
This post was co-authored with Tim Chauncey and Dheeraj Bhadani of Outpost VFX.
Training visual effects (VFX) AI models can take weeks, creating a bottleneck in production timelines. For Outpost VFX, which operates studios in the UK, Canada and India and delivers high-end film and episodic content, daily delays impact client deliverables and project schedules.
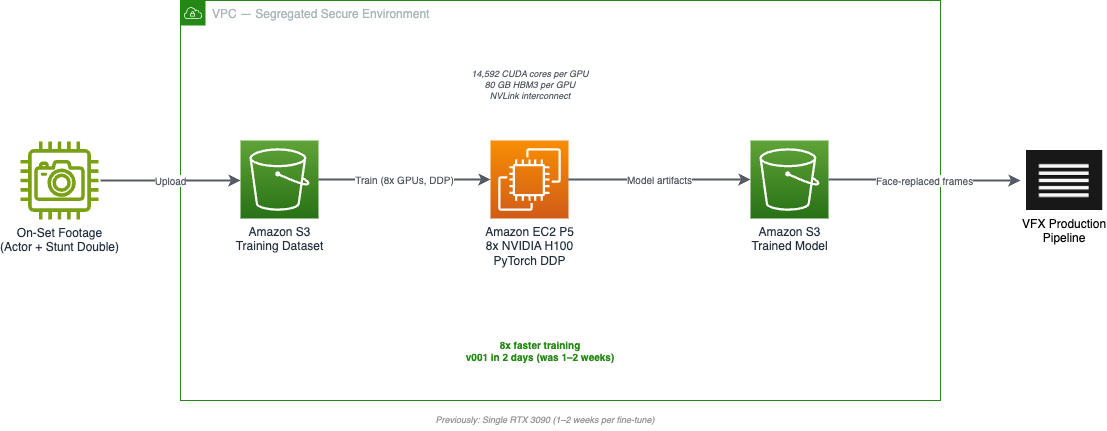
This post describes how Outpost VFX transformed its facial replacement workflow using AWS infrastructure and achieved 8x training speeds, the technical architecture implemented to overcome the limitations of a single GPU, and the measurable results achieved through AWS multi-GPU training.
The Challenge: Single GPU Bottlenecks in AI Training
Traditional facial replacement workflows in visual effects production require 5 or more days of compositing or expert cosmetic and de-aging support to create an initial version for director approval. Although effective, these methods create bottlenecks early in the iterative approval process, the most critical stage for production schedules. For VFX professionals, slow AI training directly translates into missed deadlines, increased costs, and delayed client feedback cycles.
Outpost VFX has developed an AI model that can be trained on on-set footage to accelerate the facial replacement process. However, the efficiency was limited by the computing limitations of a single GPU. Existing face swap tools can only utilize one GPU at a time, limiting access to video random access memory (VRAM) and processing power for model training operations. This prevented teams from leveraging the full potential of AI-assisted approaches.
Design considerations
Outpost VFX has identified three key technical requirements to optimize AI workflows.
- Compute scalability – The team needed to parallelize the training of the face replacement model across multiple GPUs to achieve meaningful efficiency gains. Single GPU training was introducing a one-week delay in model iteration cycles.
- Infrastructure security – Outpost VFX, an AWS customer with a fully virtualized technology stack since 2022, needed a solution that complied with strict security requirements for handling sensitive production data.
- Performance optimization – In addition to improving raw speed, the architecture needed to support larger datasets and higher resolution images to improve output quality.
To address these requirements, Outpost VFX worked with developers from the AWS Generative AI Innovation Center, which worked as an extension of its technology department, to modernize its AI learning algorithms. The AWS Generative AI Innovation Center is a team of strategists, data scientists, engineers, and solution architects who work with customers step-by-step to build tailored solutions that harness the power of generative AI. To learn more about how to collaborate with your team, visit the Generative AI Innovation Center webpage.
Architecture implementation
The solution included adapting Outpost VFX’s existing face swap model codebase to support distributed GPU training across multiple GPUs. This implementation used AWS multi-GPU Amazon Elastic Compute Cloud (Amazon EC2) P5 instances in an isolated and secure cloud environment that aligned with Outpost VFX’s existing infrastructure requirements.
