
In classic science fiction movies, AI was often depicted as towering computer systems or giant servers. Today, it is everyday technology, instantly accessible from the devices people have in their hands. Samsung Electronics is expanding its use of on-device AI across products such as smartphones and consumer electronics, enabling AI to run locally without external servers or the cloud for a faster and more secure experience.
Unlike server-based systems, on-device environments operate under severe memory and compute constraints. Therefore, it is essential to reduce the size of AI models and maximize runtime efficiency. To address this challenge, the Samsung Research AI Center is leading work across core technologies, from model compression and runtime software optimization to developing new architectures.
Samsung Newsroom sat down with Dr. MyungJoo Ham, Master of Science in AI Center at Samsung Research, to discuss the future of on-device AI and the optimization technologies that will enable it.

The first step to on-device AI
Large-scale language models (LLMs) are at the heart of generative AI that interprets the user’s language and generates natural responses. The first step to achieving on-device AI is compressing and optimizing these large models so they can run smoothly on devices such as smartphones.
“Running sophisticated models that perform billions of calculations directly on smartphones and laptops quickly drains batteries, increases heat, slows response times, and significantly degrades the user experience,” said Dr. Hamm. “Model compression technology has emerged to address these issues.”
LLM uses highly complex numerical representations to perform calculations. Model compression simplifies these values into a more efficient integer format through a process called quantization. “It’s like compressing a high-resolution photo, so the file size is smaller, but the visual quality remains roughly the same,” he explained. “For example, converting 32-bit floating point calculations to 8-bit or even 4-bit integers can significantly reduce memory usage and computational load, resulting in faster response times.”
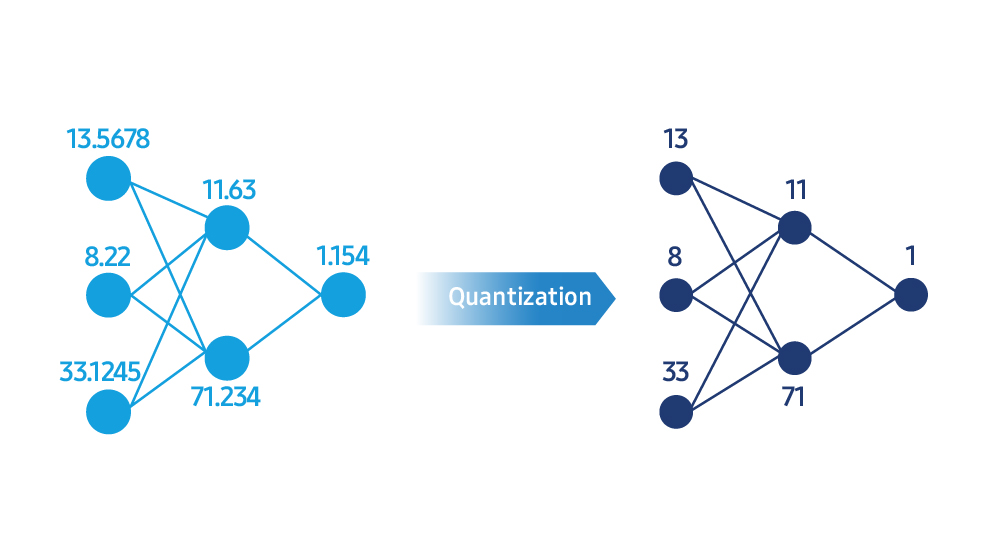
Reducing numerical precision during quantization can reduce the overall accuracy of the model. To balance speed and model quality, Samsung Research develops algorithms and tools that closely measure and tune post-compression performance.
“The goal of model compression is not just to make the model smaller, but to keep it fast and accurate,” Dr. Ham says. “We use an optimization algorithm to analyze the model’s loss function during compression, retraining the model until the output approaches the original value, and removing regions with large errors. Each model weight has a different level of importance, so we preserve important weights with greater accuracy while compressing less important weights more aggressively. This approach maximizes efficiency without sacrificing accuracy.”
Samsung Research not only develops model compression technology at the prototype stage, but also adapts and commercializes it into real products such as smartphones and home appliances. “Every device model has its own memory architecture and computing profile, so a generic approach cannot deliver cloud-level AI performance,” he said. “Through product-driven research, we are designing unique compression algorithms that enhance the AI experience that users can feel directly in their hands.”
The hidden engine that drives AI performance
Even with a well-compressed model, the user experience is ultimately determined by how it runs on the device. Samsung Research develops an AI runtime engine that optimizes how a device’s memory and computing resources are used during runtime.
