Author: Arthur Bajaj
Originally published on Data Tinkerer
A senior ML engineer’s perspective on operational constraints, rules and ML, and the workflow behind large-scale recommender systems.
Following up on our last post where we talked to people in the field, today we’re talking with Ahsaas Bajaj, a senior machine learning engineer at Instacart. He works on large-scale recommendation systems serving millions of customers.
We talked about his rise from software engineering to machine learning at Instacart, how he decides between rules-based and ML approaches, and how he approaches his work now as a more senior stakeholder.
So let’s get to the main topic!
Can you tell us a little about your role?
I’m a Senior ML Engineer at Instacart, responsible for the customer and shopper experience in a large-scale recommendation system that makes millions of decisions every day. For the past three years, I have led the technology strategy for Product Substitutions ML systems, with a focus on solving the out-of-stock problem.
The goal is simple. If a product is unavailable, suggest an alternative that maintains the customer’s intent and allows them to keep their order intact. My role spans system design, modeling and evaluation, balancing customer satisfaction, shopper efficiency and large-scale business impact.
How did you get started with machine learning?
My path to ML was not a straight line. I started as a software engineer on the on-device search team at Samsung Research, deep into information search and retrieval system design. That job sparked my interest in research and led me to pursue a graduate degree in computer science.
That shaped how I approach ML today. The focus is now on how the system behaves in production, rather than on the model alone. I wanted the work to actually impact users, which led me to Walmart Labs and eventually Instacart.
software engineer → data scientist → machine learning engineer → Senior ML Engineer
What does a “typical” week look like for you?
As I moved into more senior roles, the balance shifted from pure coding to a mix of execution and direction. My week usually falls into three buckets:
Alignment (30%): Glue work. I spend my time aligning product, backend engineering, and leadership with the roadmap. It’s not just a focus what we are building, whyensure that your ML work is directly tied to your business goals.
Deep work (30%): Practical modeling, coding, and system design. Staying true to the code is non-negotiable for me, even at an advanced level.
Analysis and “why” (40%): This is where I spend the most time. I dig into model errors, read live customer complaints about failed substitutions, and consider suggestions for improving sanity checks. This is also where I write my proposals. In my opinion, the most important job a senior MLE does is not just do what is assigned, but decide what problem to solve next.
How do you decide if a problem actually requires ML or if a rule-based is sufficient?
I think of it in terms of complexity and value.
If a problem can be solved deterministically using clear rules, and the rules are stable and understandable, it is often the correct solution. Machine learning is useful when the space of behavior is too large, subtle, or context-dependent to scale rules.
Good data is also a prerequisite. Without reliable signals and feedback loops, even the most sophisticated models will not perform well in production.
You wrote about your work on Instacart’s recommendation model. Could you share an overview of what you did?
For the past three years, I have led the technology development of Instacart’s product substitution system, which processes millions of redemption decisions every day. The central challenge is deceptively simple. If the product the customer requested is out of stock, what should you offer instead?
What’s interesting about this from an ML perspective is that it’s not fundamentally a search problem, it’s a relevance problem. We don’t just match product attributes, we try to understand what customers actually wanted and find alternatives that maintain that intent. This required us to rethink how we model relationships between items, define “good” alternatives, and measure success according to actual customer satisfaction.
This system has evolved significantly over time, moving from simpler heuristics to more sophisticated learned representations. But the North Star is always the same. It’s about continuing to complete orders while respecting what customers actually care about.
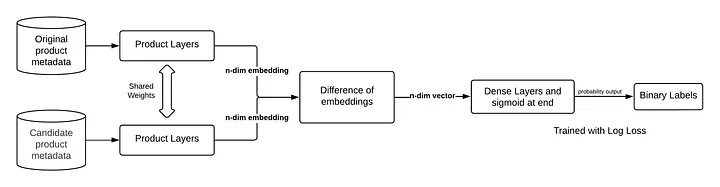
Siamese Network (Source: Instacart)

Product layer: One for the original product and one for the candidate product (Source: Instacart)
And what impact has it had on business?
Substitutes are located at critical intersections in the order lifecycle. If done well, they become invisible. The customer gets what they need and their order remains intact. When done poorly, friction is everywhere, customers rejecting products or requesting refunds, shoppers wasting time on failed offers, and orders are priced lower.
Our efforts have meaningfully moved key metrics: exchange acceptance rate, refund frequency, and what we call “complete order fulfillment rate,” which is the percentage of orders where all items were found or successfully exchanged. These improvements extend to millions of orders each week.
Beyond immediate trading metrics, we also saw positive signs in repeat order behavior and customer satisfaction scores, especially for orders that required multiple substitutes. Instacart has publicly referenced the system when discussing large-scale operational improvements.
For me, the real validation is when the customer is completely unaware of the algorithm. That’s when I just realized my groceries had arrived.
What is the ML technology stack at Instacart?
Instacart’s ML stack is built around an internal platform called Griffin, which standardizes the end-to-end ML lifecycle, from feature engineering and training to deployment and real-time inference. At its core is a shared functionality marketplace. Here, teams define, version, and reuse batch and streaming functionality with strong offline-to-online consistency.
The workflow is orchestrated with Apache Airflow, and model training is performed through a unified abstraction that supports multiple compute backends and common ML frameworks. Griffin 2.0 moves the platform to a Kubernetes-based setup and adds distributed training with Ray, significantly improving scalability and iteration speed.
Griffin also includes a centralized model registry and metadata store, making it easy to track and reproduce experiments. In production, the model is deployed as a standardized service that handles feature loading and low-latency inference across both customer and shopper experiences.
The main advantage is concentration. Teams spend less time on infrastructure and more time on modeling, evaluation, and tradeoffs.
How do you use AI in your daily work and where do you see real value in AI?
I integrated GenAI primarily to shift the focus from execution to decision-making. It’s useful for everyday tasks like scaffolding data pipelines and optimizing SQL queries, but it’s most useful when: qualitative analysis.
I regularly feed thousands of customer comments and shopper notes about unsuitable substitutes into an LLM-driven pipeline and organize the feedback into a consistent theme. What was previously unstructured noise becomes a prioritized list of failure modes. This allows you to spend less time analyzing data and more time solving the specific problems that actually impact customer trust.
How has your perspective changed as you moved into a more senior role?
The biggest change is to realize that Judgment>Code. Early in my career, I was obsessed with: how – Architecture, Libraries, Latency. What I’m obsessed with right now is what and why. The real job is filtering ideas. In a sea of seemingly good ideas, my job is to the most bullish Select one (the one with the highest ROI) and remove the others.
i learned that too Writing is engineering. One person cannot build something big. To gain buy-in from leadership and cross-functional teams, you must be able to create clear, narrative-driven proposals with explanations. why This mathematical solution solves a human problem.
What do you wish you had known earlier about machine learning?
value of error analysis. It’s easy to praise aggregate metrics like accuracy and F1, but the real breakthroughs come from studying the “horror cases” where the model is definitely wrong. These examples are unpleasant to look at, but that’s where the most useful ideas come from. You can’t fix what you don’t deeply understand.
If you enjoyed reading this, check out Ahsaas’ original article about his work at Instacart.