Initially, Outpost VFX trained the face swap model on a GPU-accelerated workstation. This involves collecting a small dataset of actors and their stuntmen and fine-tuning the base model on an RTX 3090 GPU. Although this method worked, the Outpost team found that training times were slow, with each tweak taking about 1-2 weeks. The management overhead of these cloud workstations made scaling up difficult. At this point, they turned their attention to training on the P5 instance.
P5 instances are equipped with NVIDIA H100 GPUs purpose-built for distributed training workloads. Unlike G-series instances, which use PCIe communication between GPUs, P5 instances offer an NV link interconnect, providing significantly higher bandwidth for gradient synchronization, an important factor when training across multiple GPUs. The H100’s 14,592 CUDA cores and 80GB of high-bandwidth HBM3 memory also provided a significant upgrade over my local RTX 3090 setup.
Outpost VFX worked with the Generative AI Innovation Center to help run the model on P5 instances. Over a six-week advisory period, AWS scientists converted the model code to use the PyTorch distributed data parallel (DDP) training strategy. DDP is a parallelization technique that copies model weights to each GPU, allowing the system to process more images in each training batch. This approach increases the number of images that can be fit into each batch, directly accelerating the training process.
Technical implementation includes multi-GPU parallelization of facial replacement model training, enhanced security architecture for sensitive production data, and integration with Outpost VFX’s existing AWS-based technology stack. As Outpost VFX continues to evolve its AI pipeline, the team sees potential in services like Amazon SageMaker AI with managed training, model versioning, and hosted inference to further streamline model development and deployment across its global studio.
Measure performance improvements
To test the speedup of multi-GPU training, Outpost VFX collected an image dataset for training, modified the model’s hyperparameters, and measured the time it took for training to reach a certain loss threshold. Set the baseline as one GPU on a G5 instance compared to running the model on a P5 instance.
A joint development effort between Outpost VFX and AWS improves the training speed of facial replacement models by up to 8x. This performance improvement translates directly into faster iteration cycles, allowing for a faster approval process for early versions of Directors. The ability to train models on high-resolution images and large datasets has improved output quality. Most importantly, it now takes two days to deliver v001 to a client for initial review, instead of the one to two weeks it used to take.
“Thanks to our parallelized workflow and the ability to leverage multiple top-end GPUs simultaneously, we can now significantly speed up our iterations.” Tim Chauncey, CTO of Outpost VFX, explains: “Speed of iteration is critical for VFX work, and this architecture provides more robust and scalable capabilities for future development.”
Future improvements may include improving the quality of image output. Outpost can process these larger images and larger datasets by increasing the image resolution passed to the model and using new generation Amazon EC2 P5 instances with more VRAM.
conclusion
The AWS-optimized architecture allows Outpost VFX to provide clients with enhanced AI-assisted facial replacement capabilities while maintaining the security and scalability requirements of high-end visual effects production. A parallelized workflow architecture, including migration from local consumer NVIDIA GPUs to enterprise NVIDIA GPUs, provides the foundation for future AI tool development and scaling across Outpost VFX global studio operations.
“What excites me most is that these models are no longer research experiments, but are becoming an integral part of the modern VFX pipeline.” Dheeraj Bhadani, Lead Software Architect at Outpost VFX said: “Multi-GPU acceleration is the foundation on which the next generation of creative tools will be built.”
next step
If you want to accelerate your own AI training workflow, consider the following steps.
- Evaluate current GPU utilization: Identify whether single GPU constraints are limiting training performance.
- Explore multi-GPU architectures: Amazon EC2 P5 instances provide scalable compute for distributed training workloads.
- Work with the AWS Generative AI Innovation Center: the same team that helped parallelize Outpost VFX’s training workflows
Similar results can be achieved by implementing a distributed training strategy tailored to your specific use case and infrastructure requirements.
Acknowledgment
The authors would like to thank the following contributors for supporting this project: Thanks to Josh Chappatte, Laksh Puri, and Ruchi Bhatia.
About the author