“The AI runtime is essentially the engine control unit for the model,” says Dr. Hamm. “When a model runs across multiple processors, such as central processing units (CPUs), graphics processing units (GPUs), and neural processing units (NPUs), the runtime automatically assigns each operation to the best chip, minimizing memory access and improving overall AI performance.”
AI runtimes also allow you to run larger, more sophisticated models on the same device at the same speed. This not only reduces response lag, but also improves the overall quality of the AI, providing more accurate results, smoother conversations, and more sophisticated image processing.
“The biggest bottleneck for on-device AI is memory bandwidth and storage access speed,” he says. “We develop optimization techniques that intelligently balance memory and computation.” For example, loading only the data needed at a given moment, rather than keeping everything in memory, improves efficiency. “Samsung Research now has the ability to run 30 billion parameter generative models (typically 16 GB or more in size) on less than 3 GB of memory,” he added.
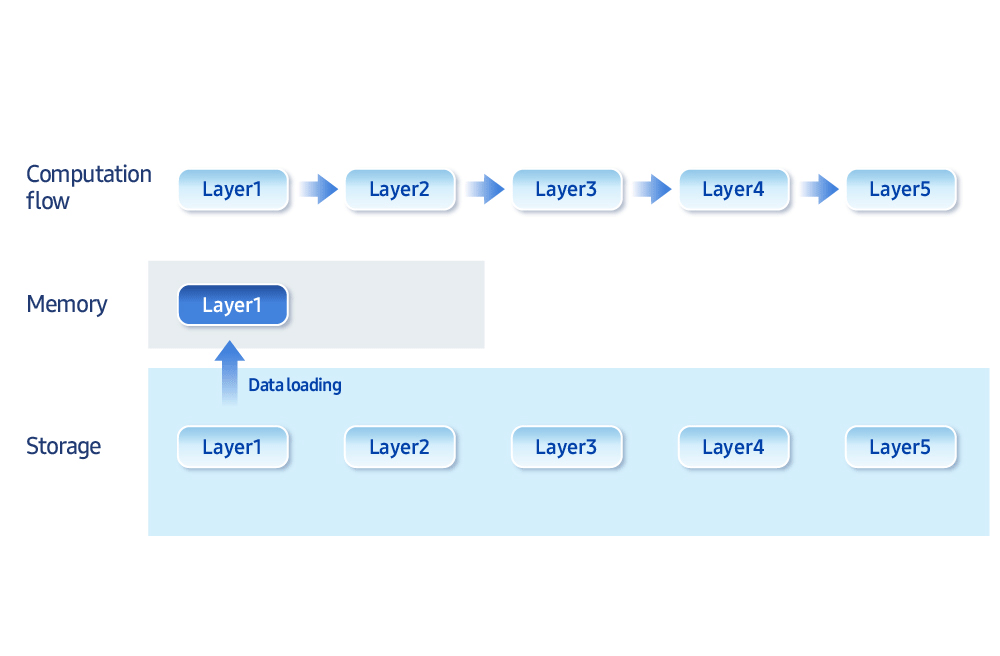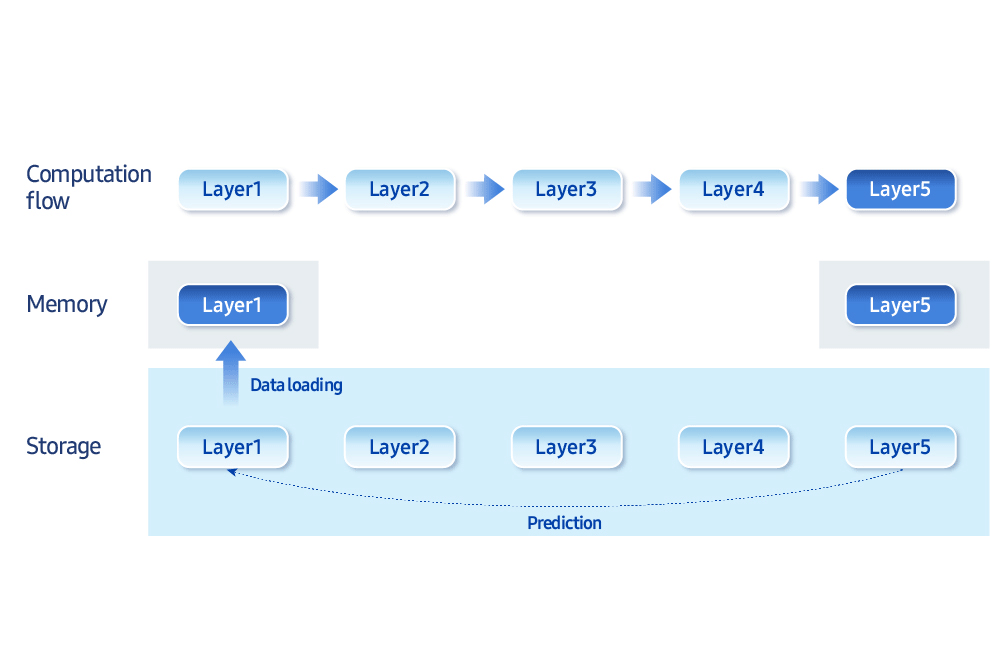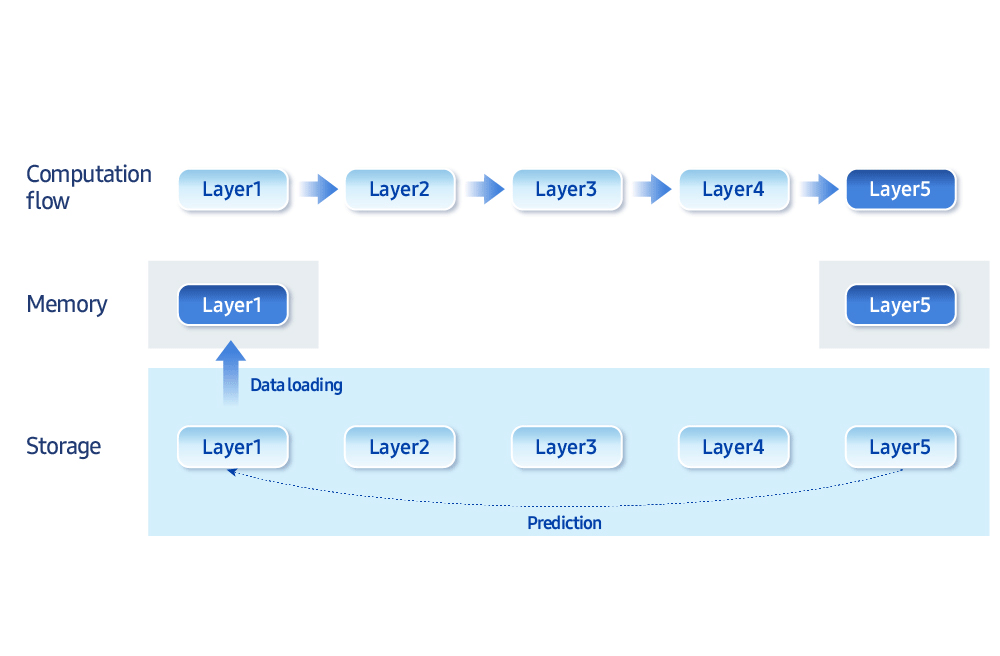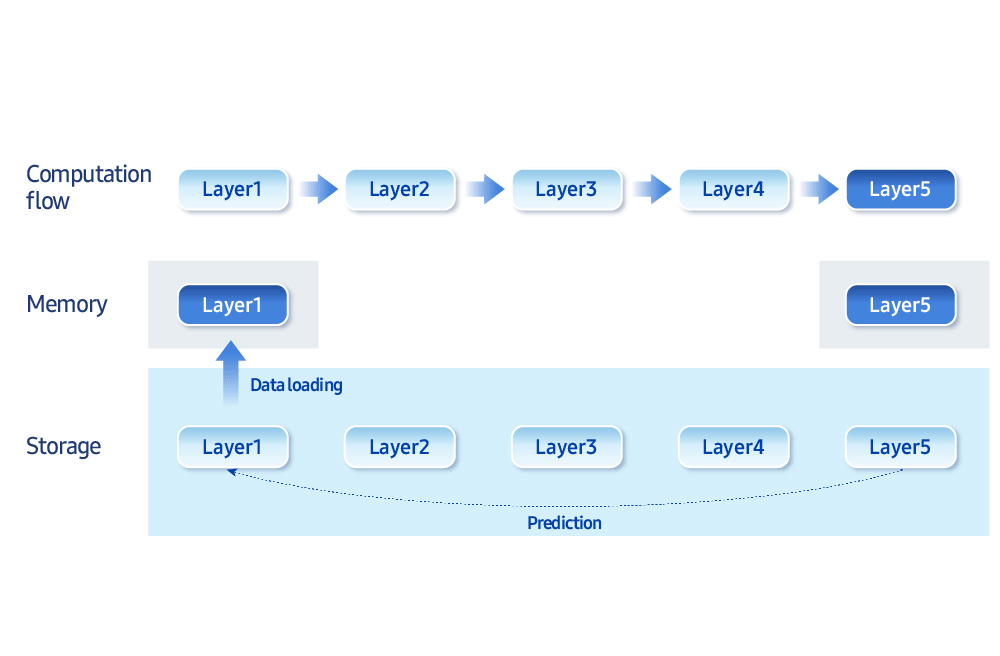
Next generation AI model architecture
Research on AI model architecture, which is the basic blueprint for AI systems, is also progressing well.
