. The model determines the search method. You also have to remember what you saw, what evidence was important, and what claims you checked. A team of researchers from the University of Illinois at Urbana-Champaign, the University of California at Berkeley, and the Chroma School argues that this is asking too much. Reinforcement learning will ultimately optimize both search decisions and day-to-day bookkeeping at the same time.
their answer is Harness-1a 20B acquisition subagent built on gpt-oss-20b. It was trained using reinforcement learning within a stateful search harness. Harness holds bookkeeping. Policies preserve semantic decisions. Weights and harness codes are publicly available.
What actually is Harness-1?
Harness-1 produces a set of ranked documents for downstream response models. It doesn’t answer the question itself. This is done within a state machine harness centered around a per-episode WORKINGMEMORY.
Each turn acts as a loop. Harness renders a compact search state along with recent actions. The model emits one structured action. The harness runs it, updates the state, and renders the next observation.
Stateful Harness: What’s Out of Policy?
The research team calls the principle stateful cognitive offloading. Policies determine what to search, curate, and verify, and when to stop. The harness remains recoverable based on these decisions.
That condition includes several pieces. The candidate pool holds compressed and deduplicated documents. A curated set of importance tags is the final output, and the number of documents is limited to 30. The tag takes four values: very_high, high, fair, or low. The full-text store keeps all retrieved chunks outside of the prompt.
Evidence graphs add structure. The regular expression extractor scans each chunk for proper nouns, years, and dates. The harness then renders frequently used entities, bridge documents, and singletons. A bridge document contains two or more frequently used entities. Singletons appear within one document and suggest follow-up leads.
This policy works through eight tools. These are fan_out_search, search_corpus, grep_corpus, read_document, review_docs, curate, verify, and end_search. The search output is compressed with sentence-BM25 to keep the top four sentences. Two-level deduplication removes repeats by chunk ID and content fingerprint.
One design choice is to accommodate cold starts. The first successful search automatically seeds a curated set of 8 re-ranked results with significant weight. The policy then promotes strong documentation and removes weak documentation. This changes the task from building from scratch to refining.
The research team identified three requirements for a trainable harness. These are warm-start curation, compact derived state rendering, and incentives to maintain diversity. Harness-1 implements all three.
training method
The training is divided along the same lines as the harness. Supervised fine-tuning teaches a model how to interact with an interface. Reinforcement learning improves search decisions for maintained states.
One teacher GPT-5.4 runs live in full harness. After filtering, 899 trajectories remain in the SFT. The model uses LoRA with rank 32 over 3 epochs. Step 550 Checkpoint initializes the RL.
RL uses CISPO on policy with a 40-turn cap and terminal-only rewards. Trained only on SEC queries. Groups with the same reward are excluded from the gradient. Training was performed on Tinker.
Rewards separate discovery from choice. It also has the added bonus of tool variety. Without that bonus, agents would succumb to repetitive exploration. After that, the curated recall plateaus around 0.53. With the bonus, the diversity stabilizes and the recall reaches about 0.60.
benchmark case
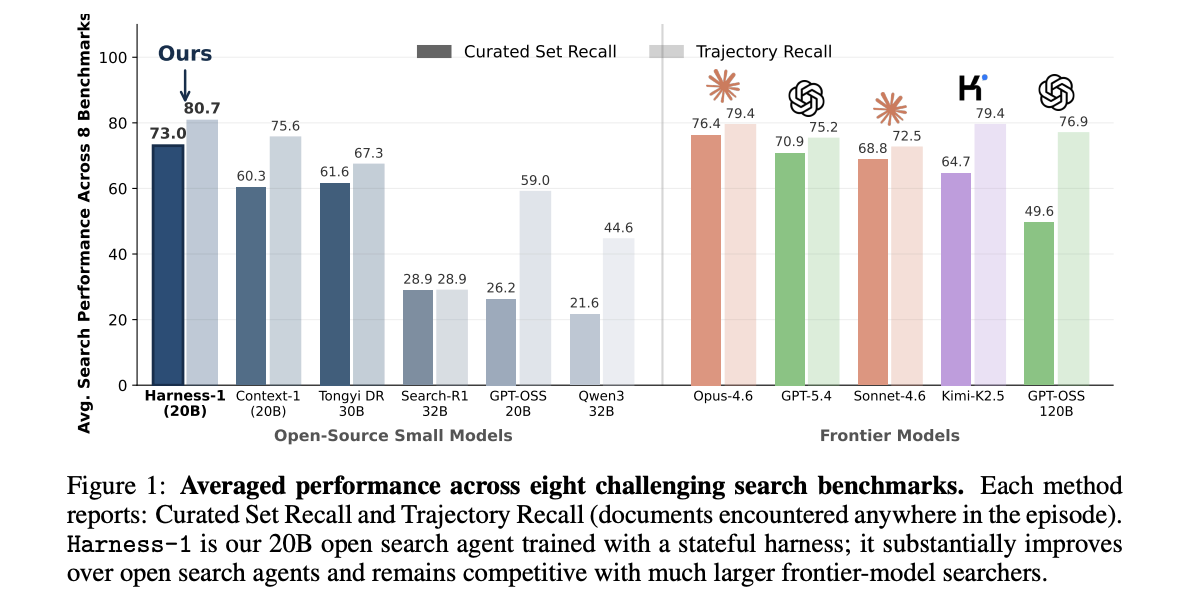
Harness-1 was evaluated on eight benchmarks across web, finance, patent, and multihop QA. The main metric is selective recall, i.e. the range of relevant documents in the final set. Trajectory recall counts evidence encountered somewhere in the episode.
| model | type | Average Curate Recall | Average trajectory recall rate |
|---|---|---|---|
| Harness-1 (20B) | open small | 0.730 | 0.807 |
| Synonymous Deep Research 30B | open small | 0.616 | 0.673 |
| Context-1 (20B) | open small | 0.603 | 0.756 |
| Search R1(32B) | open small | 0.289 | 0.289 |
| GPT-OSS-20B | open small | 0.262 | 0.590 |
| Quen 3(32B) | open small | 0.216 | 0.446 |
| Works-4.6 | frontier | 0.764 | 0.794 |
| GPT-5.4 | frontier | 0.709 | 0.752 |
| Sonnet-4.6 | frontier | 0.688 | 0.725 |
| Kimi-K2.5 | frontier | 0.647 | 0.794 |
| GPT-OSS-120B | frontier | 0.496 | 0.769 |
Harness-1 reached a curated average recall of 0.730. This is 11.4 points higher than the next open subagent, Tongyi DeepResearch 30B. Among the frontier explorers tested, only Opus-4.6 has a higher average score.
Transmission patterns are the clearest signal of mechanism. SFT used four benchmark families. RL used only SEC. For these source family tasks, Harness-1 outperformed the closest open baseline by 7.9 points. The four benchmarks that were put on hold rose 17.0 points. This is a 2.2x increase for the tasks furthest from the training data.
Ablation supports Harness’s claims. Disabling all harness mechanisms reduces Recall by 12.2 percent compared to BrowseComp+. The trained policy continues searching, but cannot rank what it sees.

Usage example
This method targets searches where documents seek evidence to support an answer. Several workflows fit this shape.
One is a literature and patent review. Evidence graphs and curated sets help organize many sources. The other is financial statement analysis. SEC case study recovers exact executive transfer dates across multiple 8-Ks.
The third is multi-hop fact checking. The fan_out_search and verify tools resolve ambiguous entities before committing. The fourth is modular RAG. The carefully selected set is fed into a frozen generator, and the better the set, the higher the answer accuracy.
Advantages and disadvantages
Strengths
- It has the highest average selection recall among the open models tested, second only to Opus-4.6 overall.
- Profit maintains benchmarks withheld, suggesting domain-wide search operations.
- It was trained on 4,352 unique items, much fewer than some baselines.
- Harness open checkpoints and code for use in a common runtime.
Weakness
- Evidence graphs use regular expression extraction instead of full entity links.
- The validator is an LLM proxy that can fail on ambiguous requests.
- Sentence-BM25 compression can remove context associated with discourse structures.
- The research team reports point estimates without complete confidence intervals.
Important points
- Harness-1 is a 20B search agent that moves search bookkeeping into the environment and leaves semantic decisions to policy.
- It achieved an average selective recall of 0.730 across eight benchmarks, outperforming the next open subagent by 11.4 points.
- Among the searchers tested, only Opus-4.6 scored higher on average curated recall.
- The gains were largest for the holdout benchmark (+17.0 vs. +7.9 points), suggesting that the learned search operations have transferred.
- Weight and harness code is public and can be provided via vLLM, SGLang, or Transformers.
Visual explanation of Marktechpost
stateful search agent
1 / 7
Please check paper, model weights and GitHub repository. Also, feel free to follow us Twitter Don’t forget to join us 150,000+ ML subreddits and subscribe our newsletter. hang on! Are you on telegram? You can now also participate by telegram.
Need to partner with us to promote your GitHub repository, Hug Face Page, product release, webinar, etc.? connect with us