“On-device environments have limited memory and computing resources, so model structures must be redesigned to run efficiently on hardware,” Dr. Ham said. “Our architectural research is focused on creating models that maximize hardware efficiency.” In other words, the goal is to build device-friendly architectures from the ground up so that the model and device hardware work in harmony from the beginning.
Training an LLM is time-consuming and costly, and a poorly designed model structure can make that cost even higher. To minimize inefficiencies, Samsung Research proactively assesses hardware performance and designs an optimized architecture before training begins. “In the era of on-device AI, the key competitive advantage is how much efficiency can be extracted from the same hardware resources,” he said. “Our goal is to achieve the highest level of intelligence within the smallest possible chip. That is the technological direction we are pursuing.”
Currently, most LLMs rely on transformer architecture. Transformers analyze entire sentences at once to determine relationships between words. Although this method is good at understanding context, it has important limitations. In other words, the amount of calculation increases rapidly as the sentence becomes longer. “We are exploring a wide range of approaches to overcome these limitations and evaluating each approach based on how efficiently it can operate in a real device environment,” Dr. Hamm explained. “We are focused not only on improving existing methods, but also on developing next-generation architectures built on completely new methods.”
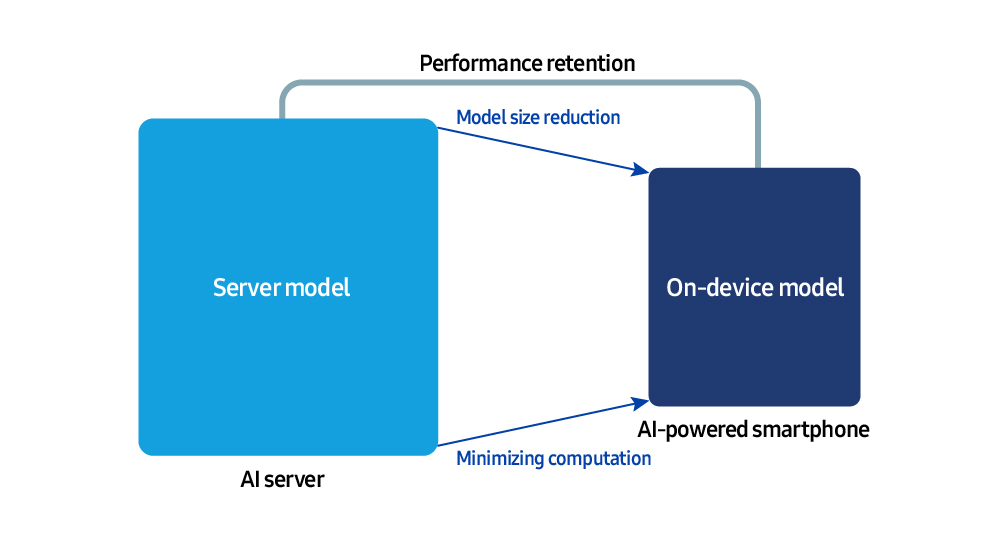
The path forward for on-device AI
What are the most important challenges for the future of on-device AI? “Achieving cloud-level performance directly on the device,” Dr. Hamm said. To make this possible, model optimization and hardware efficiency work closely together to deliver fast and accurate AI, even in the absence of network connectivity. “Improving speed, accuracy and power efficiency simultaneously will become even more important,” he added.

Advances in on-device AI now allow users to enjoy fast, secure, and highly personalized AI experiences anytime, anywhere. “AI will be better able to learn in real time on the device and adapt to each user’s environment,” Dr. Ham said. “The future lies in delivering natural, personalized services while protecting data privacy.”
Samsung leverages optimized on-device AI to push boundaries to deliver more advanced experiences. Through these efforts, we aim to provide a better and more seamless user experience.

